
Published in https://github.com/obsidiandynamics/NELI under a BSD (3-clause) license.
The Not-only Exclusive Leader Induction (NELI) protocol provides a mapping from a set of work roles to zero or more assignees responsible for fulfilling each role. The term 'not-only' in relation to the exclusivity property implies the ability to vary the degree of overlap between successive leader assignments. Overlap is permitted under non-exclusive mode, and forbidden otherwise. NELI can be employed in scenarios requiring exclusive leaders — where it is essential that at most one leader exists at any given time. It can equally be used where a finite number of leaders may safely coexist; for example, where it is imperative to maintain elevated levels of availability at the expense of occasional work duplication, and where the duplication of work, while generally undesirable, does not lead to an incorrect outcome.
NELI is a simple, unimodal protocol that is relatively straightforward to implement, building on a shared ledger service that is capable of atomic partition assignment, such as Kafka, Pulsar or Kinesis. This makes NELI particularly attractive for use in Cloud-based computing environments, where the middleware used by applications for routine operation is also employed in a secondary role for deriving leader state.
This text describes the Not-only Exclusive Leader Induction (NELI) protocol built on top of a shared, partitioned ledger capable of atomic partition balancing (such as Apache Kafka, Apache Pulsar or Amazon Kinesis). The protocol yields a leader in a group of contending processes for one of a number of notional roles, such that each role has a finite number of leaders assigned to it. The number of roles is dynamic, as is the number of contending processes.
In non-exclusive mode, this protocol is useful in scenarios where —
- There are several that need fulfilling, and it's desirable to share this load among several processes (likely deployed on different hosts);
- While it is undesirable that a role is simultaneously filled by two processes at any point in time, the system will continue to function correctly. In other words, this may create duplication of work but cannot cause harm (the safety property);
- Availability of the system is imperative; it is required that at least one leader is assigned to a role at all times so that the system as a whole remains operational and progress is made on every role (the liveness property);
- The number of processes and roles is fully dynamic, and may vary on an ad hoc basis. Processes and roles may be added and removed without reconfiguration of the group or downtime. This accommodates rolling deployments, auto-scaling groups, and so forth;
- The use of a dedicated Group Membership Service (GMS) is, for whatever reason, deemed intractable, and where an alternate primitive is sought. Perhaps the system is deployed in an environment where a robust GMS is not natively available, but other capabilities that may internally utilise a GMS may exist. Kinesis in AWS is one such example.
In exclusive mode, NELI is used like any conventional leader election protocol, where there is exactly one role that requires fulfilling, and it is imperative that no more than one process assumes this role at any given time.
Note: The term induction is used in favour of election to convey the notion of partial autonomy in the decision-making process. Under NELI, leaders aren't chosen directly, but induced through other phenomena that are observable by the affected group members, allowing them to independently infer that new leadership is in force. The protocol is also eventually consistent, in that, although members of the group may possess different views at discrete moments in time, these views will invariably converge. This is contrary to a conventional GMS, where leadership election is the direct responsibility of the GMS, and is directly imparted upon the affected parties through view changes or replication, akin to the mechanisms employed in Zab [3] and Raft [4], and their likes.
A centrally-arbitrated topic C is established with a set of partitions M. (Assuming C is realised by a broker capable of atomic partition assignment, such as Kafka, Pulsar or Kinesis.) A set of discrete roles R is available for assignment, and a set of processes P contend for assignment of roles in R. The number of elements in the set M may vary from that of R which, in turn, may vary from P.
Each process in P continually publishes a message on all partitions in M (each successive message is broadcast a few seconds apart). The message has no key or value; the producing process explicitly specifies the partition number for each published message. As each process in P publishes a message to M, then each partition in the set M is continually subjected to messages from each process. Corollary to this, for as long as at least one process in P remains operational, there will be at least one message continually published in each partition in M. Crucial to the protocol is that no partition may 'dry up'.
Each process p in P subscribes to C within a common, predefined consumer group. As per the broker's partition assignment rules, a partition will be assigned to at most one consumer. Multiple partitions may be assigned to a single consumer, and this number may vary slightly from consumer to consumer. Note — this is a fundamental assumption of NELI, requiring a broker that is capable of arbitrating partition assignments. This dynamic set P fits the broad definition of dynamic membership as described in Birman [1]. The term NELI group is used to refer to a set P operating under a distinct consumer group. (An alternate consumer group for P implies a completely different NELI group, as partition assignment within the broker is distinctly bound to a consumer group.)
The relationship between P and M is depicted in Figure 1.
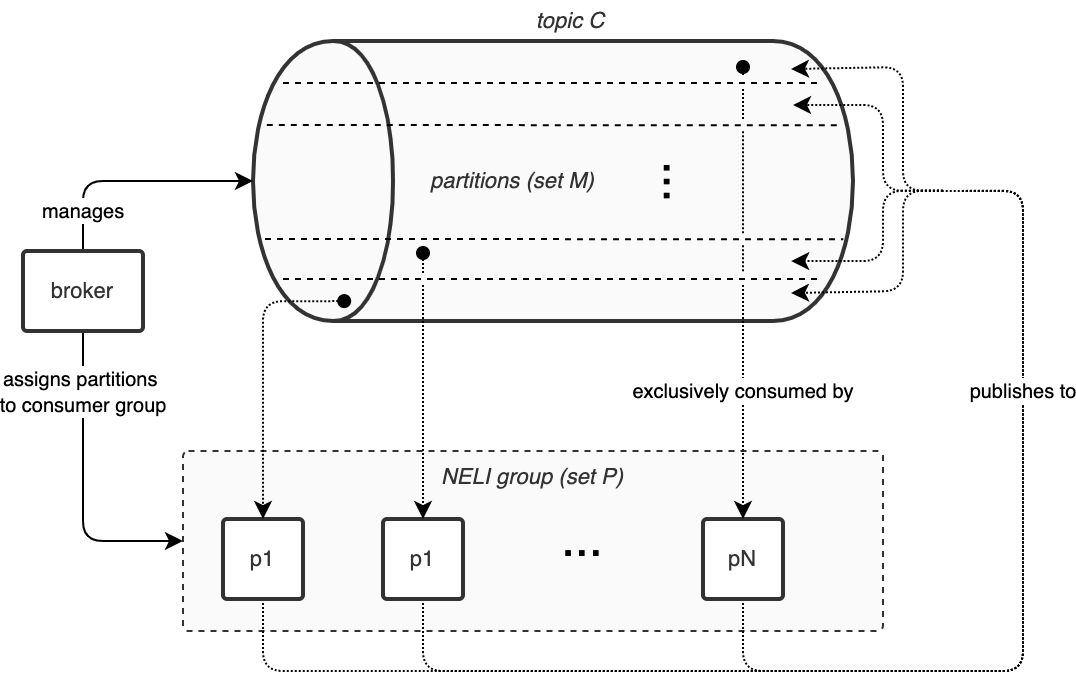
Figure 1: Partition mapping from M to P
Each process p in P, now being a consumer of C, will maintain a vector V of size identical to that of M, with each vector element corresponding to a partition in M, and initialised to zero. V is sized during initialisation of p, by querying the brokers of M to determine the number of partitions in M, which will remain a constant. (As opposed to elements in P and R which may vary dynamically.) This implies that M may not be expanded while a group is in operation.
Upon receipt of a message m from C, p will assign the current machine time as observed by p to the vector element at the index corresponding to m's partition index.
Assuming no subsequent partition reassignments have occurred, each p's vector comprises a combination of zero and non-zero values, where zero values denote partitions that haven't been assigned to p, and non-zero values correspond to partitions that have been assigned to p at least once in the lifetime of p. If the timestamp at any of vector element i is current — in other words, it is more recent than some predefined constant threshold T that lags the current time — then p is a leader for Mi. If partition assignment for Mi is altered (for example, if p is partitioned from the brokers of M, or a timeout occurs), then Vi will cease incrementing and will eventually be lapsed by T. At this point, p must no longer assume that it is the leader for Mi.
Ownership of Mi still requires a translation to a role assignment, as the number of roles in R may vary from the number of partitions in M, and in fact, may do so dynamically without prior notice. To determine whether p is a leader for role Rj, p will compute k = j mod size(M) and check whether p is a leader for Mk through inspection of its local Vk value.
Where size(M) > size(R), ownership of a higher numbered partition in M does not necessarily correspond to a role in R — the mapping from R to M is injective. If size(M) < size(R), ownership of a partition in M corresponds to (potentially) multiple roles in R, i.e. R → M is surjective. And finally, if size(M) = size(R), the relationship is purely bijective. Hence the use of the modulo operation to remap the dynamic extent of R for alignment with M, guaranteeing totality of R → M.
Note: Without the modulo reduction, R → M will be partial when size(M) < size(R), resulting in an indefinitely dormant role and violating the liveness property of the protocol.
Under non-exclusive mode, the value of T is chosen such that T is greater than the partition reassignment threshold of the broker. In Kafka, this is given by the property session.timeout.ms on the consumer, which is 10 seconds by default — so T could be 30 seconds, allowing for up 20 seconds of overlap between successive leadership transitions. In other words, if the partition assignment is withdrawn from an existing leader, it may presume for a further 20 seconds that it is still leading, allowing for the emerging leader to take over. In that time frame, one or more roles may be fulfilled concurrently by both leaders — which is acceptable a priori. (In practice, the default 10-second session timeout may be too long for some HA systems — smaller values may be more appropriate.)
There is no hard relationship between the sizing of M, R and P; however, the following guidelines should be considered:
- R should be at least one in size, as otherwise there are no assignable roles.
- M should not be excessively larger than R, so as to avoid processes that have no actual role assignments despite owning one or more partitions (for high numbered partitions). When using Kafka, this avoids the problem when
partition.assignment.strategyis set torange, which happens to be the default. To that point, it is strongly recommended that thepartition.assignment.strategyproperty on the broker is set toroundrobinorsticky, so as to avoid injective R → M mappings that are asymmetric and poorly distributed among the processes. - M should be sized approximately equal to the steady-state (anticipated) size of P, notwithstanding the fact that P is determined dynamically, through the occasional addition and removal of deployed processes. When the size of M approaches the size of P, the assignment load is shared evenly among the constituents of P.
It is also recommended that the session.timeout.ms property on the consumer is set to a very low value, such as 100 for rapid consumer failure detection and sub-second rebalancing. This requires setting group.min.session.timeout.ms on the broker to 100 or lower, as the default value is 6000. The heartbeat.interval.ms property on the consumer should be set to a sufficiently small value, such as 10.
It can also be shown that the non-exclusivity property can be turned into one of exclusivity through a straightforward adjustment of the protocol. In other words, the at-least-one leader assignment can be turned into an at-most-one. This would be done in systems where non-exclusivity cannot be tolerated.
The non-exclusivity property is directly controlled by the liberal selection of the constant T, being significantly higher than the broker's partition reassignment threshold (the session timeout) — allowing for leadership overlap. Conversely, if T is chosen conservatively, such that T is significantly lower than the reassignment threshold, then the currently assigned leader will expire prior to the assignment of its successor, leaving a gap between successive assignments.
A further complication that arises under exclusive mode is the potential discrepancy between the true and the observed time of message receipt. Consider a scenario where two processes p and q contend for Mi and p is the current assignee. Furthermore, p's host is experiencing an abnormally high load and so p is subjected to intermittent resource starvation. The following sequence of events are conceivable:
- p receives messages from Mi and buffers them within the client library.
- p is preempted by its host's scheduler as the latter reallocates CPU time to a large backlog of competing processes.
- The session timeout lapses on the broker and Mi is reassigned to q.
- q begins receiving messages for Mi, and assumes leadership.
- p is eventually scheduled, processes the message backlog and assigns a local timestamp in Vi, thereby still believing that it is the leader for Mi, for a further time T.
This is solved by using a broker-supplied timestamp in place of a local one. As publishing of a message pub(m) is causally ordered before its consumption con(m), i.e.pub(m) ⟼ con(m), then BTime(pub(m)) ≤ BTime(con(m)), where BTime denotes the broker time and is monotonically non-decreasing. (We use Lamport's [2] well-accepted definition of causality.) By using the broker-supplied publish timestamp, p is taking the most conservative approach possible. However, the role check on p still happens using p's local time, comparing with the receipt of m captured using the broker's time, and there is no discernible relationship between BTime(pub(m)) and CTime(pub(m)), where CTime is the consumer's local time.
Addressing the above requires that the clocks on the broker and the consumer are continually synchronised to some bounded error ceiling e, such that ∀t (|BTime(t) - CTime(t)| ≤ e). Under this constraint, for a partition ownership check relating to m for a threshold T at time t, then it can be trivially shown that ∀m,t (isOwner(partitionOf(m), t, T) → t - CTime(pub(m)) ≤ T + e). In other words, if the ownership check passes, then m was published no longer than T + e ago. It follows that if T + e are both chosen so that their sum is smaller than the broker's session timeout time, then a positive result for a local leadership check will always be correct; a false positive will not occur providing that all the other assumptions hold and that the broker always honours the session timeout before instigating a partition reassignment.
Of course, the last assumption is not necessarily true. The broker may use other heuristics to trigger reassignment. For example, the broker's host OS may close the TCP socket with the consumer and thereby expedite the reassignment on the broker. The closing of the pipe might not be observed for some time on p's host. Alternatively, reassignment may come as a result of a change in the group population (new clients coming online, or existing clients going offline). Under this class of scenarios, p may falsely presume that it is still the leader. Assuming the broker has no minimum grace period, then this could be solved by observing a grace period on the newly assigned leader q, such that q, upon detection of leadership assignment, will intentionally return false from the leadership check function for up to time T since it has implicitly acquired leadership. This gives p sufficient time to relinquish leadership, but extends the worst-case transition time to 2T.
Another, more subtle problem stems from the invariant that the check for leadership must always precede an operation on the critical region. (This is true for every system, irrespective of the exclusivity protocol used.) It may be possible, however unlikely, that the check succeeds, but in between testing the outcome of the check and entering the critical region, the leadership status may have changed. In practice, if T is sufficiently lower than the session timeout, the risk of this happening is minimal. However, in non-deterministic systems with no hard real-time scheduling guarantees, one cannot be absolutely certain. Furthermore, even if the protocol is based on sound reasoning or is formally provable, it will only maintain correctness under a finite set of assumptions. In reality, systems may have defects and may experience multiple correlated and uncorrelated failures. So if exclusive mode is required under an environment of absolute assurance, further mechanisms — such as fencing — must be used to exclude access to critical regions.
Conventional NELI derives a leader state through observing phenomena that appears distinctly for each process. This implies constant publishing of messages and registering their receipt, to infer the present state. This algorithm is sufficiently generic to work with any streaming platform that supports partition exclusivity. In theory, it can be adapted to any broker that has some notion of observable exclusivity; for example, SQS FIFO queues, RabbitMQ, Redis Streams, AMQP-based products supporting Exclusive Consumers and NATS.
Certain streaming platforms, such as Kafka, support rebalance notifications that expressly communicate the state of partition assignments to the consumers. (Support is subject to the client library implementation.)
Where these notifications are supported, it is not necessary to implement the complete NELI protocol; instead, a somewhat reduced form of NELI can be employed. A client supplies a rebalance callback in its subscription; the callback is invoked by the client library in response to changes in the partition assignment state, which can be trivially interpreted by the application.
The rebalance callback straightforwardly induces leadership through partition assignment, where the latter is managed by Kafka's group coordinator. The use of the callback requires a stable network connection to the Kafka cluster; otherwise, if a network partition occurs, another client may be granted partition ownership — an event which is not synchronized with the outgoing leader. (Kafka's internal heartbeats are used to signal client presence to the broker, but they are not generally suitable for identifying network partitions.) While this acceptable in non-exclusive mode, having multiple concurrent leaders is a breach of invariants for exclusive mode.
In addition to observing partition assignment changes, the partition owner periodically publishes a heartbeat message to the monitored topic. It also consumes messages from that topic — effectively observing its own heartbeats, and thereby asserting that it is connected to the cluster and still owns the partition in question. If no heartbeat is received within a set deadline, the leader will take the worst-case assumption that the partition will be imminently reassigned, and will proactively relinquish leadership. (The deadline is chosen to be a fraction of session.timeout.ms, typically a third or less — giving the outgoing leader sufficient time to fence itself.) If connectivity is later resumed while the leader is still the owner of the partition on the broker, it will again receive a heartbeat, allowing the client to resume the leader role. If the partition has been subsequently reassigned, no heartbeat will be received upon reconnection and the client will be forced to rejoin the group — the act of which will invoke the rebalance callback, effectively resetting the client.
One notable difference between this variation of the protocol and the full version is that the latter requires all members to continuously publish messages, thereby ensuing continuous presence of heartbeats. By comparison, the 'fast' version only requires the assigned owner of the partition to emit heartbeats, whereby the ownership status is communicated via the callback.
The main difference, however, is in the transition of leader status during a routine partition rebalancing event, where there is no failure per se, but the partitions are reassigned as a result of a group membership change. Under exclusive mode, the full version of the protocol requires that the new leader allows for a grace period before assuming the leader role, thereby according the outgoing leader an opportunity to complete its work. The reduced form relies on the blocking nature of the rebalance callback, effectively acting as a synchronization barrier — whereby the rebalance operation is halted on the broker until the outgoing leader confirms that it has completed any in-flight work. The fast version is called as such because it is more responsive during routine rebalancing. It also requires fewer configuration parameters.
For the sake of clarity and, more importantly, to avoid failure correlation, it is highly recommended to use a dedicated topic for each NELI group, configured in accordance with the group's needs. However, under certain circumstances, it may be more appropriate to share a topic across multiple NELI groups. For example, the broker might be offered under a SaaS model, whereby the addition of topics (and partitions) incurs additional costs.
By using a different consumer group ID in a common topic C — in effect a different NELI group — the same set of partitions M can be exploited to assign a different set of roles R' to the same or a different set of processes P or P', with no change to the protocol.
When reusing a brokered topic across multiple NELI groups, it is recommended to divide the broadcast frequency by a factor commensurate with the number of NELI groups. In other words, if processes within a single NELI group broadcast with a frequency F to all partitions in C, then adding a second NELI group should change the broadcast frequency to F/2 for both groups.
By the term non-exclusive leader it is meant that at least one leader may be assigned; it shouldn't be taken that the assigned leader is actually functioning, network-reachable and is able to fulfil its role at all times. As such, single-group NELI cannot be used directly within a setting of strictly continuous availability, where at least two leaders are always required. The thresholds used in NELI may be tuned such that the transition time between leaders is minimal, at the expense of work duplication; however, this does not formally satisfy continuous availability guarantees, whereby zero downtime is assumed under a finite set of assumptions (for example, at most one component failure is tolerated).
In a continuously available system, two or more disjoint (non-overlapping) NELI process groups P1 and P2 (through to PN, if necessary) may be used concurrently on the same set M (or a different set M', hosted on an independent set of brokers) and a common R, such that any Ri would be assigned to a member in P1 and P2, such that there will be at two leaders for any Ri at any point in time — one from each set. (There may be more leaders if non-exclusive mode is used, or fewer leaders if operating in exclusive mode.)
Furthermore, it is prudent to keep the process sets P1 and P2 not only disjoint, but also deployed on separate hosts, such that the failure of a process in P1 will not correlate to a failure in P2, where both failed processes may happen to share role assignments.
In a dynamically sized, distributed cluster where some deterministic function is used to map a key to a shard, it is often highly desirable to minimise the amount of reassignment during the growth and contraction of the cluster. By mapping a fixed number of notional hash slots to roles, then subsequently using NELI to arbitrate role assignment for a dynamically variable set of processes P (deployed on hosts across the cluster), we achieve a stable mapping from processes to hash slots that varies minimally with membership changes in P. Taking the hash of a given key, modulo the number of hash slots, we arrive at the process that is responsible for managing the appropriate shard.
[1] K. Birman, "Reliable Distributed Systems", Springer. 2005.
[2] L. Lamport, "Time clocks and the ordering of events in a distributed system", Communications of the ACM, vol. 21, pp. 558-565, July 1978.
[3] F. Junqueira, B. Reed, M. Serafini, "Zab: High-performance broadcast for primary-backup systems" Proc. 41st Int. Conf. Dependable Syst. Netw. pp. 245-256 June 2011.
[4] D. Ongaro, J. Ousterhout, “In Search of an Understandable Consensus Algorithm” in USENIX Annual Technical Conference, 2014.