This is the code for my personal website, which will (hopefully) be hosted at oliverhill.io at some point.
The code is written entirely in javascript, using Vue.js as a framework. I'm using a reinforcement learning library for the RL part, as well as D3.js and Anime.js to implement animations (even though I'm pretty sure I only need one of them).
The home page implements a classic Reinforcement Learning algorithm called Epsilon-Greedy Deep Q-Network Learning. I would like to be clear that I did not write the RL component to this - I just set up the environment for it to work in. All the neural network components were written by Andrej Karpathy, and you can find the library here.
As a brief introduction to Reinforcement Learning, the goal of this field of Machine Learning is to have a computer learn a policy of how to act, given some state and some reward based on previous actions. This problem setup is modeled on a statistical construct known as a Finite Markov Decision Process. To learn more about the general problem of Reinforcement Learning and what it can be used for, check out the wikipedia page here.
The Reinforcement Learning problem setup.
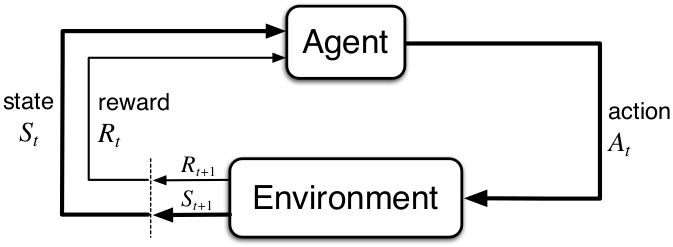
For my problem, I began thinking I would have the agents learn to cluster themselves by rewarding them based on their proximity to other agents. If you keep reading you'll figure out that this didn't work as I wanted, so there is now a single agent learning to cluster all the circles around a point in the top left of the screen, resetting itself and the learning process every time the page loads.
When I originally approached this project, I wanted to write my own implementation of an RL algorithm, and have it run on my site. Q-Learning seemed like the right choice, since the problem is seemingly simple (have circles learn to cluster together), and Q-Learning is fairly basic in the spectrum of RL algorithms, being much simpler to implement than a Policy-Gradient method like Trust Region Policy Optimization. My initial hope was also to not use any neural networks in the solution, but that quickly collapsed after exploring the problem more.
Q-Learning revolves around finding the 'quality' of an action at each state. Ideally, the computer would learn that the highest quality move at each state is to move closer to the centroid of the cluster.
The Q-Learning update looks like this:

Where s is the state, and a is the action at any time step t.
So essentially the computer is learning to maximize the quality of each action it takes, and that quality is dependent on the last value of quality we had for this action, the reward we get for this action, and the expected quality in the next state.
My first idea was to implement Tabular Q-Learning for this task. Tabular Q-Learning is simple to implement (no need to include back-propagated neural networks), and relies upon explicitly storing the quality of each state. This is great for a problem with a small state space, but my problem involves a discrete state at each pixel of the screen, which equates to 5,184,000 states on my computer! If we're lucky, the alignment would work out and the table storing the data would end up being around 42 megabytes in size - far too large for this application.
With only 150 'agents', it would take a very long time to start learning the qualities of actions at enough states for this to be useful. If each agent explored a state that had not been visited previously by it or any other agent, it would still take over 34,000 iterations (one iteration being moving every agent once) to explore each state a single time, which won't give us any information about what actions we should be taking at these states. On to the next idea.
After some consideration, I decided to use a deep learning-based approach. This is because a network can learn a policy and take actions without storing the ideal action at each state. This makes it an ideal solution for continuous state spaces, or for when there are enough discrete states that it becomes prohibitive to explicitly store information about all of them. Perfect!
The first implementation used a network for each circle on the screen, so each circle was it's own reinforcement learning agent. I knew this was not the best approach, since each network would essentially be fighting to learn the same policy, with much less experience than if there was a single network in control. I thought this would be cool though, to have many distinct agents all learning to cluster together. I soon found the physical limitations of my computer (I could only have around forty active agents before the browser became close to unusable), and the agents did not learn very well. On to the next idea.
Now it seemed clear that I needed to have a single network, and thus I was able to push the number of circles on screen to 250. I started out still attempting to get the circles to cluster amongst themselves, but quickly realized that the convergence was too slow, and switched to clustering around a constant point on the screen. This is about where the project ended up; I'm continuing to tweak hyperparameters to achieve the aesthetic that I want.
Changing the reward function structure was the most interesting part of the project. Watching what choices the network will make after being rewarded with different functions is fascinating, and exemplifies why continuous state and action problems are so difficult to reward (even though this is not a continuous action space; there are only four actions). How do you reward an agent that is trying to cook a meal? Do surgery?
Saving network parameters in a database and then not retraining the network every time the page reloads would be simple, however, this is not what I want from this project. I think it's more fun to watch the network struggle with the first few thousand iterations than to see all the circles converge immediately when the page loads. Observing the generative beauty in the stochasticity of the environment and the networks choices is why this exists.