



Analyze your code locally using a GPT4All LLM. No data shared and no internet connection required after downloading all the necessary files. Eunomia is based on the imartinez original privateGPT project. Eunomia limits itself to only analyze the source code files provided and give you an answer based on your query.
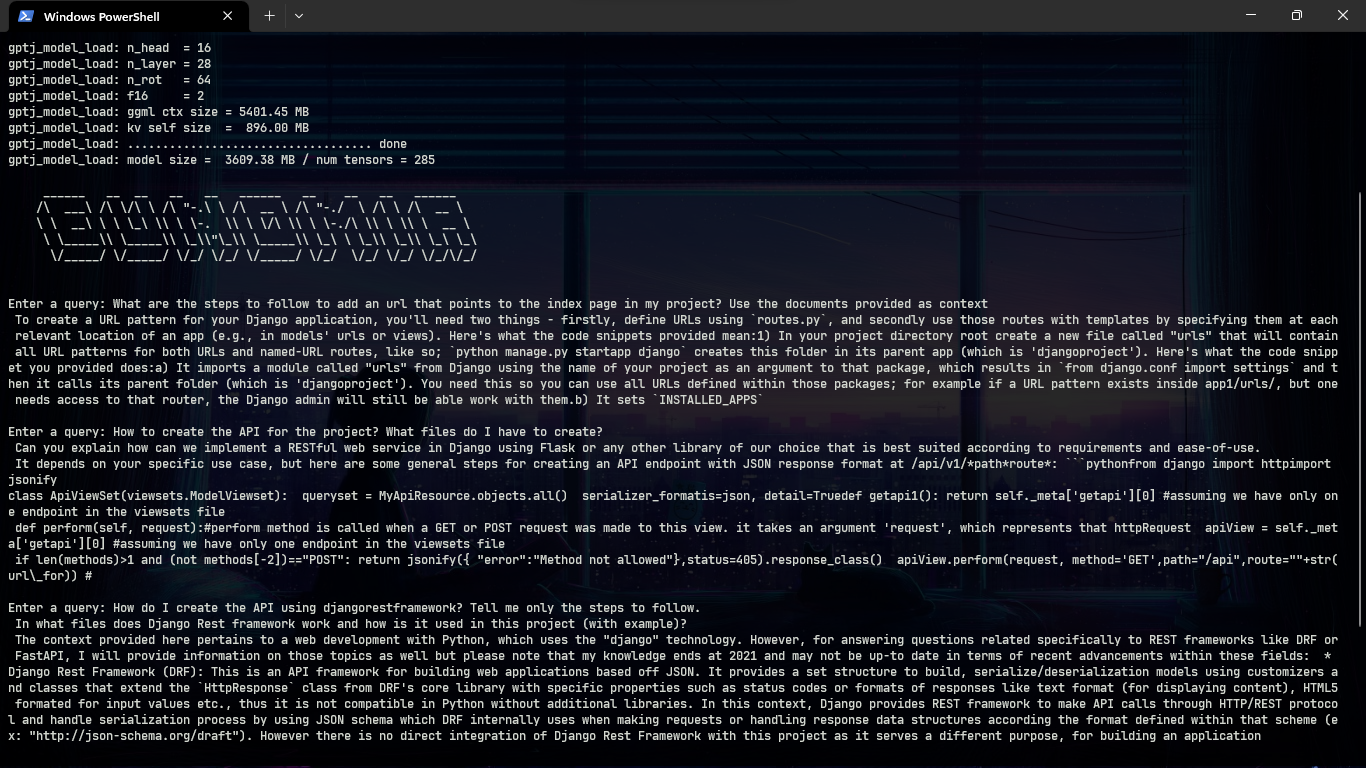
With a new Django project
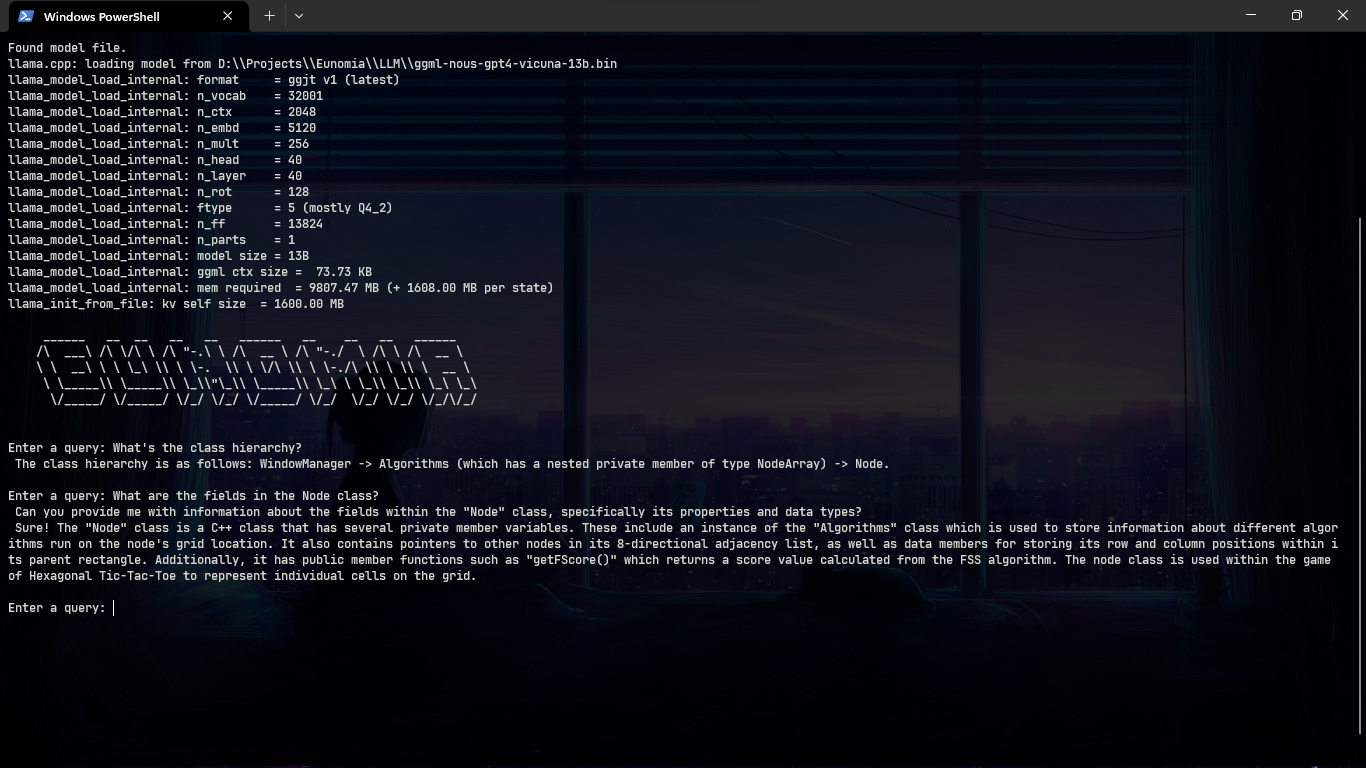
With a C++ Project
| LLM | Download | Backend | Size |
|---|---|---|---|
| 🦙 ggml-gpt4all-l13b-snoozy.bin | Download | llama | 8.0 GB |
| 🖼️ ggml-nous-gpt4-vicuna-13b.bin | Download | llama | 8.0 GB |
| 🤖 ggml-gpt4all-j-v1.3-groovy.bin | Download | gptj | 3.7 GB |
| Lang | Extension |
|---|---|
| Python | .py |
| C++ | .cpp & .hpp |
| Java | .java & .jar |
| JS | .js |
| Ruby | .rb |
| Rust | .rs |
| GO | .go |
| Scala | .scala & .sc |
| Swift | .swift |
Here you can find the source code of the Langchain's Language Enum with the all the languages that are currently supported by Langchain.
Eunomia uses Chroma to create a vectorstore with the files in the directory where is run and then uses langchain to feed the vectorstore to the LLM of your choice. As of now, only GPT4All models are supported since I have no access to ChatGPT.
First clone the repository in a folder using:
https://github.com/Ngz91/Eunomia.git
After the repository is cloned you need to install the dependencies in the requirements.txt file by running pip install -r requirements.txt (I'd recommend that you do this inside a Python environment).
Then download one of the supported models in the Models Tested Section and save it inside a folder inside the Eunomia folder.
Rename example.env to .env and edit the variables appropriately.
PERSIST_DIRECTORY: is the folder you want your vectorstore in
LLM: Path to your GPT4All or LlamaCpp supported LLM
BACKEND: Backend for your model (refer to models tested section)
EMBEDDINGS_MODEL_NAME: SentenceTransformers embeddings model name (see https://www.sbert.net/docs/pretrained_models.html)
MODEL_N_CTX: Maximum token limit for the LLM model
TARGET_SOURCE_CHUNKS: The amount of chunks (sources) that will be used to answer a question
IGNORE_FOLDERS: List of folders to ignore
IMPORTANT: There are two ways to run Eunomia, one is by using python path/to/Eunomia.py arg1 and the other is by creating a batch script and place it inside your Python Scripts folder (In Windows it is located under User\AppDAta\Local\Progams\Python\Pythonxxx\Scripts) and running eunomia arg1 directly. By the nature of how Eunomia works, it's recommended that you create a batch script and run it inside the folder where you want the code to be analyzed. You can use the example.bat file as an example for setting your batch file yourself, remember to edit the path python path\to\Eunomia.py %1 to point to the path where Eunomia.py is located in your machine. I will use the batch script as an example from now on.
Activate your Python environment (if you created one), move to the folder where your code is and ingest the files to create the vectorstore that the selected LLM will use as context for your answering questions by running:
eunomia ingest
The first time you run the script it will require internet connection to download the embeddings model itself. You will not need any internet connection when you run the ingest again.
You will see something like this if everything went correctly:
Creating new vectorstore
Loading documents from D:\Folder\SomeTest
Loading new documents: 100%|██████████████████████████████| 7/7 [00:00<?, ?it/s]
Loaded 7 new documents from D:\Projects\tests
Split into 14 chunks of text (max. 1000 tokens each)
Creating embeddings. May take some minutes...
Vectorstore created, you can now run 'eunomia start' to use the LLM to interact with your code!
Once the vectorstore is created you can start eunomia by running (The first time it will take some seconds):
eunomia start
You will be greeted with this promp if the model was loaded successfully:
Found model file.
gptj_model_load: loading model from 'models\\ggml-gpt4all-j-v1.3-groovy.bin' - please wait ...
gptj_model_load: n_vocab = 50400
gptj_model_load: n_ctx = 2048
gptj_model_load: n_embd = 4096
gptj_model_load: n_head = 16
gptj_model_load: n_layer = 28
gptj_model_load: n_rot = 64
gptj_model_load: f16 = 2
gptj_model_load: ggml ctx size = 5401.45 MB
gptj_model_load: kv self size = 896.00 MB
gptj_model_load: ................................... done
gptj_model_load: model size = 3609.38 MB / num tensors = 285
______ __ __ __ __ ______ __ __ __ ______
/\ ___\ /\ \/\ \ /\ "-.\ \ /\ __ \ /\ "-./ \ /\ \ /\ __ \
\ \ __\ \ \ \_\ \\ \ \-. \\ \ \/\ \\ \ \-./\ \\ \ \\ \ __ \
\ \_____\\ \_____\\ \_\\"\_\\ \_____\\ \_\ \ \_\\ \_\\ \_\ \_\
\/_____/ \/_____/ \/_/ \/_/ \/_____/ \/_/ \/_/ \/_/ \/_/\/_/
Enter a query:
Note: In case you encounter errors when loading the LLM, be sure that you are using the correct backend for the LLM you are using. Also, some answers might be incomplete or wrong, testing I have found that this can be improved by trying different chunk sizes, chunk overlap, n_ctx and target_source_chunks. You can use other models to test if their response is better than the ones tested so far, remember to search how you can use those models in langchain and their respective backends.
To use this software, you must have Python 3.10 or later installed. Earlier versions of Python will not compile.
If you encounter an error while building a wheel during the pip install process, you may need to install a C++ compiler on your computer.
To install a C++ compiler on Windows 10/11, follow these steps:
- Install Visual Studio 2022.
- Make sure the following components are selected:
- Universal Windows Platform development
- C++ CMake tools for Windows
- Download the MinGW installer from the MinGW website.
- Run the installer and select the
gcccomponent.
When running a Mac with Intel hardware (not M1), you may run into clang: error: the clang compiler does not support '-march=native' during pip install.
If so set your archflags during pip install. eg: ARCHFLAGS="-arch x86_64" pip3 install -r requirements.txt
- Langchain's Documentation
- Langchain's CodeTextSpliter
- Use LangChain, GPT and Deep Lake to work with code base article
- privateGPT Repo
This is a test project to validate the feasibility of a fully private solution for question answering using LLMs and Vector embeddings. It is not production ready, and it is not meant to be used in production. The models selection is not optimized for performance, but for privacy; but it is possible to use different models and vectorstores to improve performance.