Cache-anno
简体中文 | English
自动缓存方法数据注解
基于AOP注解实现的自动缓存注解,支持Redis和本地缓存,用最简单的方式来读写缓存数据
本仓库包含以下内容:
- @Cache注解一个
- 对指定方法进行自动缓存
- 可对不存在的数据进行自动空缓存,并发下防止缓存穿透
- 可开启获取缓存时自动进行互斥锁,防止缓存击穿保护DB
内容列表
背景
cache-anno 是为了解决冗余redis查询和写入问题
这个仓库的目标是:
- 减少冗余代码, 无感对缓存数据进行读写。
- 减少手动编码犯错, 内置可选防缓存击穿\穿透功能。
- 减少工作量, 早点下班回家吃饭嗷嗷嗷~
功能类似Spring-cache,但是我普信男一次,我觉得本库比Springcache的好用很多,首先Spring-cache的不支持给每次写入的key单独设置过期时间,这个已经劝退我了;然后EL表达式上手成本也很高,但是它实现的功能是很简单的无感功能,我觉得这和Spring本身的约定大于配置相违背,相反呢本库提供四种类型(下面介绍)让你遵循约定减少配置,最简单只需要提供prefix就可以使用。Spring-cache也不支持批量查询过程中只查询增量数据,也不支持空缓存,也不支持防击穿.....
安装导入
本库已经上架maven**仓库,已经引入到自己项目pom文件中就行,请注意直接在mvnrepository会出现很多2.0.0以下的版本,请不要使用,那...那...是我上架的是做测试不小心发到release上的debug版本。
Maven
<!-- https://mvnrepository.com/artifact/cn.someget/cache-anno -->
<dependency>
<groupId>cn.someget</groupId>
<artifactId>cache-anno</artifactId>
<version>2.0.0</version>
</dependency>Gradle
// https://mvnrepository.com/artifact/cn.someget/cache-anno
implementation group: 'cn.someget', name: 'cache-anno', version: '2.0.0'导入jar包就好了,除此之外无需为本库做任何配置,所有bean也已经spring.factories暴露出来,可以直接被启动类扫描到。
使用说明
一. 注意事项
-
导入本库后配置中必须要有redis相关的配置,支持jedis和lettuce,只要spring自动装配或者你手动装配一个redisTemplate就行,不然无法使用本库。
-
使用注解存入的数据,序列化方式均为String,当然注解自动读数据反序列化也是String,所以如果你有使用注解存入数据,但是不适用注解读取数据的需求,请使用String反序列化读取。
-
所有redis的io异常都已经捕获,有异常只会打日志,不会影响你的业务,不会影响你的数据读取,兜底会走db查询。
二. 使用方法
- 入门使用以及原理
// 建议prefix定义成常量,便于复用, one to one可以不用传clazz参数
@Cache(prefix = "user:info:%d")
public UserInfoBO getIpUserInfo(Long uid) {
UserInfo userInfo = userInfoMapper.selectByUid(uid);
if (userInfo == null) {
return null;
}
UserInfoBO bo = new UserInfoBO();
BeanUtils.copyProperties(userInfo, bo);
return bo;
}上述方法如果没有加@Cache注解,就是一个简单从用户表中根据uid查询用户信息的方法,但是加了@Cache后它还是这么一个简单方法。只不过查询之前会根据注解中的prefix拼接上入参uid从Redis中尝试获取数据,如果没有数据则执行方法,执行完方法再自动写入缓存。那么下次在执行这个方法的时候,又会执行上面步骤prefix拼接入参尝试从Redis获取数据,但是因为上次自动写入了,所以拿到数据就直接返回了,不会再执行方法走DB查询了。
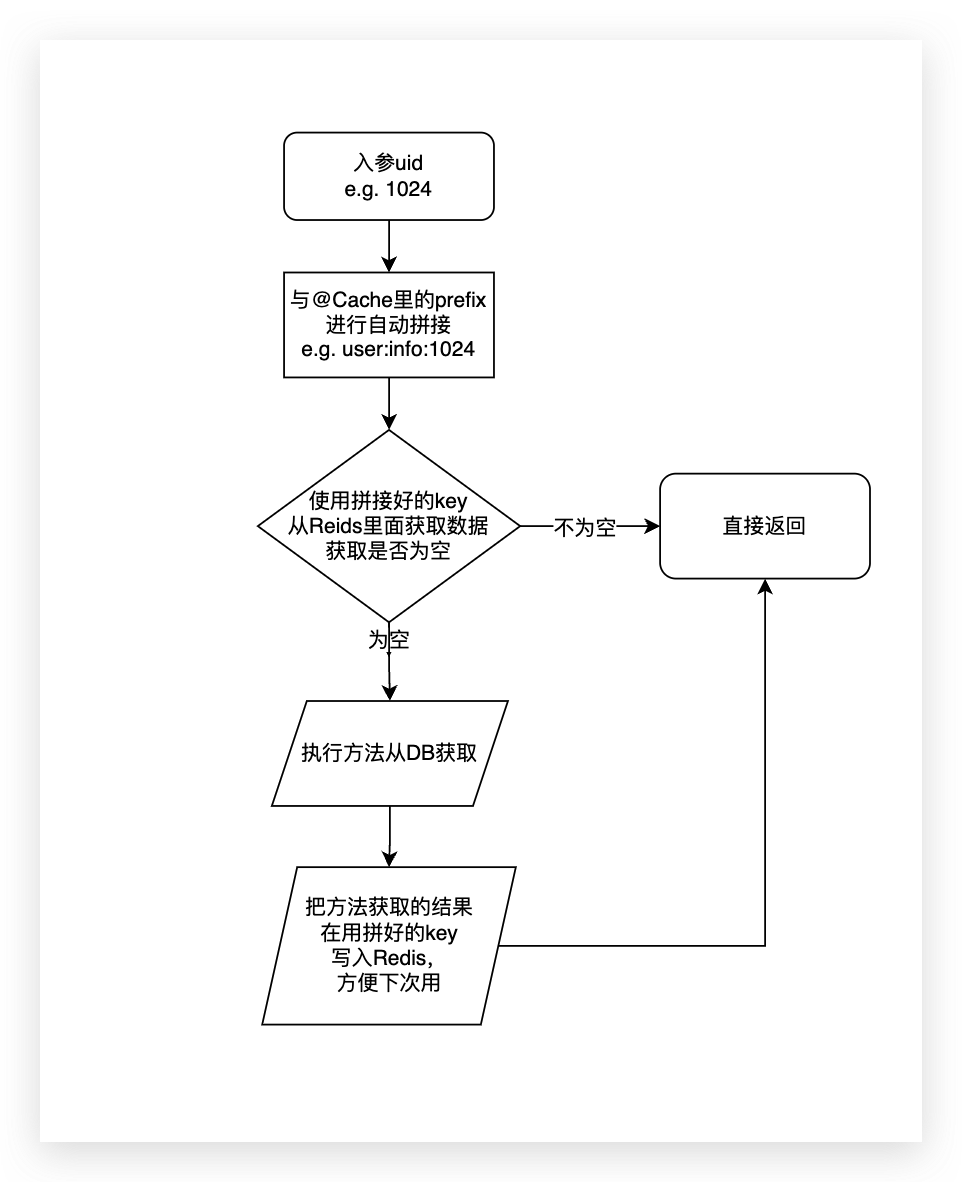
- 进阶理解
// 返回值是集合类型,clazz必须要传
@Cache(prefix = "mall:item:%d", clazz = MallItemsBO.class)
public Map<Long, MallItemsBO> listItems(List<Long> itemsIds) {
BaseResult<List<MallItemsDTO>> result = itemsRemoteClient.listItems(new ItemsReqDTO());
if (result == null || CollectionUtils.isEmpty(result.getData())) {
return Collections.emptyMap();
}
return result.getData().stream()
.map(mallItemsDTO -> {
MallItemsBO mallItemsBO = new MallItemsBO();
BeanUtils.copyProperties(mallItemsDTO, mallItemsBO);
return mallItemsBO;
}).collect(Collectors.toMap(MallItemsBO::getItemId, Function.identity()));
}上述方法如果没有加@Cache注解,就是一个批量通过itemId从其他服务远程获取item详细信息的方法,但是加了@Cache它还是这么一个方法,只不过查询之前会通过把入参所有的itemId进行和注解里面的prefix拼接,然后批量一次性尝试从redis里面获取,如果所有itemId都获取到则直接返回,但是如果有未命中的itemId则会把这未命中的itemId再统一走方法进行远程获取最后和Redis里面的汇总(远程获取完 会自动写入)

三. 所有支持的方法类型
| 类型 | prefix | 入参 | 出参 | 备注 |
|---|---|---|---|---|
| one to one | 自定义:占位符 | 包装类型或者String | ? extends Object | 有几个入参就要有几个占位符,不然无法使用 |
| ont to list | 自定义:占位符 | 包装类型或者String | List<? extends Object> | 同上,理论上来说List和object对于本库是一个东西,因为我是用的是String的序列化,相同理解就好。 |
| list to map_one | 自定义:占位符 | List<包装类型或者String> | Map<对应入参包装类型或者String, ? extends Object> | 如果是批量查询,第一个入参一定要是对应的查询List。list里面的每一个元素都会与prefix拼接,所以prefix的占位符是List里面的元素对应的占位符。 |
| list to map_map | 自定义:占位符 | List<包装类型或者String> | Map<对应入参包装类型或者String, List<? extends Object>> | 本类型其实也同上,上类型List中每一个元素对应的是一个对象,这个类型List每个元素对应的是一个list,我反序列化都是以一样的,所以本质一样。 因为java的泛型擦除的限制我无法判断Map的value泛型具体是什么, 请@Cache中的参数hasMoreValue需要设置成true,请切记 |
其中占位符要注意,如果是String占位符要%s,整型占位符%d,浮点型占位符%f 详情请参考这里
其实总的来说就是分为两类,入参是对象或者List,也就是单个获取和批量获取,如果是批量获取的话切记List要在一号位,并且方法入参不能超过两个,否则会报错提示不支持。
三. 注解里面的参数含义
| 名称 | 含义 | 备注 |
|---|---|---|
| prefix | Redis中key的前缀, | 注意要使用占位符,如入参是long, 占位符就是prefixKey:%d |
| expire | 过期时间(单位秒) | 如果使用注解的时候不设置则默认10分钟,注意本库写入缓存都有过期时间,因为我想不到你为啥要不设置TTL |
| missExpire | 空缓存过期时间(单位秒) | 如果是0则表示不开启空缓存(默认是0),空缓存过期时间表示如果从db也没查到生成空缓存到Redis,这个空缓存的过期时间(肯定正常缓存短,推荐3-10秒) |
| hasMoreValue | 是否list to map_map类型 | 因为java的泛型擦除的限制我无法判断Map的value泛型具体是什么, 请@Cache中的参数hasMoreValue需要设置成true,请切记 |
| clazz | 集合类返回值对应类型 | 如果返回值是List或者Map,这个必传,因为java泛型擦除我不知道你集合泛型,反序列化需要使用。如果是one to one类型的话,这个可以省略。 |
| usingLocalCache | 是否使用本地缓存 | 设置true以后从Redis读取之前会查询一遍本地缓存(使用caffeine),同理拿完数据也会回写到caffeine |
四. 其他功能详细说明
启用空缓存写入
@Cache含有missExpire的属性,属性含义是DB中不存在的值的过期时间(单位是秒),默认值是0,如果是0则表示如果查询的值DB中不存在的话,不进行空缓存处理。如果是非0,那么从Redis中查询值未命中会走方法查询,方法查询返回结果也是不存在那么会储存一个空值(如果是对象的是"{\"id\":-1}",如果是集合则是[]),过期时间是missExpire这个值(推荐3-10秒左右),支持上述表格中的所有类型。
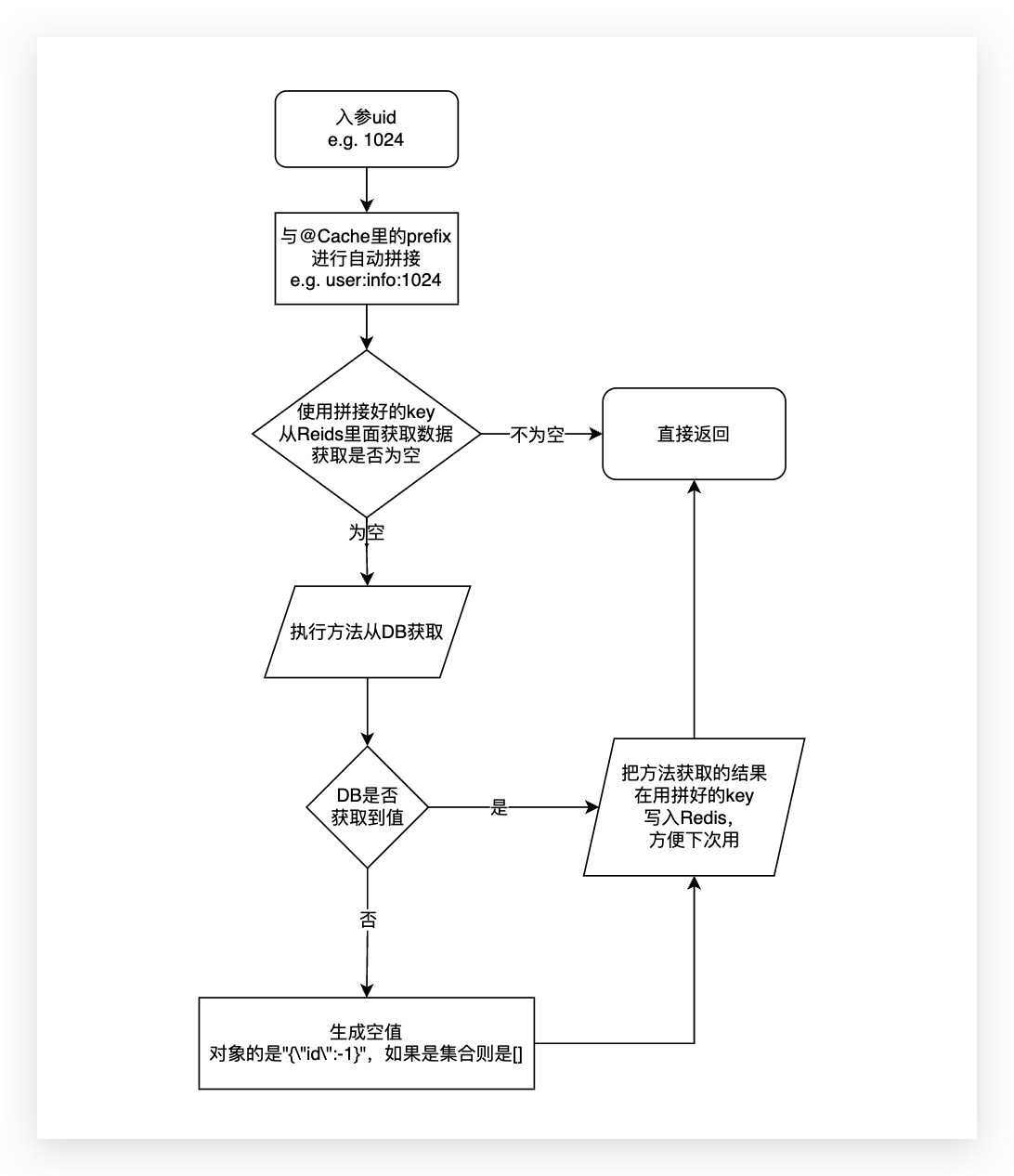
注意:
- 开启空缓存以后插入记录后也要进行删除缓存处理,因为可能对应值DB中已经有了,但是Redis还存在空值正处于TTL中。
- ~~空缓存如果是对象是会缓存id为-1的对象,如果是集合会缓存一个空集合,id为-1的对象不会返回给方法调用方,会直接被过滤掉,符合大家编码习惯。**要注意的是缓存对象必须要有id字段(Integer和Long都可以),否则无法过滤会返回的一个所有属性都是null的空对象。**~~2.0.1版已经支持设置对象空缓存为
"{}"所以不用必须含有id字段了,如果命中空缓存方法调用方拿到的是null,符合大家编码习惯,但是所有空缓存对象一定要有无参构造,否则反序列化无法生成空对象。
启用本地缓存
@Cache含有usingLocalCache的属性,属性含义是是否启用本地缓存,在一些场景下电商营销域要频繁通过RPC获取商品域的商品数据,因为营销场景QPS非常高,即便在RPC之前有一层Redis,但是频繁获取商品导致Redis的QPS非常高。而商品数据是不怎么变化的,所以在Redis之前再加一层本地缓存就显得非常有必要,Redis的QPS能降低不少。
有不少场景进行本地缓存提升都非常大,本库也支持进行本地缓存,只需使用注解是把usingLocalCache的属性设置为true(默认是false),本库使用的本地缓存是最近风头压过guava的caffeine,这样获取数据之前先从本地缓存进行查询,如果本地缓存没有命中则再去查询Redis。
注意:多层缓存会增加Cache-DB不一致可能,一定程度抗流可以用,但是不要过分依赖,这里本地缓存默认TTL是3秒,暂时不支持修改。
下一步计划(划线表示完成)
- 完善单测, 欢迎大家放心pr
目前如果开启存储空缓存, 读取未命中key时会把空缓存返回, 需要调用方法再过滤一下, 我思考一下是不是应该在切面就直接过滤(2.0.1)版本已经支持如果是命中对象空缓存方法调用方拿到的值是null而不是空缓存,不用再业务代码再进行空缓存判断,集合空缓存依然会返回空List。- 防止缓存击穿已经有好的方案, 下个版本迭代进去
- 使用注解对缓存进行逐出
维护者
如何贡献
非常欢迎你的加入!提一个 Issue 或者提交一个 Pull Request。
标准 Readme 遵循 Contributor Covenant 行为规范。
贡献者
等有了100个start才能显示,明示
使用许可
MIT © Oreoft