![]()
![]()
![]()




Haystack is an end-to-end framework that enables you to build powerful and production-ready pipelines for different search use cases. Whether you want to perform Question Answering or semantic document search, you can use the State-of-the-Art NLP models in Haystack to provide unique search experiences and allow your users to query in natural language. Haystack is built in a modular fashion so that you can combine the best technology from other open-source projects like Huggingface's Transformers, Elasticsearch, or Milvus.

- Ask questions in natural language and find granular answers in your documents.
- Perform semantic search and retrieve documents according to meaning, not keywords
- Use off-the-shelf models or fine-tune them to your domain.
- Use user feedback to evaluate, benchmark, and continuously improve your live models.
- Leverage existing knowledge bases and better handle the long tail of queries that chatbots receive.
- Automate processes by automatically applying a list of questions to new documents and using the extracted answers.
- Latest models: Utilize all latest transformer-based models (e.g., BERT, RoBERTa, MiniLM) for extractive QA, generative QA, and document retrieval.
- Modular: Multiple choices to fit your tech stack and use case. Pick your favorite database, file converter, or modeling framework.
- Pipelines: The Node and Pipeline design of Haystack allows for custom routing of queries to only the relevant components.
- Open: 100% compatible with HuggingFace's model hub. Tight interfaces to other frameworks (e.g., Transformers, FARM, sentence-transformers)
- Scalable: Scale to millions of docs via retrievers, production-ready backends like Elasticsearch / FAISS, and a fastAPI REST API
- End-to-End: All tooling in one place: file conversion, cleaning, splitting, training, eval, inference, labeling, etc.
- Developer friendly: Easy to debug, extend and modify.
- Customizable: Fine-tune models to your domain or implement your custom DocumentStore.
- Continuous Learning: Collect new training data via user feedback in production & improve your models continuously
| 📒 Docs | Overview, Components, Guides, API documentation |
| 💾 Installation | How to install Haystack |
| 🎓 Tutorials | See what Haystack can do with our Notebooks & Scripts |
| 🔰 Quick Demo | Deploy a Haystack application with Docker Compose and a REST API |
| 🖖 Community | Discord, Twitter, Stack Overflow, GitHub Discussions |
| ❤️ Contributing | We welcome all contributions! |
| 📊 Benchmarks | Speed & Accuracy of Retriever, Readers and DocumentStores |
| 🔭 Roadmap | Public roadmap of Haystack |
| 📰 Blog | Read our articles on Medium |
| ☎️ Jobs | We're hiring! Have a look at our open positions |
1. Basic Installation
You can install a basic version of Haystack's latest release by using pip.
pip3 install farm-haystack
This command will install everything needed for basic Pipelines that use an Elasticsearch Document Store.
2. Full Installation
If you plan to be using more advanced features like Milvus, FAISS, Weaviate, OCR or Ray, you will need to install a full version of Haystack. The following command will install the latest version of Haystack from the master branch.
git clone https://github.com/deepset-ai/haystack.git
cd haystack
pip install --upgrade pip
pip install -e '.[all]' ## or 'all-gpu' for the GPU-enabled dependencies
If you cannot upgrade pip to version 21.3 or higher, you will need to replace:
'.[all]'with'.[sql,only-faiss,only-milvus1,weaviate,graphdb,crawler,preprocessing,ocr,onnx,ray,dev]''.[all-gpu]'with'.[sql,only-faiss-gpu,only-milvus1,weaviate,graphdb,crawler,preprocessing,ocr,onnx-gpu,ray,dev]'
For an complete list of the dependency groups available, have a look at the haystack/setup.cfg file.
To install the REST API and UI, run the following from the root directory of the Haystack repo
pip install rest_api/
pip install ui/
3. Installing on Windows
pip install farm-haystack -f https://download.pytorch.org/whl/torch_stable.html
4. Installing on Apple Silicon (M1)
M1 Macbooks require some extra dependencies in order to install Haystack.
# some additional dependencies needed on m1 mac
brew install postgresql
brew install cmake
brew install rust
# haystack installation
GRPC_PYTHON_BUILD_SYSTEM_ZLIB=true pip install git+https://github.com/deepset-ai/haystack.git
5. Learn More
See our installation guide for more options. You can find out more about our PyPi package on our PyPi page.
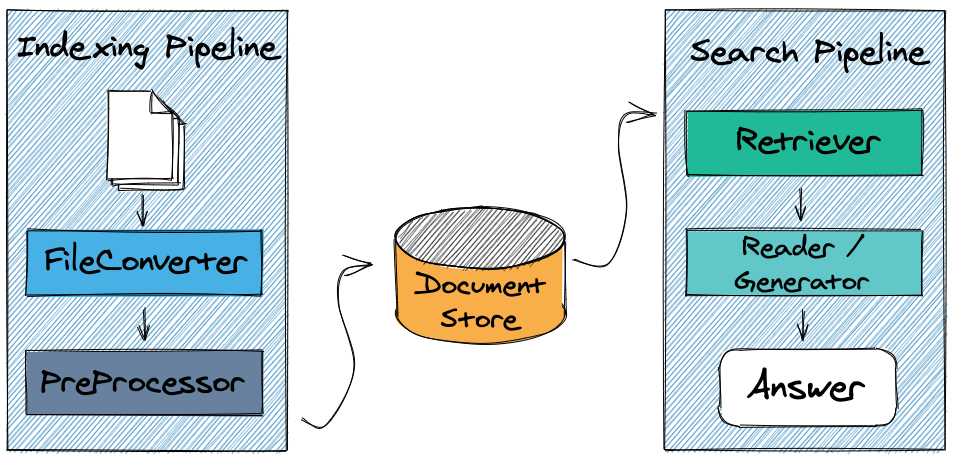
Follow our introductory tutorial to setup a question answering system using Python and start performing queries! Explore the rest of our tutorials to learn how to tweak pipelines, train models and perform evaluation.
- Tutorial 1 - Basic QA Pipeline: Jupyter notebook | Colab | Python
- Tutorial 2 - Fine-tuning a model on own data: Jupyter notebook | Colab | Python
- Tutorial 3 - Basic QA Pipeline without Elasticsearch: Jupyter notebook | Colab | Python
- Tutorial 4 - FAQ-style QA: Jupyter notebook | Colab | Python
- Tutorial 5 - Evaluation of the whole QA-Pipeline: Jupyter noteboook | Colab | Python
- Tutorial 6 - Better Retrievers via "Dense Passage Retrieval": Jupyter noteboook | Colab | Python
- Tutorial 7 - Generative QA via "Retrieval-Augmented Generation": Jupyter noteboook | Colab | Python
- Tutorial 8 - Preprocessing: Jupyter noteboook | Colab | Python
- Tutorial 9 - DPR Training: Jupyter noteboook | Colab | Python
- Tutorial 10 - Knowledge Graph: Jupyter noteboook | Colab | Python
- Tutorial 11 - Pipelines: Jupyter noteboook | Colab | Python
- Tutorial 12 - Long-Form Question Answering: Jupyter noteboook | Colab | Python
- Tutorial 13 - Question Generation: Jupyter noteboook | Colab | Python
- Tutorial 14 - Query Classifier: Jupyter noteboook | Colab | Python
- Tutorial 15 - TableQA: Jupyter noteboook | Colab | Python
- Tutorial 16 - Document Classification at Indexing Time: Jupyter noteboook | Colab | Python
- Tutorial 17 - Answers & Documents to Speech: Jupyter noteboook | Colab | Python
- Tutorial 18 - Generative Pseudo Labeling: Jupyter noteboook | Colab | Python
Hosted
Try out our hosted Explore The World live demo here! Ask any question on countries or capital cities and let Haystack return the answers to you.
Local
Start up a Haystack service via Docker Compose. With this you can begin calling it directly via the REST API or even interact with it using the included Streamlit UI.
Click here for a step-by-step guide
1. Update/install Docker and Docker Compose, then launch Docker
apt-get update && apt-get install docker && apt-get install docker-compose
service docker start
2. Clone Haystack repository
git clone https://github.com/deepset-ai/haystack.git
3. Pull images & launch demo app
cd haystack
docker-compose pull
docker-compose up
# Or on a GPU machine: docker-compose -f docker-compose-gpu.yml up
You should be able to see the following in your terminal window as part of the log output:
..
ui_1 | You can now view your Streamlit app in your browser.
..
ui_1 | External URL: http://192.168.108.218:8501
..
haystack-api_1 | [2021-01-01 10:21:58 +0000] [17] [INFO] Application startup complete.
4. Open the Streamlit UI for Haystack by pointing your browser to the "External URL" from above.
You should see the following:
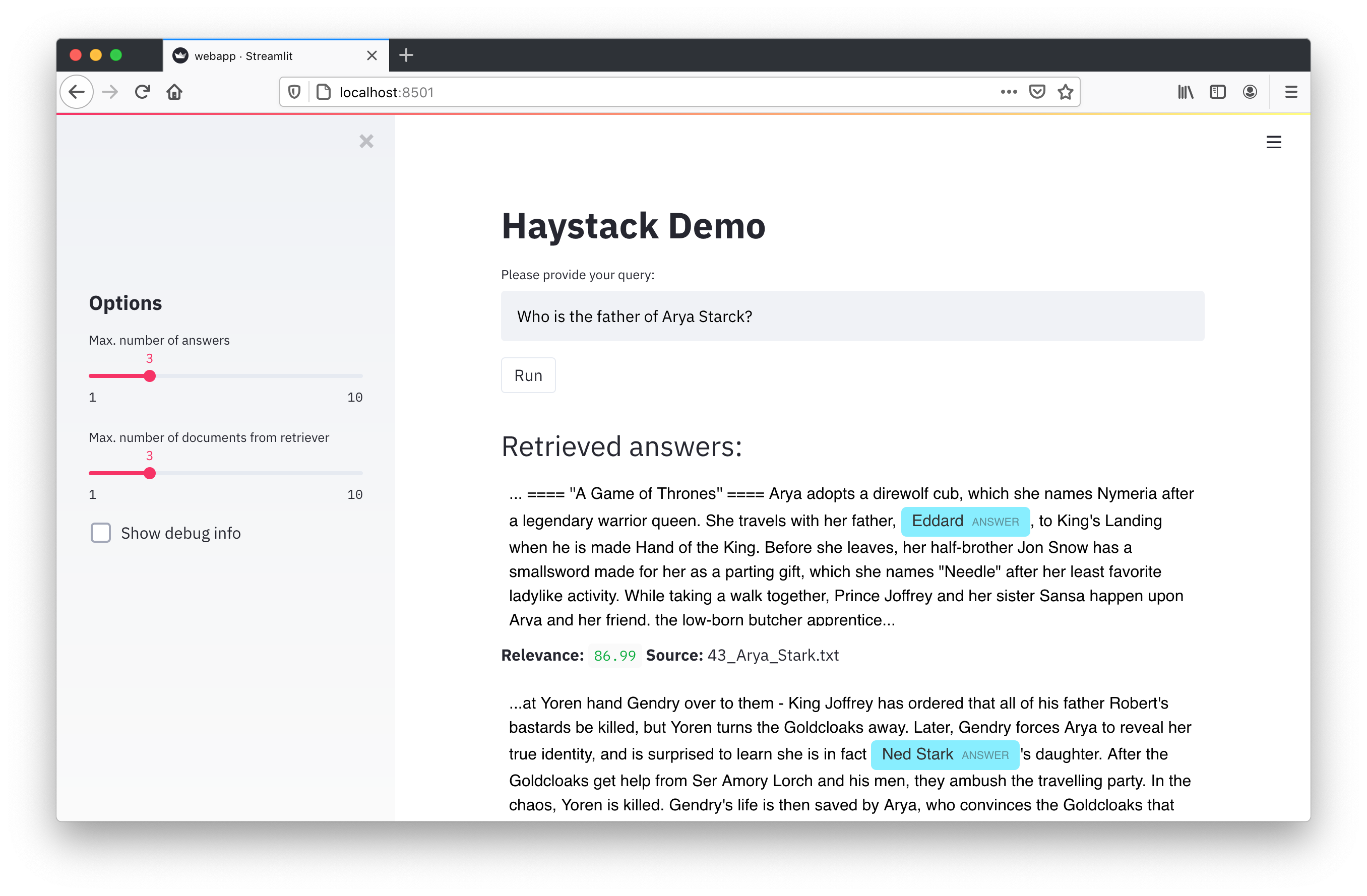
You can then try different queries against a pre-defined set of indexed articles related to Game of Thrones.
Note: The following containers are started as a part of this demo:
- Haystack API: listens on port 8000
- DocumentStore (Elasticsearch): listens on port 9200
- Streamlit UI: listens on port 8501
Please note that the demo will publish the container ports to the outside world. We suggest that you review the firewall settings depending on your system setup and the security guidelines.
There is a very vibrant and active community around Haystack which we are regularly interacting with! If you have a feature request or a bug report, feel free to open an issue in Github. We regularly check these and you can expect a quick response. If you'd like to discuss a topic, or get more general advice on how to make Haystack work for your project, you can start a thread in Github Discussions or our Discord channel. We also check Twitter and Stack Overflow.
We are very open to the community's contributions - be it a quick fix of a typo, or a completely new feature! You don't need to be a Haystack expert to provide meaningful improvements. To learn how to get started, check out our Contributor Guidelines first. You can also find instructions to run the tests locally there.
Thanks so much to all those who have contributed to our project!
Here's a list of organizations who use Haystack. Don't hesitate to send a PR to let the world know that you use Haystack. Join our growing community!