Ao se trabalhar com Machine Learning, podemos nos deparar com modelos com um grande número de atributos. E geralmente é isso que ocorre com datasets do mundo real. Para isso, pode ser necessário a redução de dimensionalidade para ganho de eficiência computacional, ou até para visualizar o resultado na forma de um gráfico. Duas técnicas comuns para isso são o PCA e o t-SNE.
É definido como um método linear não-paramétrico para redução de dimensionalidade em problemas de aprendizado não supervisionado
A ideia do PCA é reduzir a dimensionalidade perdendo o mínimo de informação. Ele busca, então, manter o máximo possível da variabilidade presente no dataset original. Para isso, são criadas novas variáveis a partir das features originais, que são ordenadas de acordo com quanto de variação cada uma consegue explicar. Esses novos componentes criados são completamente não relacionados (ou seja, são ortogonais entre si).
O primeiro componente apresenta a maior variação, seguido do segundo, e assim por diante. Desse modo, como poucos componentes retêm a maior parte da explicação da variação, é possível visualizar e sintetizar as características de datasets com dimensões altas em um espaço de mais baixa dimensão.
O PCA busca preservar a estrutura global do dataset formando clusters bem divididos, mas pode acabar não sendo muito eficiente para preservar as similaridades dentro de um cluster. Além disso, por ser um método linear, trabalha melhor com datasets com características lineares e pode ser útil para achar padrões nesses datasets.
Na prática, são construídas novas variáveis a partir dos atributos originais, que são uma combinação linear desses atributos.
Uma combinação linear nada mais é do que a representação de um vetor a partir de operações com outros vetores. Assim, dado um conjunto de vetores
Dado um dataset n-dimensional, é computada uma matriz de covariância (também conhecida como matriz de variância-covariância) para todo o conjunto de dados, gerando uma matriz quadrada
Entrando agora um pouco mais na álgebra linear, temos os conceitos de autovalores e autovetores.
Autovetor: vetor cuja direção permanece constante quando uma transformação linear é aplicada a ele (
Autovalor: indica quanto o vetor irá "encolher" ou "esticar" ao sofrer a transformação (
Os autovalores podem ser calculados como raízes da seguinte fórmula, onde A é uma matriz quadrada:
Para os autovetores relacionados aos autovalores encontrados, basta substituir na fórmula:
Aplica-se então essa fórmula, sendo A a nossa matriz de covariância. Os autovetores encontrados formarão os eixos do novo espaço de dimensões. Mas como os autovetores só nos fornecem a direção, precisamos olhar também para os autovalores. Os autovetores com os maiores autovalores são aqueles que fornecem a maior quantidade de informação sobre o dataset.
A ideia é que os autovetores representam o peso de cada variável original sobre cada componente. Já o autovalor é uma indicação direta da importância do componente na explicação da variação total dentro do conjunto de dados.
Para formar a matriz final dos compontentes, então, ordenam-se os autovetores por autovalores decrescentes e escolhem-se k autovetores com os maiores autovalores. A matriz formada (W) tem dimensões

- É necessário tratar valores nulos e normalizar/padronizar as variáveis antes do PCA
- Pode não funcionar bem para datasets não lineares

Exemplo de visualização com PCA para 2 componentes Fonte: https://towardsdatascience.com/principal-component-analysis-pca-explained-visually-with-zero-math-1cbf392b9e7d
Método não-linear para redução de dimensionalidade em problemas de aprendizado não supervisionado
Principal objetivo: visualizar os dados numa dimensão mais baixa (geralmente 2D)
Para preservar a estrutura dos dados na dimensão original, é definida uma similaridade condicional entre dois pontos, onde
A divisão serve para lidar com cluster com diferentes densidades. É uma espécie de normalização.
Versão simetrizada da similaridade condicional (joint probability condition, ou distribuição de probabilidade conjunta):
Com isso, obtemos uma matriz de similaridade para o dataset original, computando a similaridade para cada ponto. Além disso, define-se uma matriz de similaridade também para os pontos mapeados:
Aqui, a distribuição muda para t-Student com um grau de liberdade, ou distribuição Cauchy.
O objetivo é que essas matrizes sejam o mais próximas possível. Assim, significa que os pontos do dataset original produzem pontos mapeados similares.
Tem-se que a similaridade será dada por
Matematicamente, isso significa minimizar a divergência de Kullback-Leiber entre as duas distribuições (
Performa-se o gradiente descendente nessa equação, a fim de minimizá-la.
Para um problema usual envolvendo uma bola N-dimensional, o volume dessa bola de raio r escala como
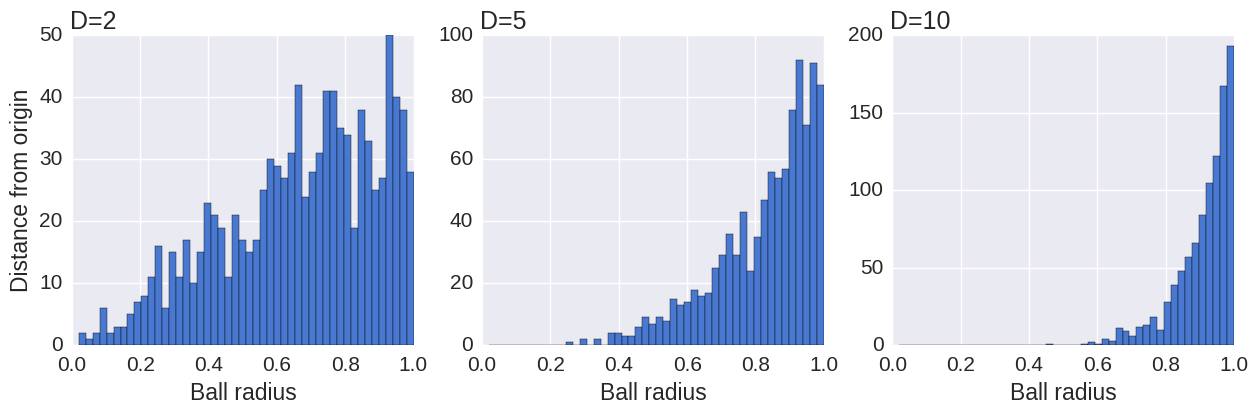
Se, ao reduzir a dimensionalidade do dataset, usássemos a gaussiana também, teríamos um desbalanceamento na distribuição de distâncias de pontos vizinhos, pois a distribuição de distâncias é muito diferente entre um espaco dimensional alto para um espaço com dimensões menores. Esse desequilíbrio levaria a um excesso das forças de atração, levando a um mapeamento não tão agradável de visualizar.
O que acontece com a distribuição de t-Student com um grau de liberdade (Cauchy) é que a cauda é mais longa que na gaussiana (é uma distribuição de cauda longa/pesada/gorda), o que compensa esse desbalanceamento original.
Então, usando tal distribuição conseguimos visualizações melhores, onde os pontos estão separados de forma mais distinguível.
Existem outras otimizações que podem ser feitas para se obter complexidade
Alguns relacionados ao processo do gradiente descendente (learning rate, número de iterações, …).
E perplexidade (0-100), que é usado para escolher o desvio padrão
- O tamanho dos clusters não quer dizer nada sobre o tamanho original do dataset, pois o algoritmo expande naturalmente clusters densos e contrai os mais dispersos
- As distâncias num plot de t-SNE podem também não dizer nada
- Ruído aleatório nem sempre parece ruído aleatório - às vezes ruídos podem ser confundidos com clusters
- Pode ser realizado um PCA antes de proceder com o t-SNE, para uma redução inicial de dimensionalidade, pois o t-SNE pode acabar sofrendo da maldição da dimensionalidade.

https://www.oreilly.com/content/an-illustrated-introduction-to-the-t-sne-algorithm/
https://distill.pub/2016/misread-tsne/
https://medium.com/swlh/t-sne-explained-math-and-intuition-94599ab164cf
https://opentsne.readthedocs.io/en/latest/parameters.html
https://towardsdatascience.com/the-mathematics-behind-principal-component-analysis-fff2d7f4b643
https://www.reneshbedre.com/blog/principal-component-analysis.html