简体中文 | 繁體中文(待)
本次实验使用的数据皆来自作者自身设备
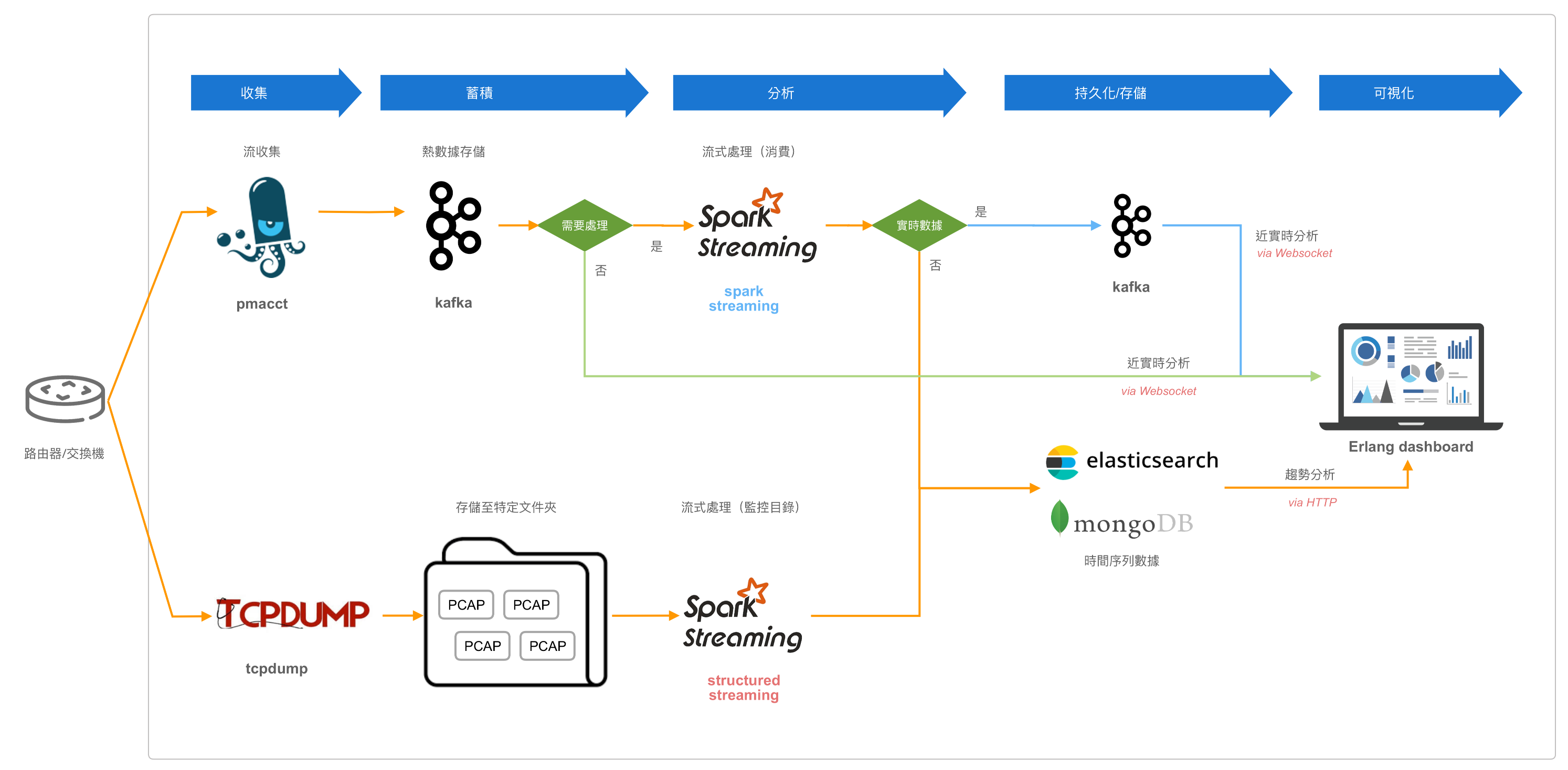
运用 Apache Spark Streaming (Structured Streaming) 分析网络流量,并输出至前端 Dashboard 展示
实验从两个面向对数据进行分析和处理:
- 运用 pmacct 监控网络流量,将数据保存至 Kafka 中。
- 使用 ==Saprk Streaming== 消费 Kafka 的数据,最后根据需求
- 热数据:写入新的 Kafka Topic 中
- 冷数据:写入 MongoDB 或 Elasticsearch 中
- 前端展示
- Kafka 数据通过 Websocket 与前台通信
- MongoDB, Elasticsearch 通过 Http 请求与前台通信
- 使用 tcpdump 将截取到的报文输出成 pcap 文件并保存到特定文件夹下
- 使用 ==Structured Streaming== 监控目录中的所有文件,将数据持久化至 MongoDB, Elasticsearch 中
- 前端展示:MongoDB, Elasticsearch 通过 Http 请求与前台通信
- pmacct
- 用途:作为网络流量监视工具。使用 libpcap 进行采集后将数据导出至 Kafka。
- 优点:
- 开源免费软件包,多种被动网络监视功能工具集,可以实现分类、聚合、复制、导出网络流量数据
- 支持 Linux, BSDs, Solaris 等
- 可以采集 libpcap, Netlink/NFLOG, NetFlow v1/v5/v7/v8/v9, sFlow v2/v4/v5 和 IPFIX。
- 可以导出到关系型数据库、NoSQL 数据库、RabbitMQ、Kafka、内存表、文件。
- Apache Kafka
- 用途:作为消息系统。保存由 pmacct 采集到的流量信息,并作为 Saprk Streaming 的数据源。
- 优点:
- 可靠性:分区机制、副本机制和容错机制
- 可扩展性:支持集群规模的热扩展
- 高性能:保证数据的高吞吐量
- Apache Spark Streaming
- 用途:接收实时流的数据,并根据一定的时间间隔拆分成一批批的数据,然后通过 Spark Engine 处理这些批数据。根据需求将结果输出至 Kafka 中或持久化到数据库中。
- 编程模型:DStream 作为 Spark Streaming 的基础抽象,它代表持续性的数据流。这些数据流既可以通过外部输入源赖获取,也可以通过现有的 Dstream 的 transformation 操作来获得。在内部实现上,DStream 由一组时间序列上连续的 RDD 来表示。每个 RDD 都包含了自己特定时间间隔内的数据流。
- Websocket
- 用途:客户端与服务器端的持久连接。
- 优点:由于部分数据需要实时传递给前端,而 HTTP 是非状态性的,每次都要重新传输;Websocket 只需要一次 HTTP 握手,整个通讯过程是建立在一次连接/状态中,避免了 HTTP 的非状态性,服务端会一直知道客户端信息,直到关闭请求。
- 编写 pmacctd configuration 文件(pmacct 环境搭建在附录给出)
- example
# pmacctd.conf
# 聚合规则
aggregate: src_mac, dst_mac, vlan, cos, etype, src_as, dst_as, peer_src_ip, peer_dst_ip, in_iface, out_iface, src_host, src_net, dst_host, dst_net, src_mask, dst_mask, src_port, dst_port, tcpflags, proto, tos, sampling_rate, timestamp_start, timestamp_end, timestamp_arrival
# 过滤(用法规则与 tcpdump 相同)
# pcap_filter: src net 10.0.0.0/16
plugins: kafka #插件名
kafka_output: json #输出格式
kafka_topic: netflow # Kafka Topic名
kafka_refresh_time: 10 # 聚合10秒钟流量数据
# Kafka broker 信息
kafka_broker_host: 127.0.0.1
kafka_broker_port: 9092
- 运行
sudo pmacctd -f /path/to/config/file
(-f 表示读取来自文件 的configuration) - 运行画面
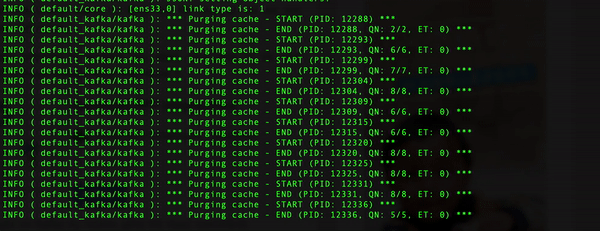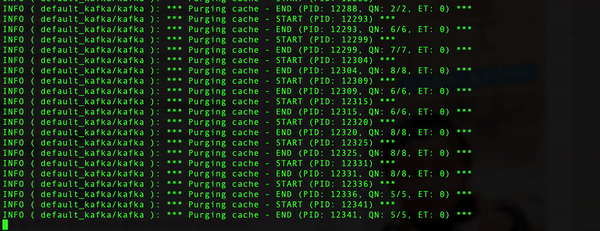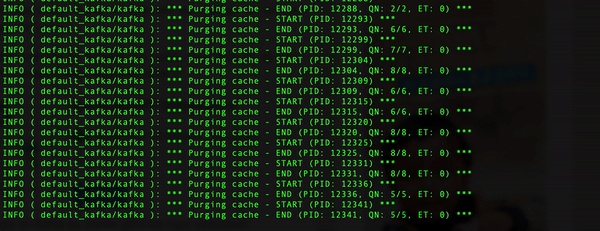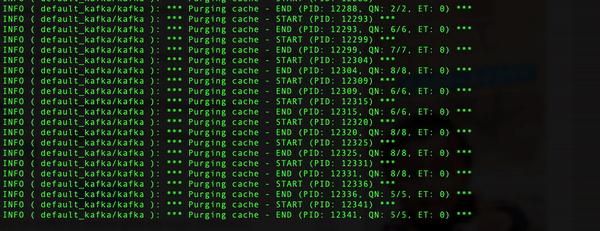
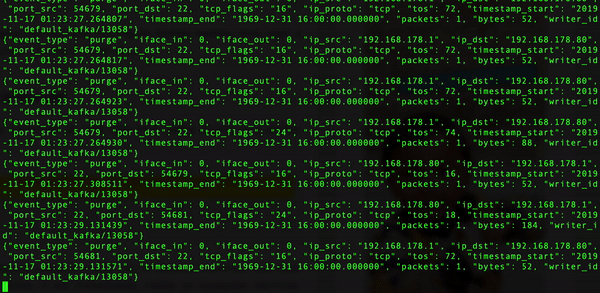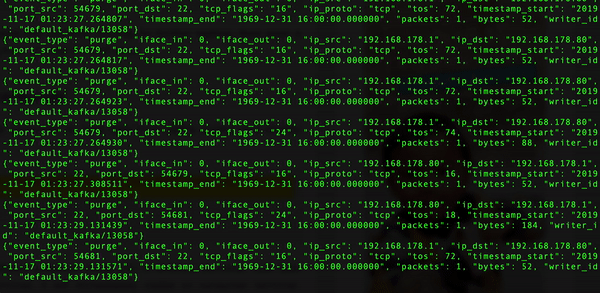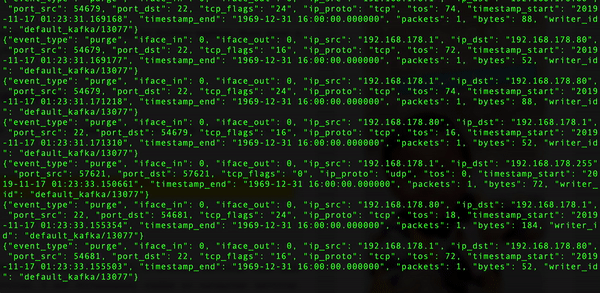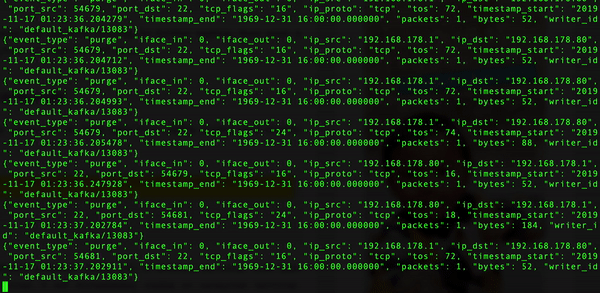
- 查看 Kafka Consumer
- Spark Streaming 接入 Kafka
- 初始化
from pyspark import SparkContext, SparkConf
from pyspark.streaming import StreamingContext
from pyspark.streaming.kafka import KafkaUtils
import json
import pymongo
# 创建 Spark 上下文
conf = SparkConf().setAppName("kafkaSparkStreaming").setMaster("spark://localhost:7077")
sc = SparkContext().getOrCreate(conf=conf)
ssc = StreamingContext(sc, 2)
# ...省略配置代码
# 使用高阶api接受数据(Receiver-based Approach)
# kafkaStream = KafkaUtils.createStream(streamingContext, [ZK quorum], [consumer group id], [per-topic number of Kafka partitions to consume])
kafkaStream = KafkaUtils.createStream(ssc, zookeeper, "group-a", {topic: 1})
- 原数据格式
(None, '{"event_type": "purge", "iface_in": 0, "iface_out": 0, "ip_src": "192.168.178.80", "ip_dst": "192.168.178.1", "port_src": 22, "port_dst": 58608, "tcp_flags": "24", "ip_proto": "tcp", "tos": 18, "timestamp_start": "2019-11-11 06:18:00.043547", "timestamp_end": "1969-12-31 16:00:00.000000", "timestamp_arrival": "2019-11-11 06:18:00.043547", "packets": 1, "bytes": 168, "writer_id": "default_kafka/9190"}')
- 获取目标数据
targets = kafkaStream.map(lambda data: data[1])
- 整理成需要的格式
截取原 ip、目标 ip、事件类型、报文数、字节数、协议、时间戳、原端口以及目标端口
def mapper(record):
record = json.loads(record)
res = {}
res["ip_src"] = record.get("ip_src")
res['ip_dst'] = record.get('ip_dst')
res['event_type'] = record.get('event_type')
res['packets'] = record.get('packets')
res['bytes'] = record.get('bytes')
res['protocol'] = record.get('ip_proto')
res['timestamp'] = record.get('timestamp_start')
res['port_src'] = record.get('port_src')
res['port_dst'] = record.get('port_dst')
return res
- 持久化至 MongoDB
- 通常,创建一个连接对象有资源和时间的开支。因此为每个记录创建和销毁连接对象会导致非常高的开支,明显的减少系统的整体吞吐量。一个更好的解决办法是利用rdd.foreachPartition方法。 为 RDD 的 partition 创建一个连接对象,用这个连接对象发送 partition 中的所有记录。
def sendMongoDB(partition):
# 初始化 mongo
client = pymongo.MongoClient("mongodb://localhost:27017/")
db = client['kafka-netflow']
collection_name = 'netflow'
collection = db[collection_name]
for record in partition:
collection.insert_one(record)
client.close()
- Transformation 操作
# 整理数据格式
process = targets.map(mapper)
# 持久化至 MongoDB
process.foreachRDD(lambda rdd: rdd.foreachPartition(sendMongoDB))
- MongoDB 中的数据
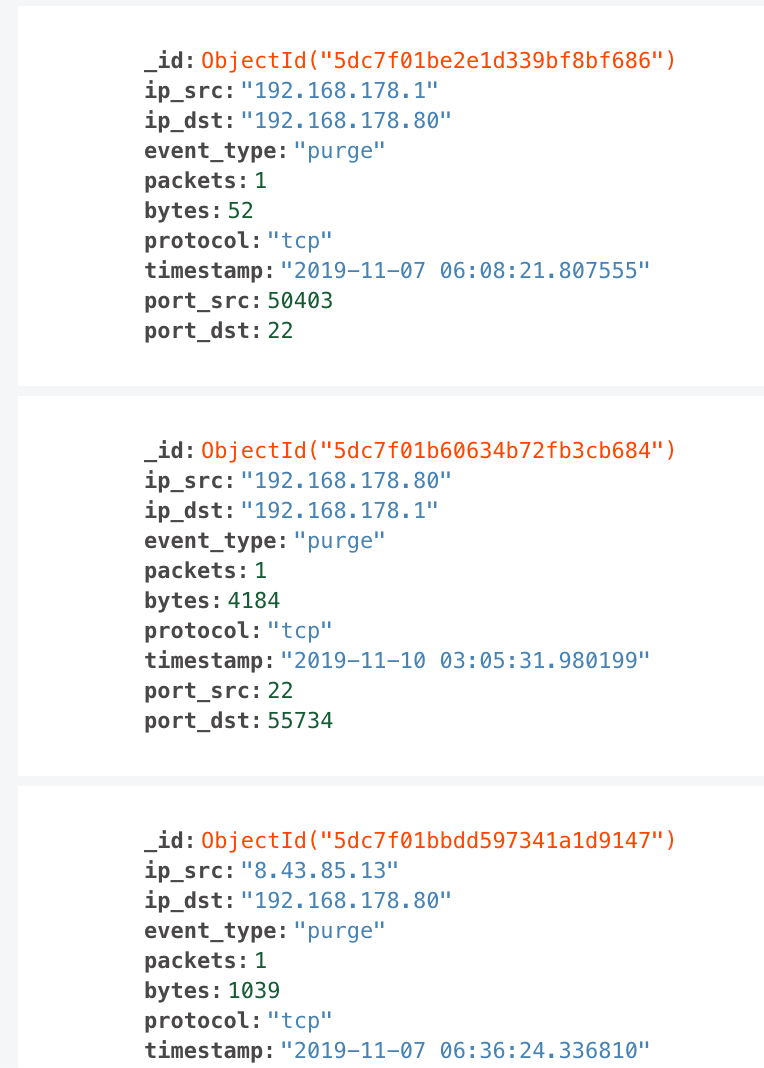
- 输出至新的 Kafka Topic
- 初始化
from kafka import KafkaProducer
producer = KafkaProducer(
bootstrap_servers=['127.0.0.1:9092'],
linger_ms=1000,
batch_size=1000,
)
def sendKafka(message):
records = message.collect()
for record in records:
producer.send('newTopic', str(record).encode())
producer.flush()
- Transformation 操作
# 整理数据格式
process = targets.map(mapper)
# 输出至 Kafka
process.foreachRDD(sendKafka)
- 问题:此方法似乎只能在 local 上运行,在集群上会报错。待解决。
- tcpdump
- 用途:网络抓包,并将结果输出成 pcap 文件。
- 介绍:可以将网络中传送的数据包的报文头完全截获下来提供分析,支持针对网络层、协议、主机、网络或端口的过滤,并提供and, or, not等逻辑语句来帮助用户去掉无用的信息。
- Apache Structured Streaming
- 用途:监控存放 pcap 文件的目录,并流式处理其中数据,最后将处理后的结果持久化至 MongoDB 或 Elasticsearch 中。
- 优点:
- Incremental query model:Structured Streaming 将会在新增的流式数据上不断执行增量查询,同时代码的写法和批处理 API (基于 Dataframe 和 Dataset API)完全一样。
- 复用 Spark SQL 执行引擎:Spark SQL 执行引擎做了非常多的优化工作,例如执行计划优化、codegen、内存管理等。使得 Structured Streaming 有高性能和高吞吐的能力。不同于 Spark Streaming 是基于 RDD 操作。
tcpdump 收集网络流量,example:
tcpdump -s 0 port -i eth0 -w mycap.pcap
其中,
-s 0:会将捕获字节设置为最大,即 65535,此捕获文件将不会被截断。
-i eth0:用于提供要捕获的以太网接口。 如果不使用此选项,则默认值为 eth0。
-w mypcap.pcap 将创建该 pcap 文件,该文件可以使用 wireshark 打开。
由于 pcap 是二进制文件,目前还没找到比较理想的方式让 Spark 来读取,所以现在先用 tshark 将 pcap 文件转换成 json 格式,再作为 Structured Streaming 的数据源。
- 初始化
from pyspark.sql import SparkSession
from pyspark import SparkConf,SparkContext
conf = SparkConf().setAppName("LogAnalysisStructuredStream").setMaster('spark://127.0.0.1:7077')
spark = SparkSession \
.builder \
.appName("LogAnalysisStructuredStream") \
.config(conf=conf) \
.getOrCreate()
- 指定目标目录并设定 schema
streamingDF = (
spark
.readStream
.schema(schema)
.option("maxFilesPerTrigger", 1)
.option(......)
.json('./data', multiLine=True) # 待处理文件目录
)
其中,option 参数
path: 输入路径,适用所有格式
maxFilesPerTrigger: 每次触发时,最大新文件数(默认:无最大)
latestFirst: 是否首先处理最新的文件,当有大量积压的文件时,有用(默认值:false)
fileNameOnly: 是否仅根据文件名而不是完整路径检查新文件(默认值:false)。
- 使用自定义函数将
timestamp: string转换成TimestampType,并整理出需要的信息。Structured Streaming 的优势是可以使用 Spark SQL 的语法对数据进行处理
from pyspark.sql.types import TimestampType
from pyspark.sql.functions import udf
timestamp_convert = udf (lambda time: datetime.float(time), TimestampType())
streamingDF = streamingDF.withColumn("datetime", timestamp_convert(streamingDF['_source']['layers']['frame']['frame.time_epoch']))
只截取部分信息:
streamingDF = streamingDF.select(
streamingDF['_source']['layers']['ip']['ip.dst'].alias('ip_dst'), \
streamingDF['_source']['layers']['ip']['ip.src'].alias('ip_src'), \
streamingDF['_source']['layers']['ip']['ip.version'].alias('ip_ver'), \
streamingDF['_source']['layers']['frame']['frame.time_epoch'].alias('timestamp'), \
streamingDF['_source']['layers']['tcp']['tcp.dstport'].alias('tcp_dstport'), \
streamingDF['_source']['layers']['tcp']['tcp.flags'].alias('tcp_flags'), \
streamingDF['_source']['layers']['tcp']['tcp.srcport'].alias('tcp_srcport'),
)
处理过后的 schema
# input:
streamingDF.printSchema()
# output:
root
|-- ip_dst: string (nullable = true)
|-- ip_src: string (nullable = true)
|-- ip_ver: string (nullable = true)
|-- timestamp: string (nullable = true)
|-- tcp_dstport: string (nullable = true)
|-- tcp_flags: string (nullable = true)
|-- tcp_srcport: string (nullable = true)
- 持久化至 MongoDB
from pymongo import MongoClient
def write2mongo(row):
client = MongoClient('localhost', 27017)
db = client['structured-stream']
collectionName = 'netflow'
collection = db[collectionName]
collection.insert_one({"ip_dst": row[0], "ip_src": row[1], "ip_ver": row[2], "timestamp": row[3], "tcp_dstport": row[4], "tcp_flags": row[5], "tcp_srcport": row[6]})
开始运行
streamingDF.writeStream.foreach(write2mongo)\
.outputMode("append") \
.trigger(processingTime='10 seconds') \
.start()\
.awaitTermination()
其中
-
trigger 有几种模式
流查询的 trigger 设置定义了流数据处理的时间,无论该查询是作为具有固定批处理间隔的微批查询,还是作为连续处理查询执行。 以下是受支持的各种触发器:- 固定间隔微批:查询将以微批次模式执行,在该模式下,微批次将按用户指定的时间间隔启动。
- One-time micro-batch:将仅执行一个微批处理来处理所有可用数据,然后自行停止。
- Continuous with fixed checkpoint interval :查询将以新的低延迟,连续处理模式执行。
-
output 有几种模式
Complete mode: Result Table 全量输出
Append mode (预设值): 只有 Result Table 中新增的行才会被输出,所谓新增是指自上一次 trigger 的时候。因为只是输出新增的行,所以如果老数据有改动就不适合使用这种模式。
Update mode: 只要更新的 Row 都会被输出,相当于 Append mode 的加强版。
- MongoDB 的数据
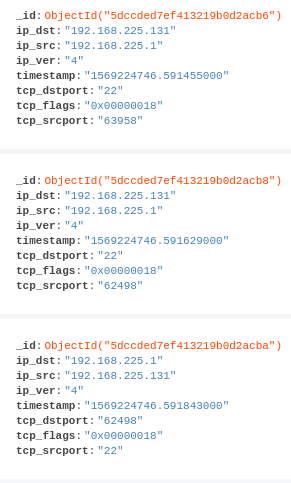
- 前端框架:React.js
- 后端框架:Express.js
- 可视化库:ECharts
- UI 库:Semantic UI
- Websocket:
- 用途:让 server 将最新的数据以最快的速度发送给 client
- 介绍:WebSocket 是一种协议,是一种与 HTTP 同等的网络协议,两者都是应用层协议,基于 TCP。但是 WebSocket 是一种双向通信协议,在建立连接之后,WebSocket 的 server 与 client 都能主动向对方发送或接收数据。同时 WebSocket 在建立连接时需要借助 HTTP 协议,连接建立好了之后 client 与 server 之间的双向通信就与 HTTP 无关了。
- Socket.IO:是一个封装了 Websocket、基于 Node 的 JavaScript 框架,包含 client 的 JavaScript 和 server 的 Node。当 Socket.IO 检测到当前环境不支持 WebSocket 时,能够自动地选择最佳的方式来实现网络的实时通信。
本次前端绘制两张图表,创建了两个服务器,一个用于处理 HTTP 请求;一个使用 Websocket 与前端通信:
- Date Access Trend:
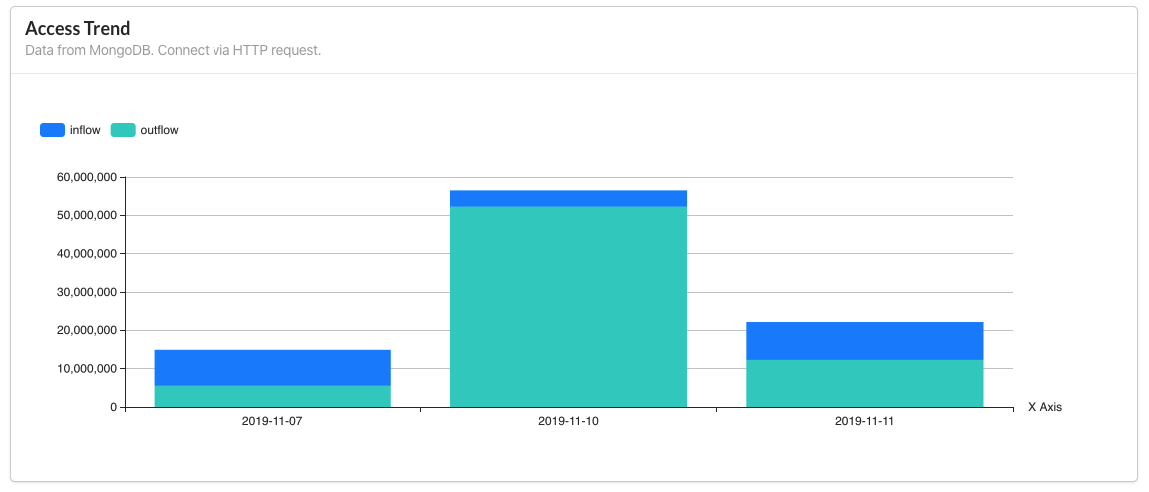
数据源是 MongoDB,依据日期统计当天的 inflow 和 outflow 数量(bytes),采用 HTTP 发送请求至后端获取数据,以叠加柱状图呈现。 - Real Time Access Trend:
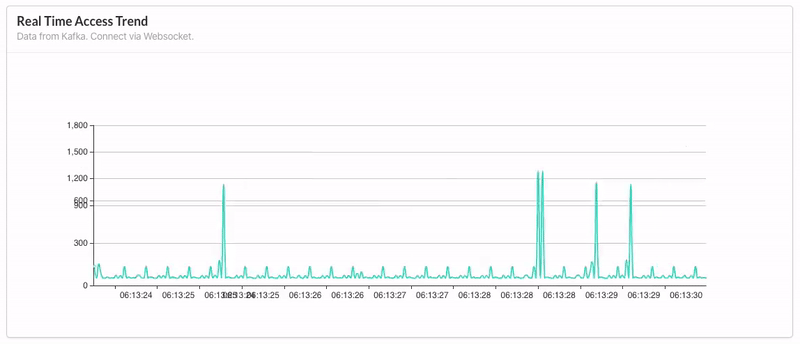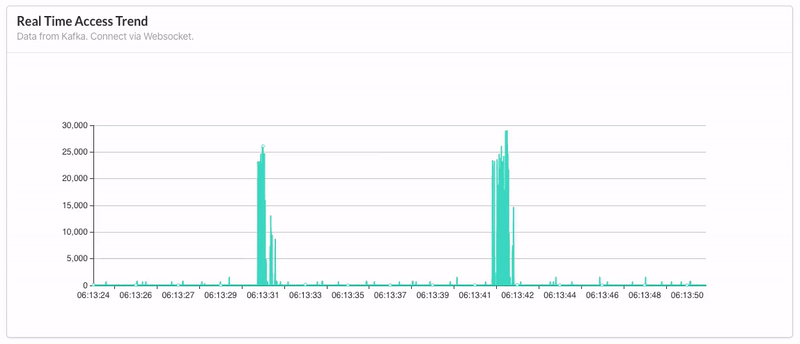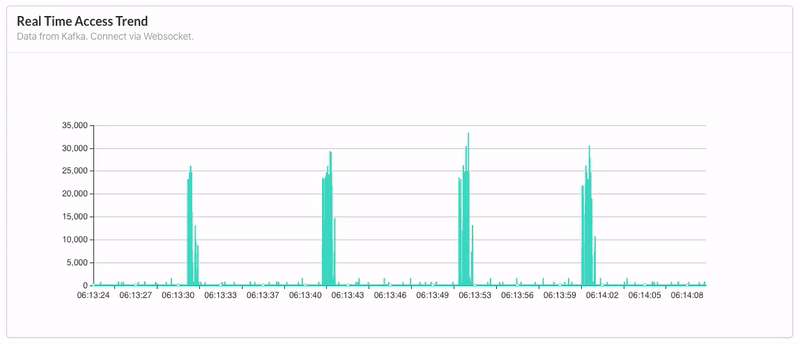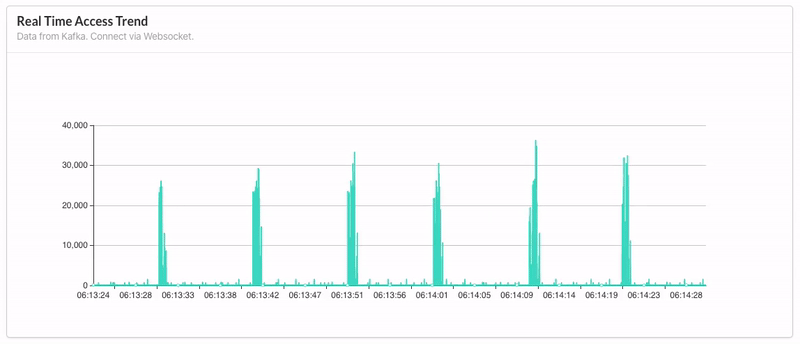
据源是 Kafka,前端通过 Websocket 实时获取后端消费 Kafka 的数据,每十秒更新一次,以动态折线图呈现。
- 原始数据 example:
_id: 5dc7f01be2e1d339bf8bf686
ip_src: "192.168.178.1"
ip_dst: "192.168.178.80"
event_type: "purge"
packets: 1
bytes: 52
protocol: "tcp"
timestamp: "2019-11-07 06:08:21.807555"
port_src: 50403
port_dst: 22
- 聚合
- 欲使用之数据格式:
{
'_id': '日期',
'inBytes': '流入bytes数',
'inPackets': '流入packets数',
'outBytes': '流出bytes数',
'outPackets': '流出packets数'
}
- Mongo Aggregation pipeline:
其中192.168.178.80为主机 IP
[
{
'$match': {
'timestamp': {
'$gte': '2019-11-05',
'$lte': '2019-11-15'
}
}
}, {
'$project': {
'day': {
'$substr': [
'$timestamp', 0, 10
]
},
'inBytes': {
'$cond': {
'if': {
'$eq': [
'192.168.178.80', '$ip_dst'
]
},
'then': '$bytes',
'else': 0
}
},
'outBytes': {
'$cond': {
'if': {
'$eq': [
'192.168.178.80', '$ip_src'
]
},
'then': '$bytes',
'else': 0
}
},
'inPackets': {
'$cond': {
'if': {
'$eq': [
'192.168.178.80', '$ip_dst'
]
},
'then': '$packets',
'else': 0
}
},
'outPackets': {
'$cond': {
'if': {
'$eq': [
'192.168.178.80', '$ip_src'
]
},
'then': '$packets',
'else': 0
}
}
}
}, {
'$group': {
'_id': '$day',
'inBytes': {
'$sum': '$inBytes'
},
'inPackets': {
'$sum': '$inPackets'
},
'outPackets': {
'$sum': '$outPackets'
},
'outBytes': {
'$sum': '$outBytes'
}
}
}
]
- 创建 HTTP Server:
const express = require('express')
const http = require('http')
const app = express()
const server = http.createServer(app)
const port = 3001 //端口号
server.listen(port, () => console.log(`Listening on port ${port}`))
- Kafka 单个消费者,使用到
kafka-nodepackage(适用于 Apache Kafka 0.9 或之后的版本)
const kafka = require('kafka-node');
const Consumer = kafka.Consumer;
const client = new kafka.KafkaClient({
// broker
kafkaHost: '192.168.178.80:9092'
});
const consumer = new Consumer(
client,
[{
topic: "realTimeChart",
fromOffset: 'latest' // 消费partition中最新的数据
}], {
autoCommit: true // 自动提交偏移量
}
)
- Websocket Server(使用 Socket.IO)
const socketIO = require('socket.io')
const io = socketIO(server)
io.on('connection', socket => {
console.log('User connected')
socket.on('disconnect', () => {
console.log('user disconnected')
})
consumer.on('message', (message) => {
const netFlowMag = JSON.parse(message.value);
const res = {
time: netFlowMag.timestamp_arrival.substring(11,19),
bytes: netFlowMag.bytes
}
socket.emit('broad', res);
})
})
其中,消费出的数据范例:
{ topic: 'realTimeChart',
value:
'{"event_type": "purge", "iface_in": 0, "iface_out": 0, "ip_src": "192.168.178.1", "ip_dst": "192.168.178.80", "port_src": 62894, "port_dst": 9092, "tcp_flags": "16", "ip_proto": "tcp", "tos": 0, "timestamp_start": "2019-11-17 06:08:32.453958", "timestamp_end": "1969-12-31 16:00:00.000000", "timestamp_arrival": "2019-11-17 06:08:32.453958", "packets": 1, "bytes": 52, "writer_id": "default_kafka/56419"}',
offset: 542178,
partition: 0,
highWaterOffset: 542179,
key: null }
需要的是其中的 value 属性,并返回 value 中的 bytes。
- Websocket Client(使用 Socket.IO Client)
React 关键代码:
state = {
response: 0,
endpoint: "http://127.0.0.1:3001", //server地址
label: [],
value: []
};
componentDidMount() {
const { endpoint } = this.state;
const socket = socketIOClient(endpoint);
socket.on("broad", data => {
// 将数据append并更新至state
this.setState({label: [...this.state.label, data.time]});
this.setState({value: [...this.state.value, data.bytes]});
});
}
- 安装 libpcap-dev
$ sudo apt-get install libpcap-dev - 安装 librdkafka
$ git clone https://github.com/edenhill/librdkafka.git
$ cd librdkafka
$ ./configure
$ make
$ make install
- 安装 libjansson-dev
$ apt-get install libpcap-dev libjansson-dev - 安装带有选项的 pmacct 以使用 kafka
- 安装依赖
$ apt-get install pkg-config libtool autoconf automake bash - Build GitHub code:
- 安装依赖
$ git clone https://github.com/pmacct/pmacct.git
$ cd pmacct
$ ./autogen.sh
$ ./configure --enable-kafka --enable-jansson --enable-ipv6
$ make
$ make install [with super-user permission]
- 确认
$ pmacctd -V, output:
Promiscuous Mode Accounting Daemon, pmacctd 1.7.4-git (20191031-00)
Arguments:
'--enable-kafka' '--enable-jansson' '--enable-ipv6' '--enable-l2' '--enable-64bit' '--enable-traffic-bins' '--enable-bgp-bins' '--enable-bmp-bins' '--enable-st-bins'
Libs:
libpcap version 1.8.1
rdkafka 1.2.2-RC1-1-g8d44dd-dirty
jansson 2.11
System:
Linux 4.15.0-20-generic #21-Ubuntu SMP Tue Apr 24 06:16:15 UTC 2018 x86_64
Compiler:
gcc 7.4.0
For suggestions, critics, bugs, contact me: Paolo Lucente <paolo@pmacct.net>.