

Figure 1: Three distinct QAG approaches.
The lmqg is a python library for question and answer generation (QAG) with language models (LMs). Here, we consider
paragraph-level QAG, where user will provide a context (paragraph or document), and the model will generate a list of
question and answer pairs on the context. With lmqg, you can do following things:
- Generation in One Line of Code: Generate questions and answers in 8 languages (en/fr/ja/ko/ru/it/es/de).
- Model Training/Evaluation: Train & evaluate your own QG/QAG models.
- QAG & QG Model Hosting: Host your QAG models on a web application or a restAPI server.
- AutoQG: Online web service to generate questions and answers with our models.
Update May 2023: Two papers got accepted by ACL 2023 (QAG at finding, LMQG at system demonstration).
Update Oct 2022: Our QG paper got accepted by EMNLP main 2022.
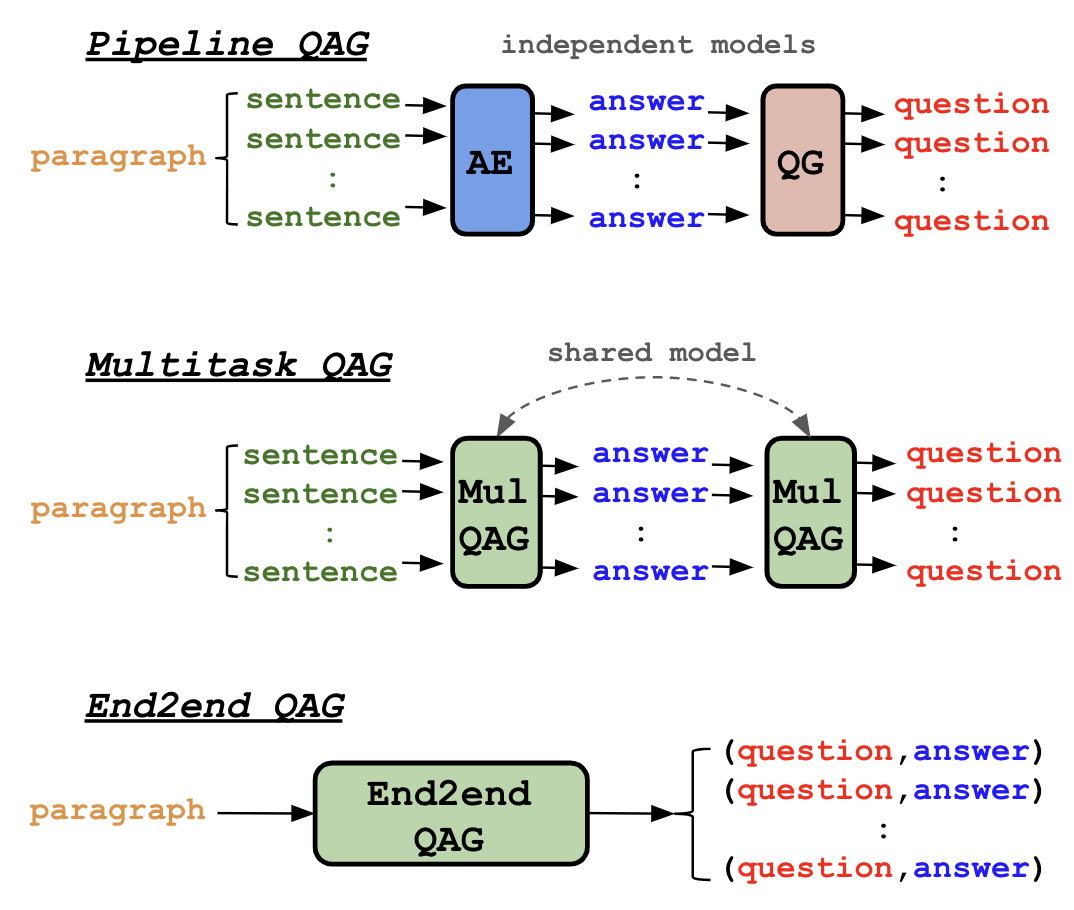
Our QAG models can be grouped into three types: Pipeline, Multitask,
and End2end (see Figure 1). The Pipeline consists of question generation (QG) and answer extraction (AE) models independently,
where AE will parse all the sentences in the context to extract answers, and QG will generate questions on the answers.
The Multitask follows same architecture as the Pipeline, but the QG and AE models are shared model fine-tuned jointly.
Finally, End2end model will generate a list of question and answer pairs in an end-to-end manner.
In practice, Pipeline and Multitask generate more question and answer pairs, while End2end generates less but a few times faster,
and the quality of the generated question and answer pairs depend on language.
All types are available in the 8 diverse languages (en/fr/ja/ko/ru/it/es/de) via lmqg, and the models are all shared on HuggingFace (see the model card).
To know more about QAG, please check our ACL 2023 paper that describes the QAG models and reports a complete performance comparison of each QAG models in every language.
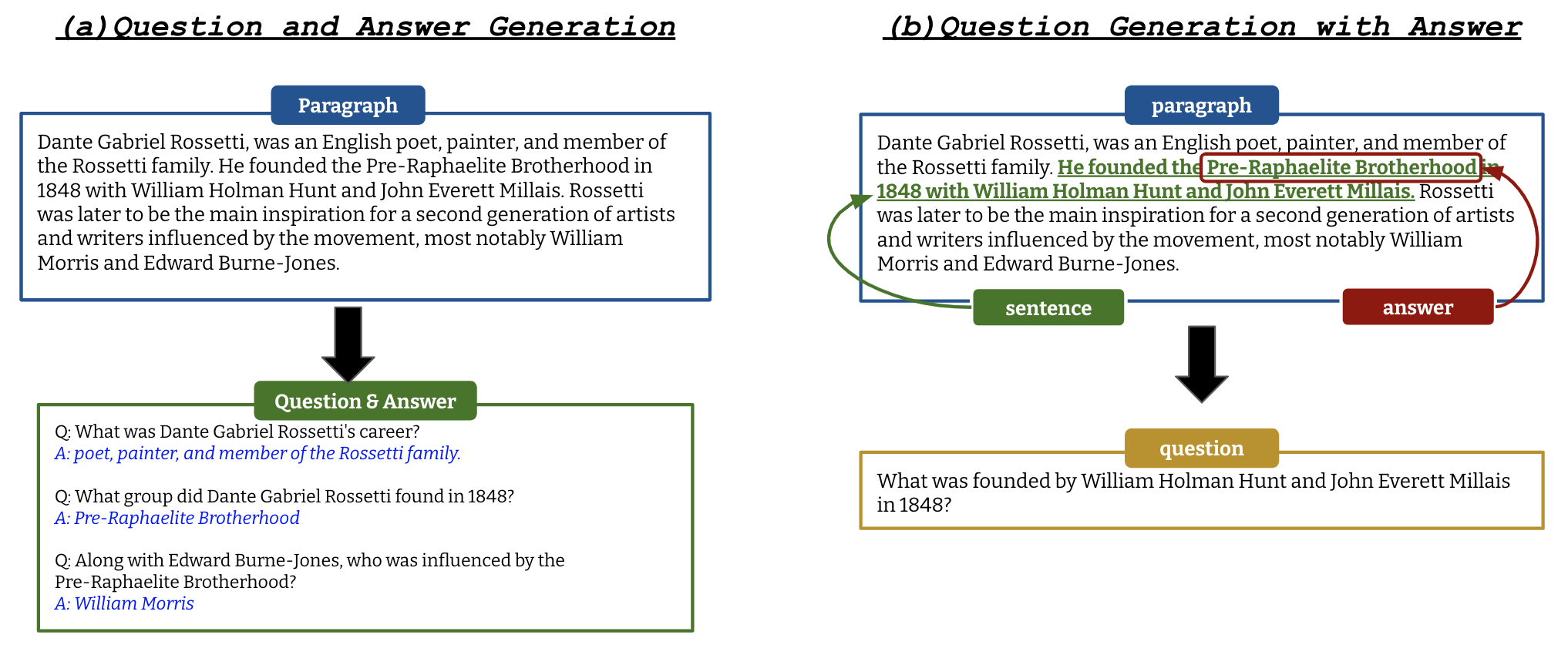
Figure 2: An example of QAG (a) and QG (b).
All the functionalities support question generation as well. Our QG model assumes user to specify an answer in addition to a context, and the QG model will generate a question that is answerable by the answer given the context (see Figure 2 for a comparison of QAG and QG). To know more about QG, please check our EMNLP 2022 paper that describes the QG models more in detail.
Let's install lmqg via pip first.
pip install lmqgThe main functionality of lmqg is to generate question and answer pairs on a given context with a handy api.
The available models for each QAG class can be found at model card.
- QAG with End2end or Multitask Models: The end2end QAG models are fine-tuned to generate a list of QA pairs with a single inference, so it is the fastest class among our QAG models. Meanwhile, multitask QAG models breakdown the QAG task into QG and AE, where they parse each sentence to get the answer with AE, and generate question on each answer with QG. Multitask QAG potentially generate more QA pairs than end2end QAG, but inference takes a few times more than end2end models. Both models can be used as following
from pprint import pprint
from lmqg import TransformersQG
# initialize model
model = TransformersQG('lmqg/t5-base-squad-qag') # or TransformersQG(model='lmqg/t5-base-squad-qg-ae')
# paragraph to generate pairs of question and answer
context = "William Turner was an English painter who specialised in watercolour landscapes. He is often known " \
"as William Turner of Oxford or just Turner of Oxford to distinguish him from his contemporary, " \
"J. M. W. Turner. Many of Turner's paintings depicted the countryside around Oxford. One of his " \
"best known pictures is a view of the city of Oxford from Hinksey Hill."
# model prediction
question_answer = model.generate_qa(context)
# the output is a list of tuple (question, answer)
pprint(question_answer)
[
('Who was an English painter who specialised in watercolour landscapes?', 'William Turner'),
('What is William Turner often known as?', 'William Turner of Oxford or just Turner of Oxford'),
("What did many of Turner's paintings depict?", 'the countryside around Oxford'),
("What is one of Turner's best known pictures?", 'a view of the city of Oxford from Hinksey Hill')
]- QAG with Pipeline Models: The pipeline QAG is similar to multitask QAG, but the QG and AE models are independently fine-tuned, unlike
multitask QAG that fine-tunes QG and AE jointly. Pipeline QAG can improve the performance in some cases, but it is as heavy as multitask QAG with
more storage consuming due to the two models loaded. The pipeline QAG can be used as following. The
modelandmodel_aeare the QG and AE models respectively.
from pprint import pprint
from lmqg import TransformersQG
# initialize model
model = TransformersQG(model='lmqg/t5-base-squad-qg', model_ae='lmqg/t5-base-squad-ae')
# paragraph to generate pairs of question and answer
context = "William Turner was an English painter who specialised in watercolour landscapes. He is often known " \
"as William Turner of Oxford or just Turner of Oxford to distinguish him from his contemporary, " \
"J. M. W. Turner. Many of Turner's paintings depicted the countryside around Oxford. One of his " \
"best known pictures is a view of the city of Oxford from Hinksey Hill."
# model prediction
question_answer = model.generate_qa(context)
# the output is a list of tuple (question, answer)
pprint(question_answer)
[
('Who was an English painter who specialised in watercolour landscapes?', 'William Turner'),
('What is another name for William Turner?', 'William Turner of Oxford'),
("What did many of William Turner's paintings depict around Oxford?", 'the countryside'),
('From what hill is a view of the city of Oxford taken?', 'Hinksey Hill.')
]- QG only: The QG model can be used as following. The
modelis the QG model. See the QG-Bench, a multilingual QG benchmark, for the list of available QG models.
from pprint import pprint
from lmqg import TransformersQG
# initialize model
model = TransformersQG(model='lmqg/t5-base-squad-qg')
# a list of paragraph
context = [
"William Turner was an English painter who specialised in watercolour landscapes",
"William Turner was an English painter who specialised in watercolour landscapes"
]
# a list of answer (same size as the context)
answer = [
"William Turner",
"English"
]
# model prediction
question = model.generate_q(list_context=context, list_answer=answer)
pprint(question)
[
'Who was an English painter who specialised in watercolour landscapes?',
'What nationality was William Turner?'
]- AE only: The QG model can be used as following. The
modelis the QG model.
from pprint import pprint
from lmqg import TransformersQG
# initialize model
model = TransformersQG(model='lmqg/t5-base-squad-ae')
# model prediction
answer = model.generate_a("William Turner was an English painter who specialised in watercolour landscapes")
pprint(answer)
['William Turner']
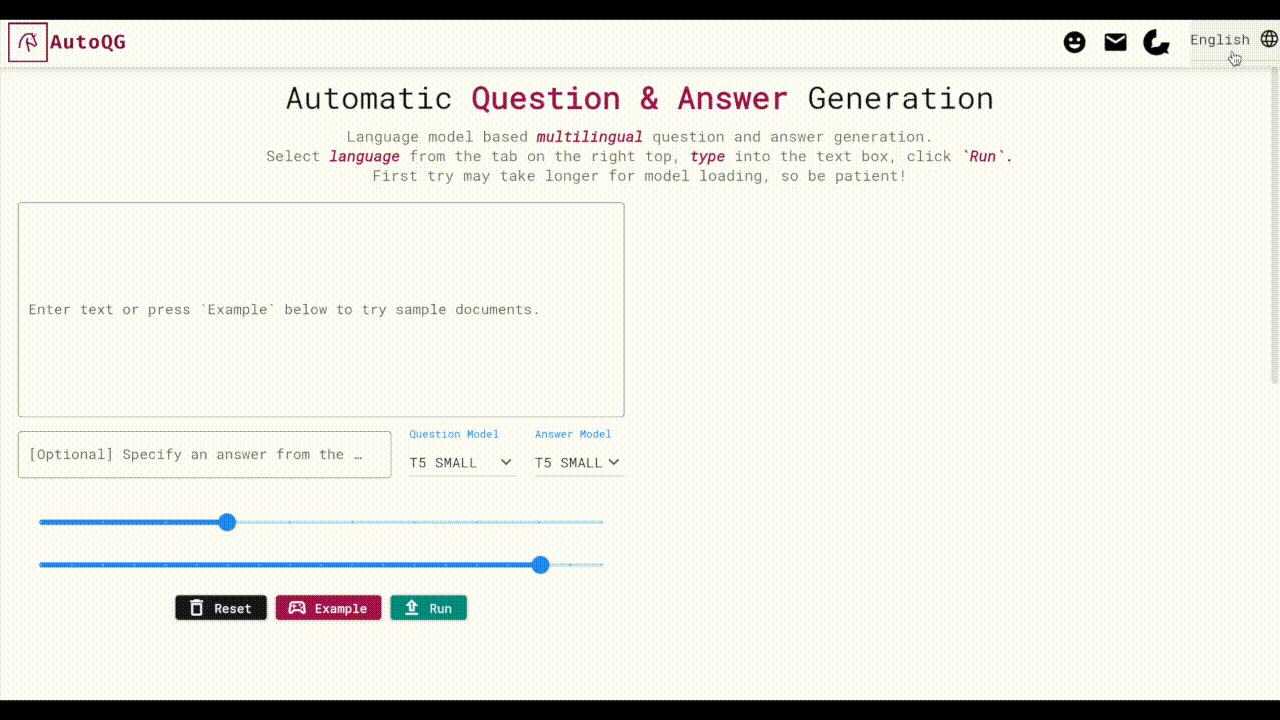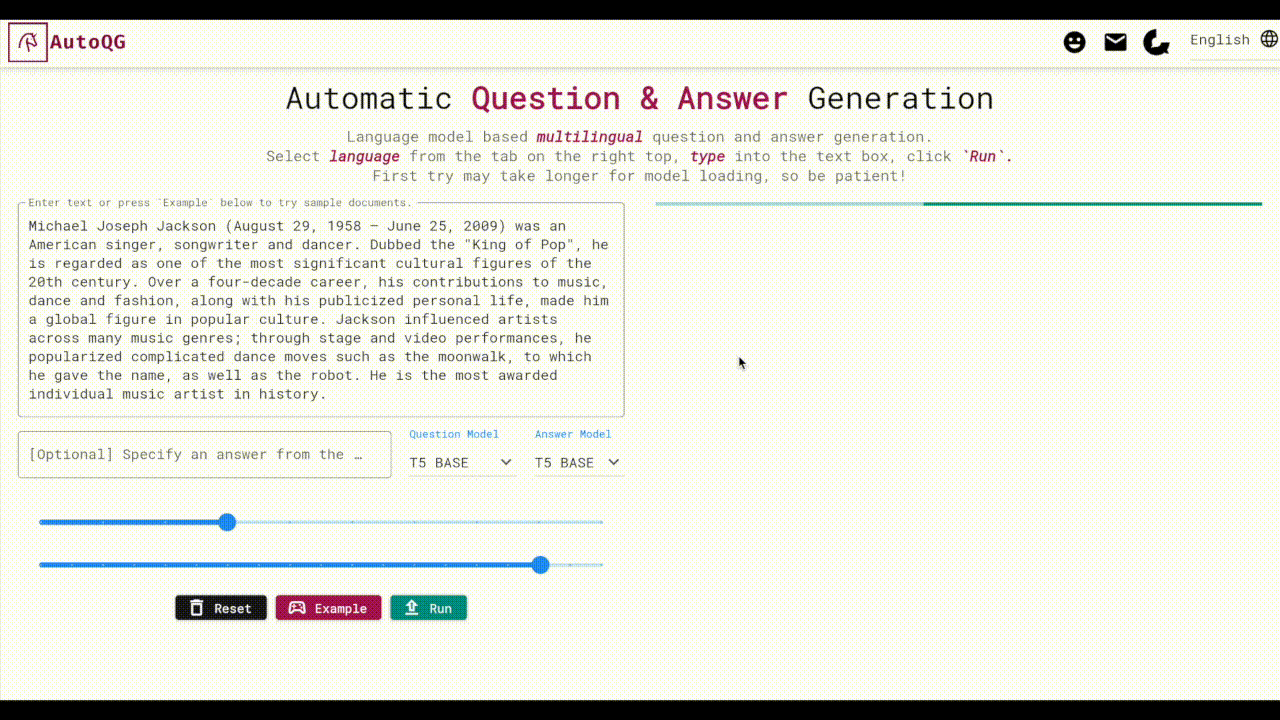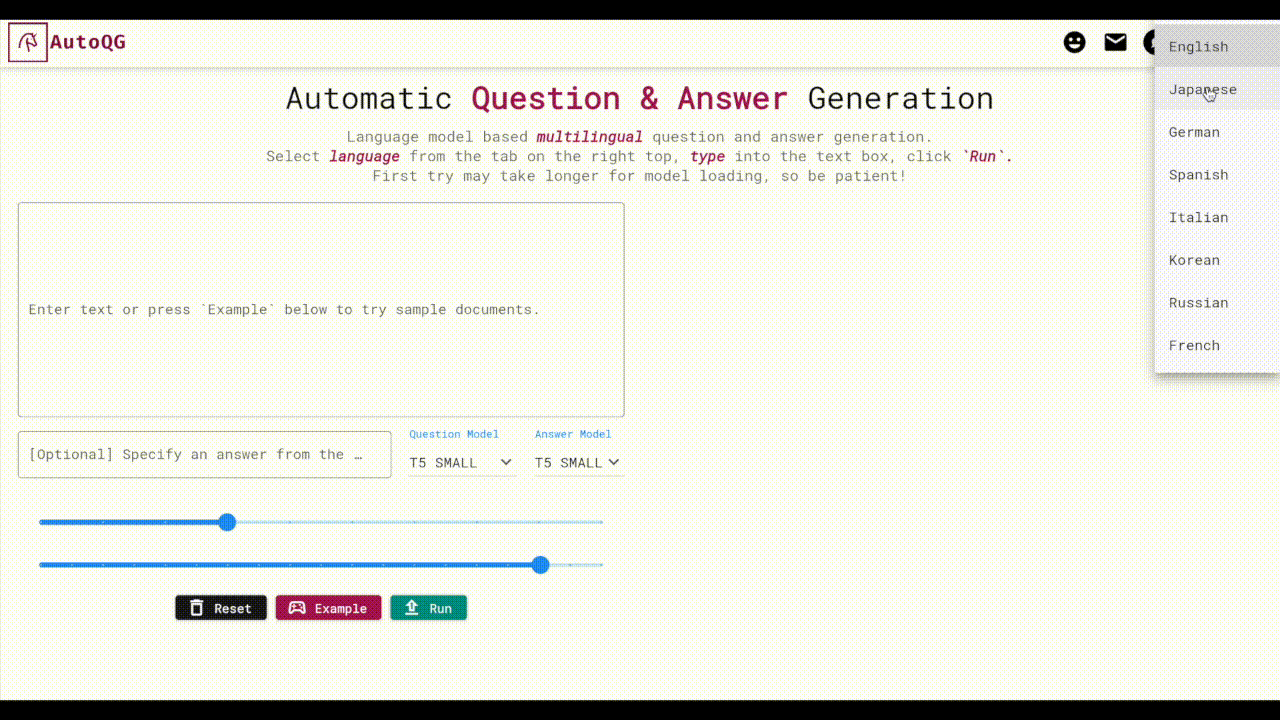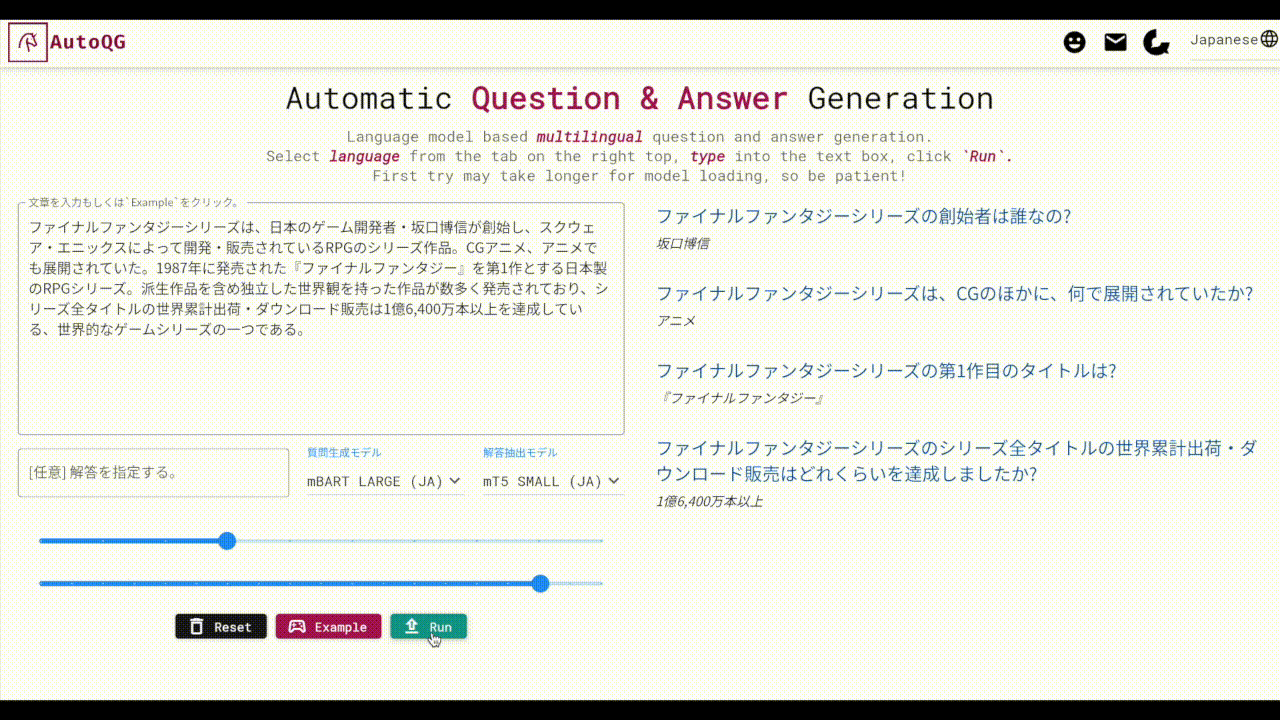
AutoQG (https://autoqg.net) is a free web application hosting our QAG models.
The lmqg also provides a command line interface to fine-tune and evaluate QG, AE, and QAG models.
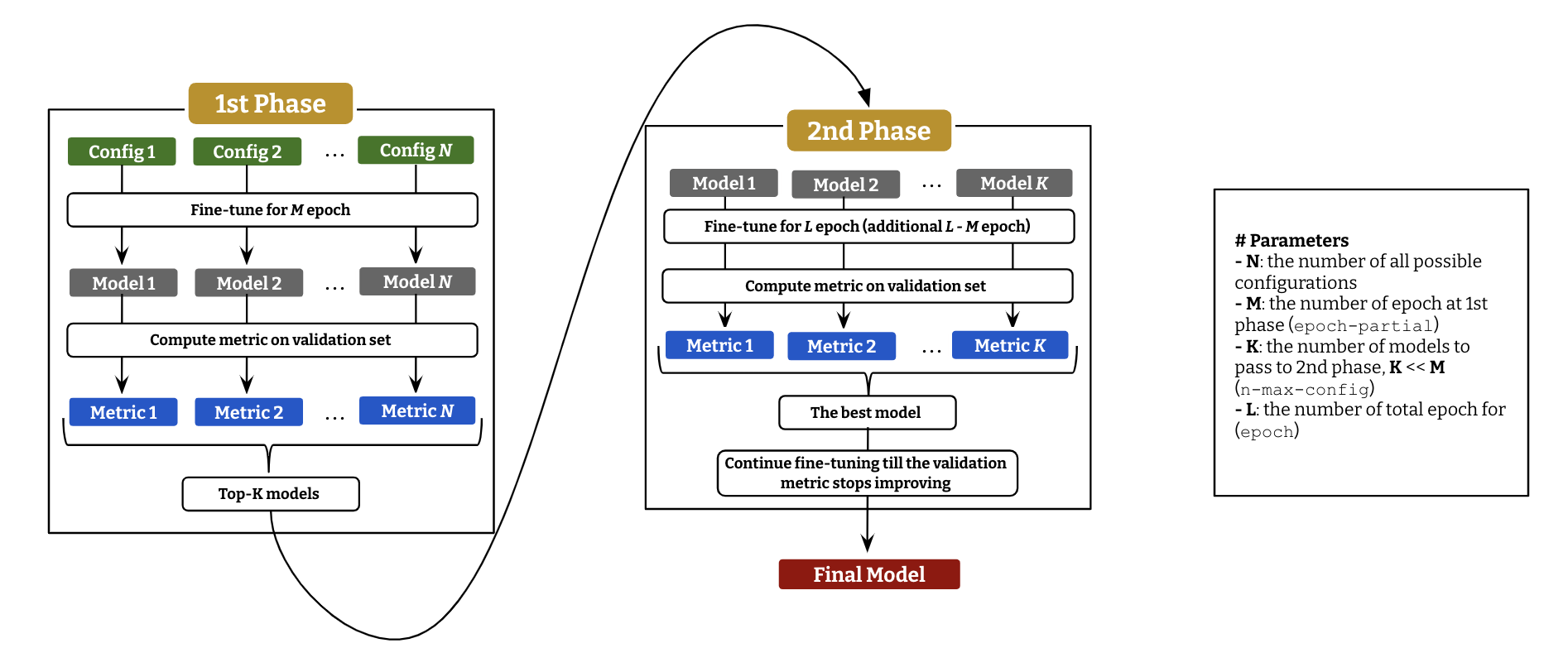
To fine-tune QG (or AE, QAG) model, we employ a two-stage hyper-parameter optimization, described as above diagram. Following command is to run the fine-tuning with parameter optimization.
lmqg-train-search -c "tmp_ckpt" -d "lmqg/qg_squad" -m "t5-small" -b 64 --epoch-partial 5 -e 15 --language "en" --n-max-config 1 \
-g 2 4 --lr 1e-04 5e-04 1e-03 --label-smoothing 0 0.15Check lmqg-train-search -h to display all the options.
Fine-tuning models in python follows below.
from lmqg import GridSearcher
trainer = GridSearcher(
checkpoint_dir='tmp_ckpt',
dataset_path='lmqg/qg_squad',
model='t5-small',
epoch=15,
epoch_partial=5,
batch=64,
n_max_config=5,
gradient_accumulation_steps=[2, 4],
lr=[1e-04, 5e-04, 1e-03],
label_smoothing=[0, 0.15]
)
trainer.run()The evaluation tool reports BLEU4, ROUGE-L, METEOR, BERTScore, and MoverScore following QG-Bench.
From command line, run following command
lmqg-eval -m "lmqg/t5-large-squad-qg" -e "./eval_metrics" -d "lmqg/qg_squad" -l "en"where -m is a model alias on huggingface or path to local checkpoint, -e is the directly to export the metric file, -d is the dataset to evaluate, and -l is the language of the test set.
Instead of running model prediction, you can provide a prediction file instead to avoid computing it each time.
lmqg-eval --hyp-test '{your prediction file}' -e "./eval_metrics" -d "lmqg/qg_squad" -l "en"The prediction file should be a text file of model generation in each line in the order of test split in the target dataset
(sample).
Check lmqg-eval -h to display all the options.
Finally, lmqg provides a rest API which hosts the model inference through huggingface inference API. You need huggingface API token to run your own API and install dependencies as below.
pip install lmqg[api]Swagger UI is available at http://127.0.0.1:8088/docs, when you run the app locally (replace the address by your server address).
- Build/Run Local (command line):
export API_TOKEN={Your Huggingface API Token}
uvicorn app:app --reload --port 8088
uvicorn app:app --host 0.0.0.0 --port 8088- Build/Run Local (docker):
docker build -t lmqg/app:latest . --build-arg api_token={Your Huggingface API Token}
docker run -p 8080:8080 lmqg/app:latestYou must pass the huggingface api token via the environmental variable API_TOKEN.
The main endpoint is question_generation, which has following parameters,
| Parameter | Description |
|---|---|
| input_text | input text, a paragraph or a sentence to generate question |
| language | language |
| qg_model | question generation model |
| answer_model | answer extraction model |
and return a list of dictionaries with question and answer.
{
"qa": [
{"question": "Who founded Nintendo Karuta?", "answer": "Fusajiro Yamauchi"},
{"question": "When did Nintendo distribute its first video game console, the Color TV-Game?", "answer": "1977"}
]
}Please cite following paper if you use any resource and see the code to reproduce the model if needed.
- Generative Language Models for Paragraph-Level Question Generation, EMNLP 2022 Main: The QG models (code to reproduce experiments).
@inproceedings{ushio-etal-2022-generative,
title = "{G}enerative {L}anguage {M}odels for {P}aragraph-{L}evel {Q}uestion {G}eneration",
author = "Ushio, Asahi and
Alva-Manchego, Fernando and
Camacho-Collados, Jose",
booktitle = "Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing",
month = dec,
year = "2022",
address = "Abu Dhabi, U.A.E.",
publisher = "Association for Computational Linguistics",
}
- An Empirical Comparison of LM-based Question and Answer Generation Methods, ACL 2023, Finding: The QAG models (code to reproduce experiments).
@inproceedings{ushio-etal-2023-an-empirical,
title = "An Empirical Comparison of LM-based Question and Answer Generation Methods",
author = "Ushio, Asahi and
Alva-Manchego, Fernando and
Camacho-Collados, Jose",
booktitle = "Proceedings of the 61th Annual Meeting of the Association for Computational Linguistics: Findings",
month = Jul,
year = "2023",
address = "Toronto, Canada",
publisher = "Association for Computational Linguistics",
}
- A Practical Toolkit for Multilingual Question and Answer Generation, ACL 2023, System Demonstration: The library and demo (code to reproduce experiments).
@inproceedings{ushio-etal-2023-a-practical-toolkit,
title = "A Practical Toolkit for Multilingual Question and Answer Generation",
author = "Ushio, Asahi and
Alva-Manchego, Fernando and
Camacho-Collados, Jose",
booktitle = "Proceedings of the 61th Annual Meeting of the Association for Computational Linguistics: System Demonstrations",
month = Jul,
year = "2023",
address = "Toronto, Canada",
publisher = "Association for Computational Linguistics",
}