这是武汉大学密码学大作业——利用gpu加速aes算法。
This is the cryptography final project of Wuhan University -- AES algorithm acceleration on GPU.
[TOC]
-
测试gpu: test_your_gpu.cu 编译后运行即可
-
测试计时函数:test_time.cu 编译后运行时需要输入要测试的函数(数字1-5,具体见源码)
-
生成测试用例:generate_input.cpp
-
标准AES:gpu.cu
-
T表:gpu_T.cu
-
多工作流:gpu_stream.cu
-
Stride Loops:gpu_loop.cu
-
ctr模式:gpu_ctr.cu
在命令行使用nvcc gpu_T.cu -o gpu.exe命令编译,使用.\gpu.exe input.txt运行。
需要input.txt文件作为输入,生成加密后文件cipher.txt和解密后文件output.txt。
GPU并不是一个独立运行的计算平台,而需要与CPU协同工作,可以看成是CPU的协处理器,因此当我们在说GPU并行计算时,其实是指的基于CPU+GPU的异构计算架构。在异构计算架构中,GPU与CPU通过PCIe总线连接在一起来协同工作,CPU所在位置称为为主机端(host),而GPU所在位置称为设备端(device),如下图所示。

可以看到GPU包括更多的运算核心,其特别适合数据并行的计算密集型任务,如大型矩阵运算,而CPU的运算核心较少,但是其可以实现复杂的逻辑运算,因此其适合控制密集型任务。另外,CPU上的线程是重量级的,上下文切换开销大,但是GPU由于存在很多核心,其线程是轻量级的。因此,基于CPU+GPU的异构计算平台可以优势互补,CPU负责处理逻辑复杂的串行程序,而GPU重点处理数据密集型的并行计算程序,从而发挥最大功效。

在CUDA中,host和device是两个重要的概念,我们用host指代CPU及其内存,而用device指代GPU及其内存。CUDA程序中既包含host程序,又包含device程序,它们分别在CPU和GPU上运行。同时,host与device之间可以进行通信,这样它们之间可以进行数据拷贝。典型的CUDA程序的执行流程如下:
- 分配host内存,并进行数据初始化;
- 分配device内存,并从host将数据拷贝到device上;
- 调用CUDA的核函数(kernel)在device上完成指定的运算;
- 将device上的运算结果拷贝到host上;
- 释放device和host上分配的内存。
kernel是在device上线程中并行执行的函数,CUDA中,每一个线程都要执行核函数,并且每个线程会分配一个唯一的线程号thread ID,这个ID值可以通过核函数的内置变量threadIdx来获得。
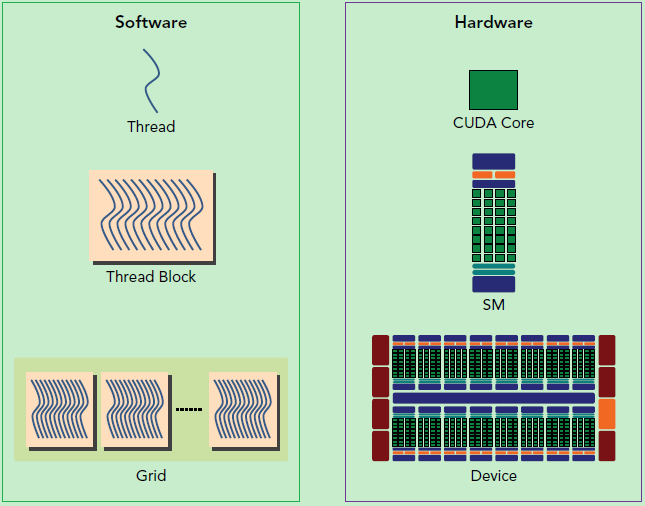
kernel在device上执行时实际上是启动很多线程,一个kernel所启动的所有线程称为一个网格(grid),同一个网格上的线程共享相同的全局内存空间,grid是线程结构的第一层次,而网格又可以分为很多线程块(block),一个线程块里面包含很多线程,这是第二个层次。

此外这里简单介绍一下CUDA的内存模型,如下图所示。可以看到,每个线程有自己的私有本地内存(Local Memory),而每个线程块有包含共享内存(Shared Memory),可以被线程块中所有线程共享,其生命周期与线程块一致。此外,所有的线程都可以访问全局内存(Global Memory)。还可以访问一些只读内存块:常量内存(Constant Memory)和纹理内存(Texture Memory)。

GPU硬件的一个核心组件是SM,SM是 Streaming Multiprocessor的缩写,翻译过来就是流式多处理器。SM的核心组件包括CUDA核心,共享内存,寄存器等,SM可以并发地执行数百个线程,并发能力就取决于SM所拥有的资源数。当一个kernel被执行时,它的gird中的线程块被分配到SM上,一个线程块只能在一个SM上被调度。SM一般可以调度多个线程块,这要看SM本身的能力。那么有可能一个kernel的各个线程块被分配多个SM,所以grid只是逻辑层,而SM才是执行的物理层。
SM采用的是SIMT(Single-Instruction, Multiple-Thread,单指令多线程)架构,基本的执行单元是线程束(wraps),线程束包含32个线程,这些线程同时执行相同的指令,但是每个线程都包含自己的指令地址计数器和寄存器状态,也有自己独立的执行路径。所以尽管线程束中的线程同时从同一程序地址执行,但是可能具有不同的行为,比如遇到了分支结构,一些线程可能进入这个分支,但是另外一些有可能不执行,它们只能死等,因为GPU规定线程束中所有线程在同一周期执行相同的指令,线程束分化会导致性能下降。当线程块被划分到某个SM上时,它将进一步划分为多个线程束,因为这才是SM的基本执行单元,但是一个SM同时并发的线程束数是有限的。这是因为资源限制,SM要为每个线程块分配共享内存,而也要为每个线程束中的线程分配独立的寄存器。所以SM的配置会影响其所支持的线程块和线程束并发数量。
总之,就是网格和线程块只是逻辑划分,一个kernel的所有线程其实在物理层是不一定同时并发的。所以kernel的grid和block的配置不同,性能会出现差异,这点是要特别注意的。还有,由于SM的基本执行单元是包含32个线程的线程束,所以block大小一般要设置为32的倍数。
逻辑结构计算如下图所示:

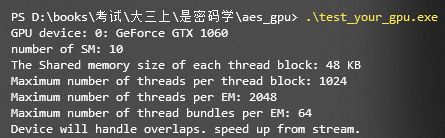
cuda版本为11.0和11.1,gpu型号如下所示:

选取一段cpu和gpu混合代码(这里选择的cuda samples里的vectorAdd),分别用五种不同的计时函数统计程序运行时间进行对比。五种计时函数如下:
- clock() 函数
- chrono库
- Windows API GetTickCount()
- Windows API QueryPerformanceCounter()
- CUDA计时
clock() 函数
- clock()返回类型为clock_t类型
- clock_t实际上为long类型, typedef long clock_t
- clock()函数,返回从 开启这个程序进程 到 程序中调用clock()函数 之间的CPU时钟计时单元(clock tick)数,返回单位为毫秒
- 可以使用常量CLOCKS_PER_SEC,这个常量表示每一秒有多少时钟计时单元
chrono库
c++11引入的新库,clock选择high_resolution_clock,这是拥有可用的最短嘀嗒周期的时钟。duration选择std::chrono::nanoseconds,这是64为有符号整数(纳秒),实际测试下没有达到纳秒级别,可能是程序或者硬件上有问题。
Windows API GetTickCount()
GetTickCount()是一个Windows API,所需头文件为<windows.h>。返回从操作系统启动到现在所经过的毫秒数(ms),精确度有限,跟CPU有关,一般精确度在16ms左右,最精确也不会精确过10ms。它的返回值是DWORD,当统计的毫妙数过大时,将会使结果归0,影响统计结果。
Windows API QueryPerformanceCounter()
QueryPerformanceCounter()是一个Windows API,所需头文件为<windows.h>。这个函数返回高精确度性能计数器的值,它可以以微妙为单位计时。但是QueryPerformanceCounter() 确切的精确计时的最小单位是与系统有关的,所以,必须要查询系统以得到QueryPerformanceCounter()返回的嘀哒声的频率。 QueryPerformanceFrequency() 提供了这个频率值,返回每秒嘀哒声的个数。
CUDA计时
CUDA中的事件本质上是一个GPU时间戳,值得注意的是,由于CUDA事件是直接在GPU上实现的,因此它们不适用于对同时包含设备(GPU)代码和主机(CPU)代码的混合代码计时。 也就是说,如果你试图通过CUDA事件对核函数和设备(GPU)内存赋值之外的代码进行计时,将得到不可靠的结果。
计时开始:
计时结束:

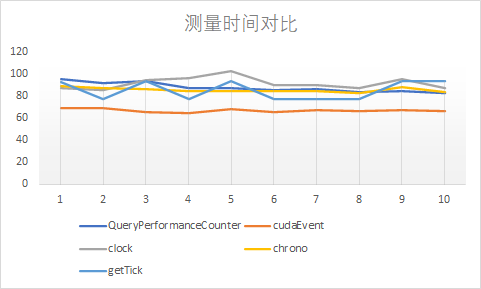
测量时间对比,中间代码为共计两千万次的加法运算:
方差和平均值对比:
| 方法 | 方差 | 平均值 |
|---|---|---|
| QueryPerformanceCounter | 20.67642 | 88.13518 |
| cudaEvent | 2.802127 | 67.20199 |
| clock | 29.21111 | 92.1 |
| chrono | 4.045949 | 85.80937 |
| getTick | 69.43333 | 85.9 |
结论:
在实际实验中,一共做了11次,去掉了第一次的结果,因为因为GPU第一次被调用时会消耗不定的时间来预热,所以会造成明显偏差,即使加上了warmup函数还是无法解决这个问题,于是去掉第一次计时结果。clock和getTick精度为毫秒级,其中getTick精确度在16ms左右,可以在上图中看到明显的波动;QueryPerformanceCounter和chrono可以到毫秒小数点后四位,cudaEvent可以精确到纳秒级。cudaEvent可能屏蔽了一些cpu操作,所以时间上要少一些。
查表法的核心**是将字节代换层、ShiftRows层和MixColumn层融合为查找表:每个表的大小是32 bits(4字节)乘以256项,一般称为T盒(T-Box)或T表。加密过程4个表(Te),解密过程4个表(Td),共8个。每一轮操作都通过16次查表产生。虽然一轮就要经历16次查表,但这都简化了计算操作和矩阵乘法操作,对于计算机程序而言,这是更快的。
列变换层可以使用如下矩阵表示,B为进行了行变换和S盒变换后的矩阵:
以第一列为例,可表示为:

所以,对应的本轮次输出的前四字节可写为如下表达式,其中$S(A_i)$是进行S盒变换,$W_{k0}$为本轮子密钥中的前四字节:
定义$Te_0$至$Te_3$四个表:
故每一轮操作可以转化为以下操作:
通过查询T表来代替AES每一轮的循环加密部分,每一轮次的加密操作可以通过16次查表和16次异或完成。

这不是一个优化,因为ecb模式并不安全,所以我们在ecb模式的基础上改写了ctr模式,没有明显的速度损失,所有的优化也都对ecb模式适用。
ecb模式的缺点在于同样的明文块会被加密成相同的密文块;因此,它不能很好的隐藏数据模式。在某些场合,这种方法不能提供严格的数据保密性,因此并不推荐用于密码协议中。下面的例子显示了ECB在密文中显示明文的模式的程度:该图像的一个位图版本(左图)通过ECB模式可能会被加密成中图,而非ECB模式通常会将其加密成右图。

每次加密时都会生成一个不同的值(nonce)来作为计数器的初始值。当分组长度为128比特(16字节)时,计数器的初始值可能是像下面这样的形式。

但是我们采用的是nonce+分组序号,state数组模拟了一个分组序号,如下图所示:

利用for循环模拟了一个分组加法:

在加密完成之后再对明文进行异或(展开for循环会更快,但是这个优化编译器应该可以直接做):

用到CUDA的程序一般需要处理海量的数据,内存带宽经常会成为主要的瓶颈。在Stream的帮助下,CUDA程序可以有效地将内存读取和数值运算并行,从而提升数据的吞吐量。
值得注意的是,很多利用gpu优化加密算法的文章都是不考虑CPU和GPU的数据交换的。
由于GPU和CPU不能直接读取对方的内存,CUDA程序一般会有一下三个步骤:
-
将数据从CPU内存转移到GPU内存
-
GPU进行运算并将结果保存在GPU内存
-
将结果从GPU内存拷贝到CPU内存
如果不做特别处理,那么CUDA会默认只使用一个Stream(Default Stream)。在这种情况下,刚刚提到的三个步骤就会串行,必须等一步完成了才能进行下一步。
如下图所示:

可以使用stream来加速数据读取的过程:
- 数据拷贝和数值计算可以同时进行。
- 两个方向的拷贝可以同时进行(GPU到CPU,和CPU到GPU),数据如同行驶在双向快车道。
但同时,这数据和计算的并行也有一点合乎逻辑的限制:进行数值计算的kernel不能读写正在被拷贝的数据。
基本的概念是:
-
将数据拆分称许多块,每一块交给一个Stream来处理。
-
每一个Stream包含了三个步骤:
-
将属于该Stream的数据从CPU内存转移到GPU内存,
-
GPU进行运算并将结果保存在GPU内存,
-
将该Stream的结果从GPU内存拷贝到CPU内存。
-
-
所有的Stream被同时启动,由GPU的scheduler决定如何并行。
执行结果如下图所示:

运算速度如下图所示,解密未使用stream加速:

在读入文件较小时,计算资源比较充足,这时多个stream可以并行计算:

但是速度反而会比不使用stream低(不是和解密对比,原始加密速度图没有放上来),可能是因为gpu资源没有被很好的利用:

参考:CUDA Pro Tip: Write Flexible Kernels with Grid-Stride Loops
一个Grid-Stride Loops的简单例子:
__global__
void add(int n, float *x, float *y)
{
int index = blockIdx.x * blockDim.x + threadIdx.x;
int stride = blockDim.x * gridDim.x;
for (int i = index; i < n; i += stride)
y[i] = x[i] + y[i];
}
其中blockDim.x和gridDim.x分别为block中的线程数量和grid中的block数量,这样以来,步长就是网格中的线程数量了。也就是说,这样去循环的话,假设网格中有1280个线程,那么线程0将会去计算成员0,1280,2560,等等。这就是为什么称之为Grid-Stride Loops。通过使用这种方式的循环,我们能够确保warp中的所有寻址都是单位步长,因此我们获得最大内存合并
grid-stride loop 的好处
-
可扩展性和线程复用
可扩展性是指,这种方法在理论上可以支持任意规模的并行计算,而不受设备提供的最大线程数限制;另外这种实现允许我们采用更合理的
GRIDSIZE,比如常推荐的,使用 multiprocessor 数量的倍数。线程复用则可以帮助程序省去线程启动与销毁的开销。 -
易于调试
当
GRIDSIZE与BLOCKSIZE都取 1 时程序实际退化为串行程序,这为调试提供了方便 -
可移植性与可读性
这种的写法可以轻易地修改为 CPU 代码
无loop复用,通过数据大小(numbytes)来确定GridSize(Grid中block的数量):

loop复用,灵活分配GridSize,使用 multiprocessor 数量的倍数,线程复用可以减少线程启动与销毁的开销:

在loop复用中,每个线程并不只负责一块数据,而是负责从 index 开始,stride 为步长的一组数据:

但是由于for循环同样会造成一定性能消耗,所以速度提升并不十分明显。
| 1K | 8K | 64K | 256K | 1M | 8M | 64M | 256M | 1G | |
|---|---|---|---|---|---|---|---|---|---|
| 标准AES | 0.013542 | 0.080709 | 0.574532 | 1.998942 | 4.558811 | 7.057882 | 8.15135 | 9.601574 | 9.311551 |
| T表 | 0.011335 | 0.077830 | 0.592553 | 1.538841 | 3.465513 | 6.086978 | 7.951356 | 6.590610 | 7.65414 |
| 多工作流 | 0.005618 | 0.032280 | 0.271411 | 0.970752 | 2.86876 | 9.736423 | 16.725221 | 17.952856 | 15.269693 |
| Stride Loops | 0.035037 | 0.207516 | 1.172966 | 3.622536 | 5.571409 | 7.230005 | 8.061637 | 9.36902 | 9.088143 |
| 初始AES | 0.014328 | 0.063005 | 0.488063 | 2.663895 | 4.191975 | 5.832871 | 6.411677 | 6.798704 | 6.637807 |

https://blog.csdn.net/sunbin0123/article/details/8578840
https://github.com/willstruggle/AES-accelerated-by-GPU-CUDA-
https://zhuanlan.zhihu.com/p/34587739
https://www.cnblogs.com/skyfsm/p/9673960.html
https://github.com/Canhui/AES-ON-GPU
https://zhuanlan.zhihu.com/p/99880204
https://blog.ailemon.me/2020/07/27/windows-install-cuda-and-cudnn-environment/
https://blog.csdn.net/xu_benjamin/article/details/86770974 https://zhuanlan.zhihu.com/p/84509270