Hardware-accelerated SHA-256 hashing on the Raspberry Pi
This project demonstrates the use of the BCM2835's VideoCore IV Quad Processors (QPUs) to compute SHA-256 hashes.
To try running the benchmark:
sudo apt-get install nodejs
make
sudo mknod char_dev c 100 0
sudo ./benchmark
The BCM2835 contains 12 QPUs, each of which is a 16-way SIMD processor. Using each element of each QPU to compute a single hash, we're able to compute up to 192 hashes in parallel.
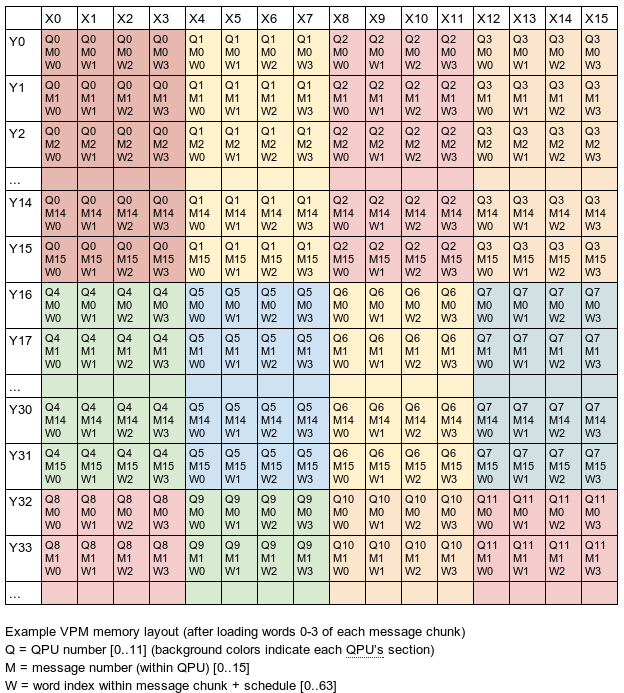
The 4 kilobyes of accessible VPM memory have a layout of 64 rows and 16 columns, with each cell holding a single 32-bit integer (1 word). We reserve a 256 byte section of this memory for each QPU to use - each of these sections consists of 4 columns and 16 rows. Since there are only 12 QPUs, we use only rows 0 through 47 of the VPM.
Each 4-word section of each row is used for transferring data for a single QPU element (and therefore a single hash) to and from main memory via DMA. At various times, this buffer is used for loading pre-processed message data from main memory, storing the schedule array to main memory, loading initial or intermediate hash values from main memory, and storing intermediate or final hash values to main memory.
The program proceeds as follows:
-
Initialization: setup QPU access, allocate and memory-map GPU memory, initialize memory with uniforms (SHA-256 round constants, plus a couple of pointers to memory locations for each QPU to use)
-
Load message chunks: Each raw message is transformed into the format required by SHA-256 as it is copied to GPU memory. This involves byte-swapping each word to big-endian, adding padding, and appending the message length in bits. If the transformed message will take up more than 64 bytes, then multiple passes will need to be made.
-
Start executing QPU program: control is transferred to the QPUs and the ARM program blocks until they're done.
-
Load message words, generate schedule array, and store schedule array: We're able to keep all of the state we need to compute the schedule array in registers. Once the message words are loaded, we generate the schedule array one word at a time, writing it into the VPM as we go, and DMA transferring schedule array words from the VPM to main memory each time our VPM section is filled.
-
Load initial / intermediate hash values: These are DMA transferred from main memory into the VPM and then read into registers.
-
Main compression loop: Each iteration of this loop calculates an update to the intermediate hash values, and requires reading one word of the message schedule (from the VPM) and one word of the round constants (from the uniforms). Schedule array data is DMA transferred into the VPM as needed.
-
Update final hash values: The initial hash values (or intermediate hash values from the previous message chunk, if there was one) are transferred to the VPM. We read them and add to them the output of the main compression loop, then write them back to the VPM and transfer them back to main memory.
-
Exit coordination: The QPUs use a semaphore to coordinate signaling completion to the host program via IRQ.
-
The host program repeats steps 2 through 8 if more message chunks exist.
TODO: need more detailed benchmarks. So far, we seem to be able to achieve around hundreds of KHash/s for small messages.
Some things to try to improve performance:
-
Use additional (or larger) memory pages so that message pre-processing (on the ARM core) and hash computation (on the QPUs) can be done in parallel
-
Try coordinating DMA access between QPUs for loading/storing data in larger chunks, instead of having all QPUs compete over DMA bandwidth
-
Keep QPU programs running instead of starting and stopping them between message chunks
-
Try a more optimized SHA-256 algorithm instead of the reference pseudocode
VideoCore IV 3D Architecture Reference Guide
hermanhermitage/videocoreiv-qpu (I use a slightly modified version of the assembler found here)