![]()
👋 Overview | 📖 Benchmarking | ⚙️ Setup | 🚀 Usage | 🔎 Citation | 📄 License
📬 Contact: libowen.ne@gmail.com, chao.peng@acm.org
📝 Check out our paper HERE !
-
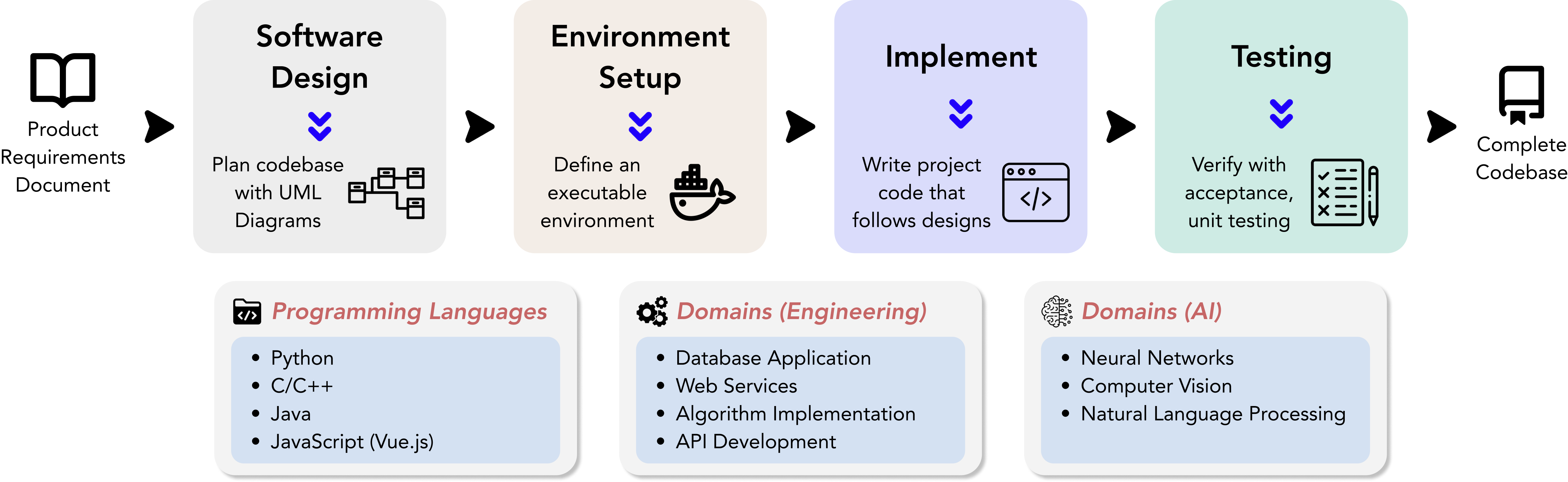
DevBench is a comprehensive benchmark designed to evaluate LLMs across various stages of the software development lifecycle, including software design, environment setup, implementation, acceptance testing, and unit testing. By integrating these interconnected steps under a single framework, DevBench offers a holistic perspective on the potential of LLMs for automated software development.
-
The DevBench dataset comprises 22 curated repositories across 4 programming languages (Python, C/C++, Java, JavaScript), covering a wide range of domains such as machine learning, databases, web services, and command-line utilities.
-
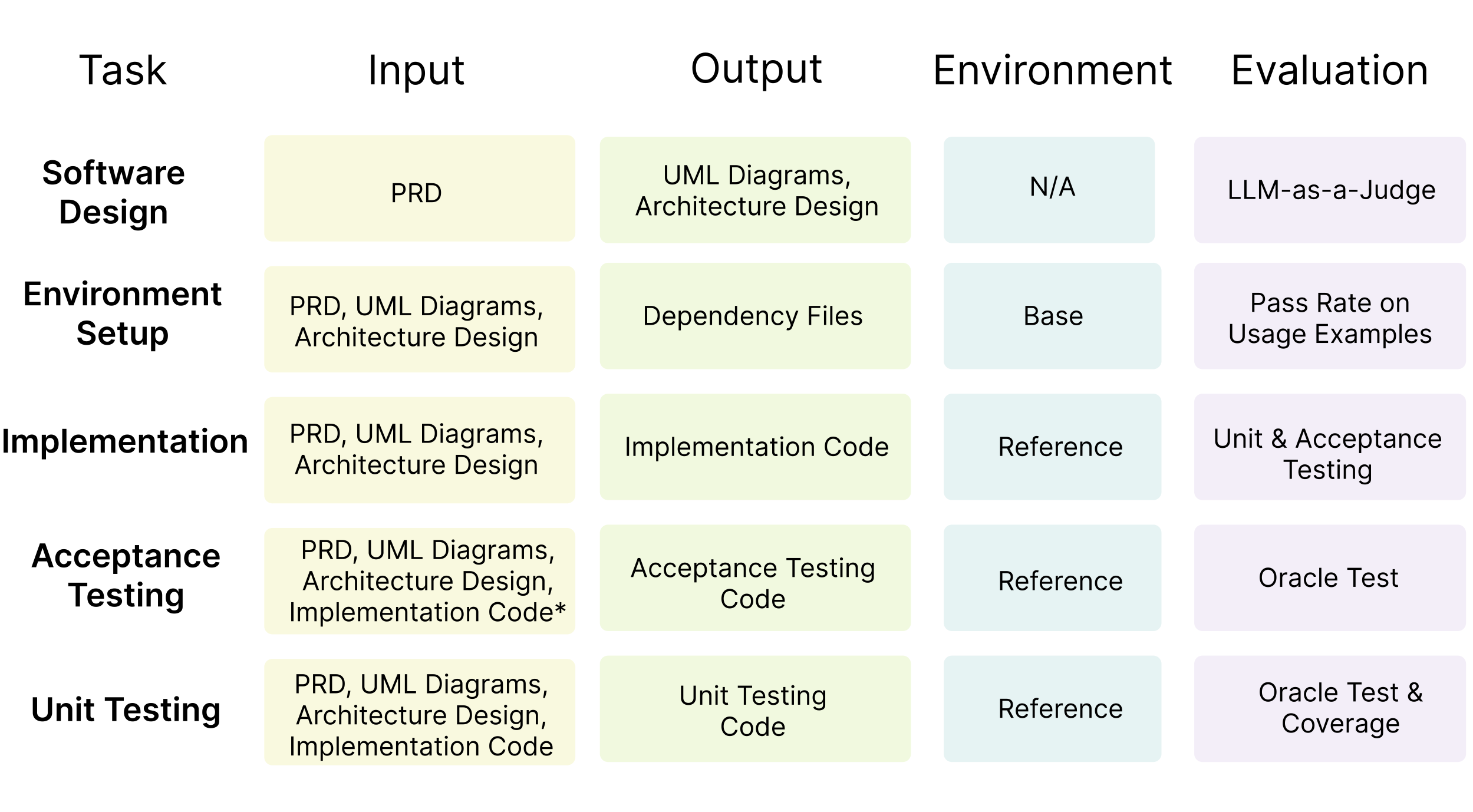
DevBench includes a comprehensive and automatic evaluation suite for all tasks involved. We provide extensive acceptance and unit test cases for the implementation task 🤗. Additionally, we utilize LLM-as-a-Judge for evaluating the software design task 👩🏽⚖️. Further details on our task specifications can be found here.
-
We have developed a baseline agent system based on the popular multi-agent software development system, ChatDev. Special thanks to our collaborators at ChatDev!


| Model | Environment Setup | Implementation | Acceptance Testing | Unit Testing | ||
|---|---|---|---|---|---|---|
| Pass@ Example Usage§ | Pass@ Accept. Test¶ | Pass@ Unit Test¶ | Oracle Test§ | Oracle Test§ | Coverage$ | |
| GPT-3.5-Turbo | 33.3 | 4.2 | 4.3 | 11.7 | 28.7 | 24.6(61.4) |
| GPT-4-Turbo-1106 | 41.7 | 6.9 | 6.8 | 25.9 | 33.6 | 36.7(66.7) |
| GPT-4-Turbo-0125 | 41.7 | 7.1 | 8.0 | 29.2 | 36.5 | 33.2(66.3) |
| CodeLlama-7B-Instruct | 8.3 | 0.0 | 0.0 | 0.0 | 3.0 | 3.6(71.0) |
| CodeLlama-13B-Instruct | 25.0 | 0.6 | 0.0 | 0.0 | 5.1 | 8.6(57.6) |
| CodeLlama-34B-Instruct | 16.7 | 0.6 | 0.5 | 4.5 | 21.1 | 25.4(72.6) |
| DeepSeek-Coder-1.3B-Instruct | 8.3 | 0.0 | 0.1 | 0.0 | 5.6 | 2.7(27.0) |
| DeepSeek-Coder-6.7B-Instruct | 25.0 | 2.9 | 3.9 | 20.5♡ | 23.5 | 28.2(70.6) |
| DeepSeek-Coder-33B-Instruct | 16.7 | 4.4 | 5.5 | 13.6 | 32.8 | 35.7(79.4) |
The code for the software design evaluation can be found here👩🏽⚖️.
| Model | w/ Tie | w/o Tie | ||
|---|---|---|---|---|
| General Principles† | Faithfulness‡ | General Principles | Faithfulness | |
| GPT-4-Turbo-0125 | 97.9 | 97.9 | 100.0 | 100.0 |
| GPT-4-Turbo-1106 | 91.7 | 85.4 | 100.0 | 100.0 |
| CodeLlama-7B-Instruct | 4.2 | 8.3 | 4.2 | 4.5 |
| CodeLlama-13B-Instruct | 18.8 | 14.6 | 10.5 | 5.3 |
| CodeLlama-34B-Instruct | 39.6 | 33.3 | 33.3 | 21.4 |
| DeepSeek-Coder-1.3B-Instruct | 16.7 | 16.7 | 5.5 | 5.6 |
| DeepSeek-Coder-6.7B-Instruct | 35.4 | 35.4 | 31.6 | 29.4 |
| DeepSeek-Coder-33B-Instruct | 52.1 | 50.0 | 53.8 | 50.0 |
| Agree w/ Human Majority | 60.4 | 51.6 | 79.2 | 83.2 |
For a secure and isolated environment, we offer Docker support for DevBench. Please refer to our detailed Installation Guide.
Add your DevBench directory to your PYTHONPATH variable.
export PYTHONPATH="${PYTHONPATH}:${path_to_devbench}"
For running the benchmark_data/java/Actor_relationship_game repo, configure your TMDB key.
export TMDB_API_KEY=${your_TMDB_key}
Set your OpenAI API key as an environment variable.
export OPENAI_API_KEY="your_OpenAI_API_key"
For deploying open source models, please refer to lmdeploy or vllm.
After the deployment, please configure the IP address in open_source_model.json.
For codellama and deepseek-coder models, which are integrated into our experiments, simply fill in the IP address in {"model_name": $model_ip_address}.
For example:
{
"codellama-7b-instruct": "",
"codellama-13b-instruct": "",
"codellama-34b-instruct": "",
"deepseek-coder-1.3b-instruct": "",
"deepseek-coder-6.7b-instruct": "",
"deepseek-coder-33b-instruct": "$model_ip_address"
}
For additional models, add a new field as shown below.
{
"customized-model": {"$model_name": "$model_ip_address"}
}
cd agent_sysyem/baseline
python run.py --config Implementation --input_path ../../benchmark_data/python/TextCNN/ --model gpt-4-turbo-new --model_source openai --review execution --evaluate
- config (str) - Specifies the task in the DevBench:
SoftwareDesign|EnvironmentSetup|Implementation|AcceptanceTesting|UnitTesting. - input_path (str) - Specifies the repo path.
- project_name (str) - Specifies the repo name. If empty, defaults to the last segment of
input_path(i.e.,input_path.split('/')[-1]) - model (str) - Specifies the name of the language model:
gpt-3.5-turbo|gpt-4|gpt-4-32k|gpt-4-turbo|claude-2|claude-2.1|codellama-7b|codellama-13b|codellama-34b|deepseek-coder-1.3b|deepseek-coder-6.7b|deepseek-coder-33b|customized-model. - customized_model_name (Optional, str) - Specifies the custom model name if the value of the
modelparameter iscustomized-model. - model_source (str) - Specifies the model type, open source model or openai closed source model :
open_source|openai - review (str) - Specifies the review mode:
none|normal|execution.none: a single forward pass of Coding.normal: Coding and CodeReview in alternation, with CodeReview lacking program execution feedback.execution: Coding and CodeReview in alternation, with CodeReview including program execution feedback.
- read_src_code (bool) - Whether to read source code in the AcceptanceTesting and UnitTesting tasks.
- evaluate (bool) - Whether to evaluate in the end. The evaluation for the software design can be found here.
- temperature (float) - temperature
- top_p (float) - top_p
When you use normal review and execution review, the cyclenum parameter of CompanyConfig/{task_name}/ChatChainConfig.json can be specified as the number of rounds of review. The default is 2.
@article{li2024devbench,
title={DevBench: A Comprehensive Benchmark for Software Development},
author={Li, Bowen and Wu, Wenhan and Tang, Ziwei and Shi, Lin and Yang, John and Li, Jinyang and Yao, Shunyu and Qian, Chen and Hui, Binyuan and Zhang, Qicheng and others},
journal={arXiv preprint arXiv:2403.08604},
year={2024}
}
- Source Code Licensing: Our project's source code is licensed under the Apache 2.0 License. This license permits the use, modification, and distribution of the code, subject to certain conditions outlined in the Apache 2.0 License.
- Data Licensing: The related data utilized in our project is licensed under CC BY 4.0, which allows anyone to copy, distribute, transmit, adapt and make commercial use of the dataset.