For Population Infinite Fall 2019
This tutorial will walk you through how to use text based machine-learning models to generate text in the style of some existing source text.
In this tutorial, we will do the following:
- Run an existing pre-trained RNN model to generate some text, and see the output.
- Learn at a high level what a Recurrent Neural Network is and how it is used.
- Learn how to train our own models based on a custom text corpus.
- Learn how to gather text for that corpus to train on.
First, we will run a model trained on Shakespeare text to generate some text that sounds like Shakespeare, using the code from the TensorFlow.js lstm text generation example, which illustrates how to use and train a LSTM model to generate random text based on the patterns in a text corpus such as Shakepeare or your own Facebook Posts.
On mac, if you don't have homebrew installed, install it with:
/usr/bin/ruby -e "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install)"
Then install yarn:
brew install yarn
On windows, follow the instructions here to install yarn
Download the code from this repository:
git clone https://github.com/oveddan/ml-text.git
Go into the code folder:
cd ml-text
Install the dependencies:
yarn
Now, let's generate some text:
yarn gen shakespeare.txt shakespeare \
--genLength 250 \
--temperature 0.6
What the above command did, was use an LSTM model trained on the text in data/shakespeare.txt to generate some text of length 250, that the model predicted which characters should come after some random text. Everything is run on your computer using Tensorflow.js in Node.
Internally, this ran the code in gen_node.js, so refer to that file to get a better sense of how to load an lstm model and generate text.
Runway.ml can be used to generate text using gpt-2, a state of the art text generation model.
If Runway is running, and gpt-2 is active, the script below can be run:
node gen_text_gpt2.js "Everybody betrayed me. I'm fed up with this world."
Check out the code in gen_text_gpt2.js to see how this works.
Which will generate text with the prompt "Everybody betrayed me. I'm fed up with this world."
An LSTM is a type of Recurrent Neural Network, which is a type of machine learning model designed to work with sequences of information.

What makes Recurrent Networks so special? A glaring limitation of Vanilla Neural Networks (and also Convolutional Networks) is that their API is too constrained: they accept a fixed-sized vector as input (e.g. an image) and produce a fixed-sized vector as output (e.g. probabilities of different classes).
~ Andrej Karpathy in The Unreasonable Effectiveness of Recurrent Neural Networks
Some examples of types of RNNs:
Text translation, where a sequence of words from one language is translated into a sequence of words in another language:

Melody generation with Melody RNN:
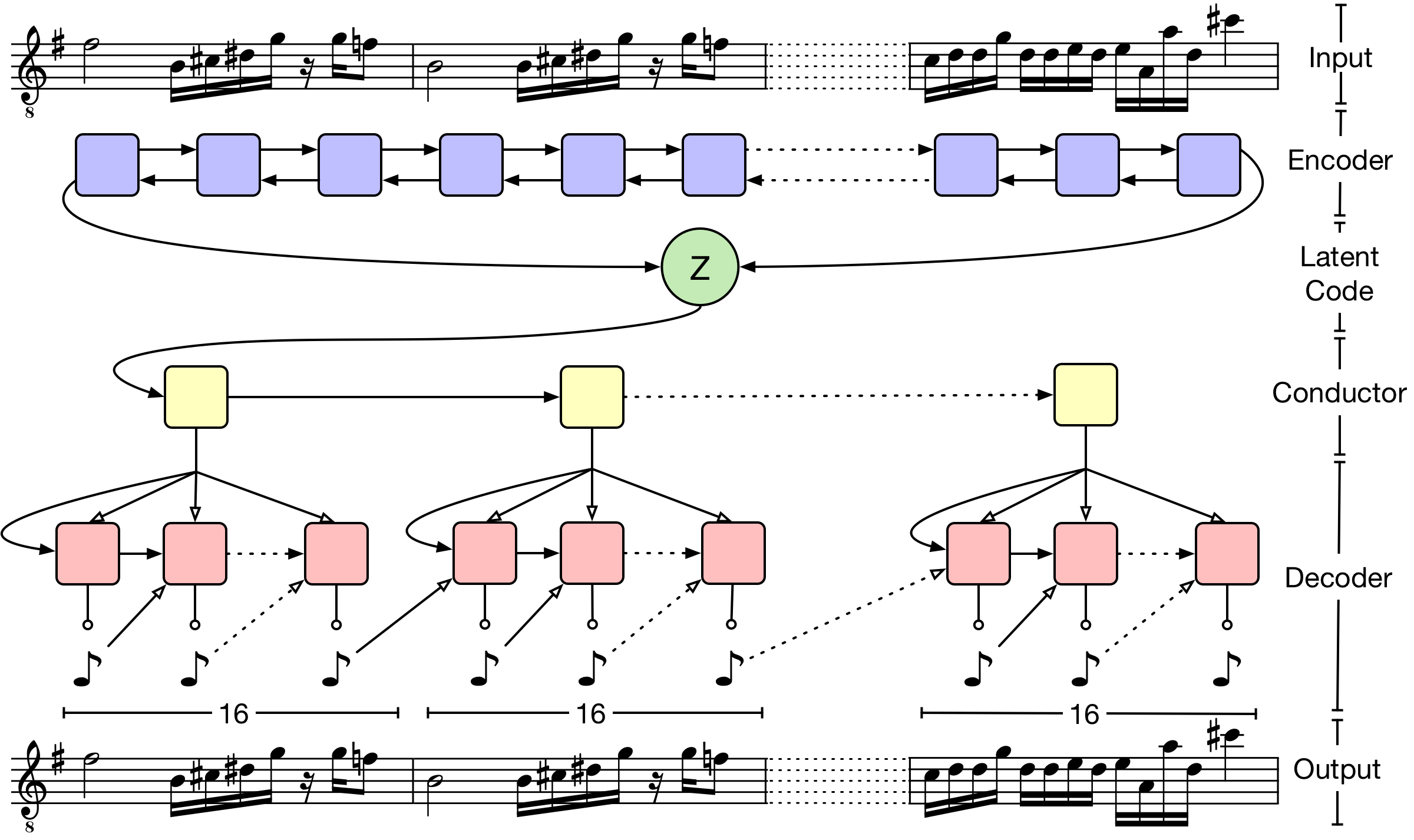
Human Activity Recognition from a sequence of poses, which can classify JUMPING, JUMPING_JACKS, BOXING, WAVING_2HANDS, WAVING_1HAND, CLAPPING_HANDS.

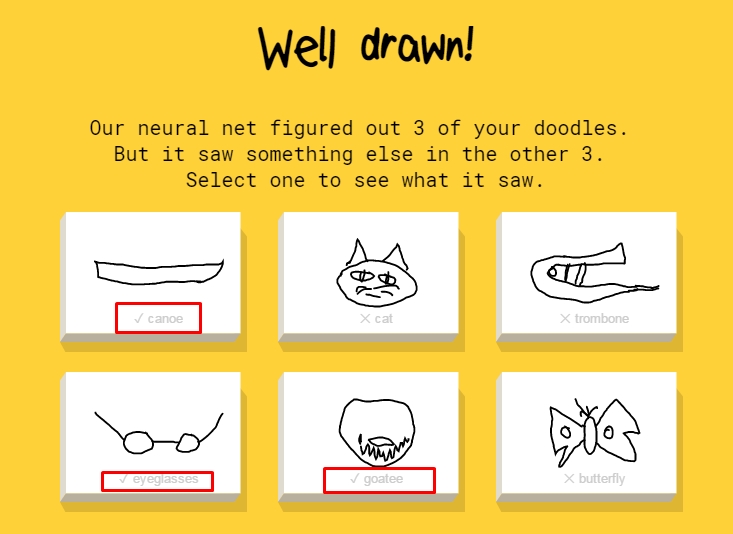
Sketch classification, where a sequence of stroked are classified:
Behavior Prediction, where a sequence of behaviors can be used to predict the next behavior:

Some nice things about Recurrent Neural Networks:
- They can be trained with a lot less resources than traditional convolutional neural networks, allowing for them to be trained on our own computers.
- When training, it is easy to see the progress.
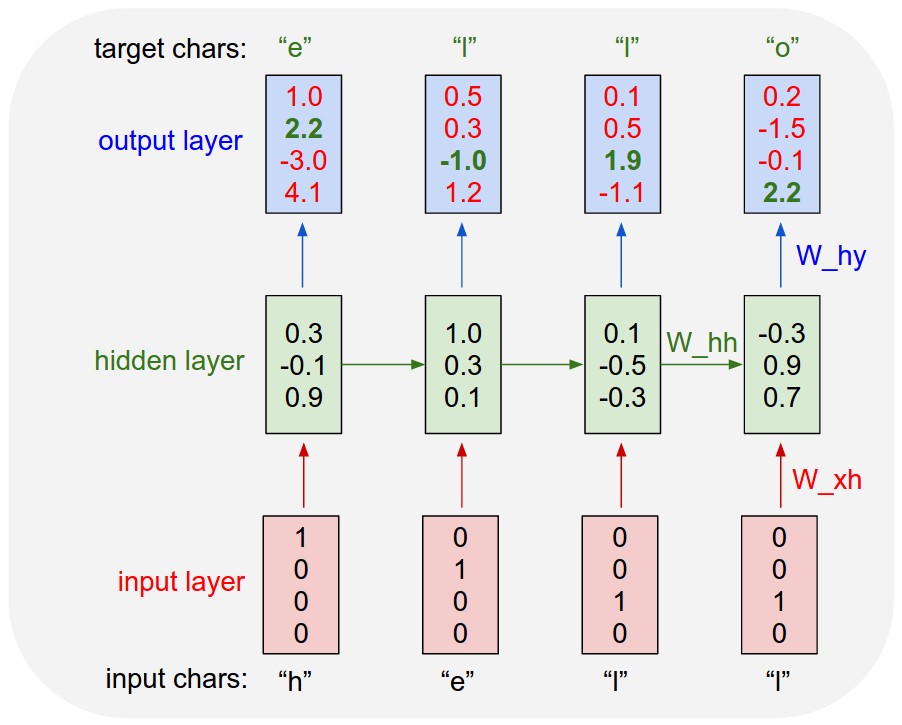
The model we just ran is an LSTM model which operates at the character level. It takes an input of a character of strings, each character encoded as a one-hot value. With the input, the model outputs a list of values, which represents the model's predicted probabilites of a character that follows the input sequence. The application then draws a random sample based on the predicted probabilities to get the next character. Once the next character is obtained, it is concatenated with the previous input sequence to form the input for the next time step. This process is repeated in order to generate a character sequence of a given length. The randomness (diversity) is controlled by a temperature parameter.
The UI allows creation of models consisting of a single LSTM layer or multiple, stacked LSTM layers.
First, let's walk through a browser version of this example.
The main parameters when training are:
- Text corpus what text corpus the model is trained on.
- lstmLayeSize the architecture of the model. Specifies how many LSTM nodes there should be in each layer. 128,128 specifies that the next-character prediction model should contain two LSTM layers stacked on top of each other, each with 128 units.
- epochs The number of training epochs. This is how many rounds of training to do.
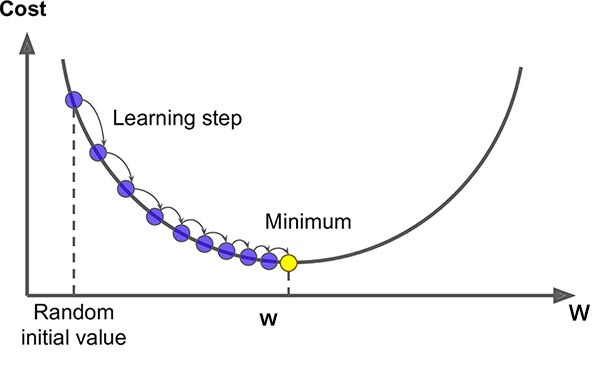
We'll briefly discuss the rest of the parameters in class, while referring to the diagram below:
Training a model in Node.js should give you a faster performance than the browser environment. It also allows you to use the model in Node.js, which means it can be used in something like Puppeteer.
To start a training job, enter command lines such as:
yarn train shakespeare.txt \
--lstmLayerSize 100 \
--epochs 10 \
--save my-shakespear-model- The first argument to
yarn train(shakespeare.txt) specifies what text corpus to train the model on. See the console output ofyarn train --helpfor a set of supported text data. It grabs the file from the folder./data. So if the argumentshakespeare.txtis used, the file should be located at./data/shakespeare.txt - The argument
--lstmLayerSize 100specifies that the next-character prediction model should one LSTM layer with 100 units. This can be can be a single number or an array of numbers separated by commas (E.g., "256", "256,128"). If this is a value with commas and multiple numbers, it will have a layer for each of those numbers stacked on top of each other. - The flag
--epochsis used to specify the number of training epochs. - The argument
--save ...lets the training script save the model at the specified path within the folder./models. For example--save my-facebook-postswould save a model at./models/my-facebook-posts - The argument
--sampleLenis the length of each input sequence to the model in number of characters. It defaults to 60 - The argument
--debugAtEpochdetermines after how many epochs to debug inference on. Defaults to 5. For example, if this is set to 10, then every 10 epochs, the model will be run on a random piece of text and the results shown. This slows down the training process, so set it to a higher value to perform less often and see the results less often, and visa versa.
This repository modifies the original example in that it enables you to use your GPU for training without needing an NVidia graphics card or CUDA installed, by tapping into the tensorflow.js node-gl backend. To enable this, you can add the --gpu flag to the command line to train the model on the GPU, which
should give you a further performance boost. Note that this is an experimental feature and can often break.
The example command line above generates a set of model files in the
./models/my-shakespeare-model folder after the completion of the training. You can
load the model and use it to generate text. For example:
yarn gen shakespeare.txt my-shakespeare-model \
--genLength 250 \
--temperature 0.6See the console output of yarn gen --help for a set of instructions on how to use this command.
Now we will go through some basic examples of how to create a text corpus which can be trained on.
The first step of building a text corpus of course involves gathering some text, and saving it to the folder ./data/
One way this can be done is to scrape some webpages. Let's try this with a sample script, scrape_wiki_how.js, which visits wikihow.com, enters a search term, opens the first 10 results, then saves the contents of each result into a text file within the folder './data/wikihow_results'
Run the command:
node scrape_wiki_how.js cats
Take a look at the files within the folder './data/wikihow_results'
To combine these individual files into a single corpus:
node combine_files_into_corpus.js data/wikihow_results 'wikihow.txt' "|"
A tool that you will likefly find useful is the command:
node combine_files_into_corpus.js {{source_folder}} {{destination_file.txt}} {{delimiter}}
This takes all of the contents from text files in the source_folder, concatenates them using the delimiter, and writes the concattenated files to text in destination_file.txt within the folder /corpus
So, for example:
yarn combine_file_into_corpus ./data/extracted_facebook_posts_text facebook_posts.txt "|"
Will grab all text from files in the folder ./data/extracted_facebook_posts_text concatenate them with the symbol | and write the concatenated text to the file ./corpus/facebook_posts.txt
This text can then be used train an LSTM using the training script above.
After you download your facebook posts, you can convert them into text files for a corpus by running:
node convert_facebook_posts.js ./data/your_posts_1.json facebook_posts
Where the ./data/your_posts_1.json is the path to the posts json file, and facebook_posts is the folder within the data directory to save the contents of each post to.
These can then be combined into a corpus with:
node combine_files_into_corpus.js ./data/facebook_posts/ facebook_posts.txt "|"
This can then be trained with:
yarn train facebook_posts.txt \
--lstmLayerSize 100 \
--epochs 10 \
--save facebook_posts
And have then generate text with:
yarn gen facebook_posts.txt facebook_posts
After you have trained a model, you can run a sample script to post to facebook with text generated by it.
yarn post_to_facebook_lstm shakespeare.txt shakespeare \
--temperature 0.7
These tips are pulled from Andrej Karpathy's char-rnn Readme, with some slight modifications:
Dataset sizes: Note that if your data is too small (1MB is already considered very small) the RNN won't learn very effectively. Remember that it has to learn everything completely from scratch. Conversely if your data is large (more than about 2MB), feel confident to increase lstmLayerSize and train a bigger model. It will work significantly better. For example with 6MB you can easily go up to lstmLayerSize 300 or even more.
Temperature: An important parameter you may want to play with is temperature which takes a number in range (0, 1] (0 not included), default = 1. Lower temperature will cause the model to make more likely, but also more boring and conservative predictions. Higher temperatures cause the model to take more chances and increase diversity of results, but at a cost of more mistakes.
If you're somewhat new to Machine Learning or Neural Networks it can take a bit of expertise to get good models. The most important quantity to keep track of is the difference between your training loss and the validation loss. In particular:
- If your training loss is much lower than validation loss then this means the network might be overfitting. Solutions to this are to decrease your network size, or to increase dropout. For example you could try dropout of 0.5 and so on.
- If your training/validation loss are about equal then your model is underfitting. Increase the size of your model (either number of layers or the raw number of neurons per layer)
The most parameters that control the model is the lstmLayerSize. I would advise that you always use 2/3 layers, by specifying 2/3 values with comma separating them. The size of each layer can be adjusted based on how much data you have. The two important quantities to keep track of here are:
- The number of parameters in your model. This is printed when you start training.
- The size of your dataset. 1MB file is approximately 1 million characters.
These two should be about the same order of magnitude. It's a little tricky to tell. Here is an example:
- I have a 100MB dataset and I'm using the default parameter settings (which currently prints 100K parameters). My data size is significantly larger (100 mil >> 0.1 mil), so I expect to heavily underfit. I am thinking I can comfortably afford to make
lstmLayerSizelarger.