Siamese networks and Friends

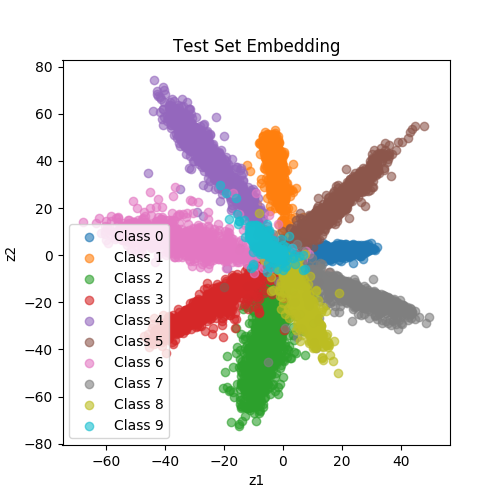
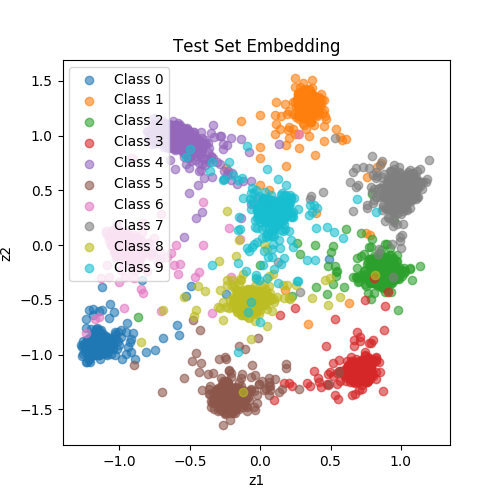
Fig. 1: Latent space learned from a Siamese network. These dots are MNIST test samples.
They are highlighted with the same color if they come from the same class.
Introduction
Given a set of data, such as images, we can find a latent space that these samples lay on. Although this latent space typically much lower dimensions than the original space, it preserves semantic information between neighbours. Mapping data from the original space to the latent space allows us to reduce the dimensions we need to represent data significantly; hence reduce computation resources.
In this project, we aim to use several neural networks to learn such latent spaces. Using different architectures and loss functions, we can see how data is represented in those latent spaces Some of these spaces map similar data together, i.e. samples in the same class. With appropriated learned latent space, one can use these latent features for other downstream tasks, such as classification or reverse image search.
Architectures
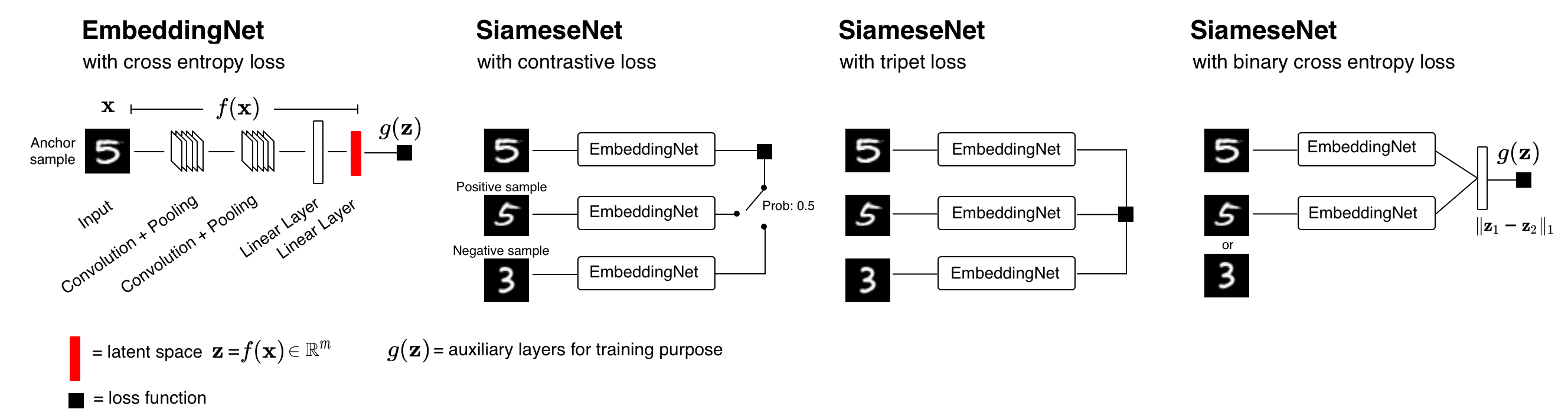
Fig. 2: Architectures experimented in this project.
EmbeddingNet is based on @adambielski's siamese-tripet, while SiameseNet is from Koch (2015).
Loss Functions
-
Cross Entropy Loss (CE)
CE is used to train EmbeddingNet. It learns a latent space that provides good information for classifying samples.
-
Binary Cross Entropy Loss (BCE)
Using BCE, the latent representation is learned in such as a way that enables the Siamese network to classify whether two given samples are similar.
-
CL allows us to learn representation that bring similar samples together in a latent space.
-
TL is similar to CL but it also has a constraint that the distance between a sample and its positive pair should be smaller than the distance between the sample and its negative pair.




Command
Usage: train.py [-h] [--lr 0.0001] [--epochs 10] [--batch-size 32]
[--output ./tmp] [--log-interval 50] [--animation 50]
network dataset
Positional arguments:
network [embedding-classification|siamese-constrastive|siamese-binary-cross-entropy|tripet-loss-net]
dataset [MNIST|FashionMNIST]
Optional arguments:
-h, --help show this help message and exit
--lr 0.0001 learning rate
--epochs 10 no. epochs
--batch-size 32 batch size
--output ./tmp output directory
--log-interval 50 logging interval
--animation False produce latent space every epoch for animation
Results
| Network | MNIST | FashionMNIST |
|---|---|---|
| EmbeddingNet (CrossEntropyLoss) |
 |
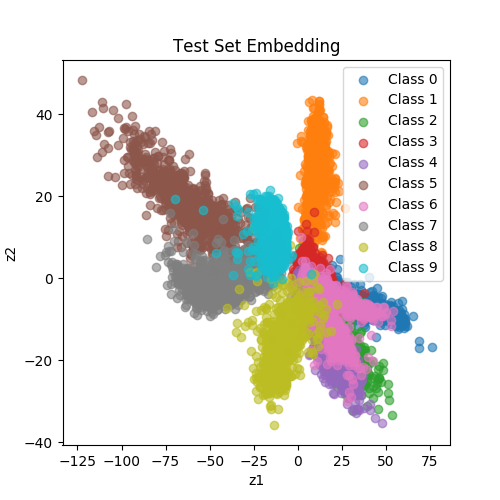 |
| SiameseNet (ContrastiveLoss) |
 |
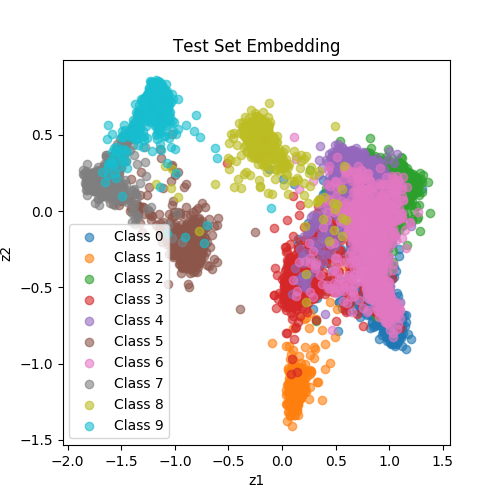 |
| SiameseNet (BinaryCrossEntropyLoss) |
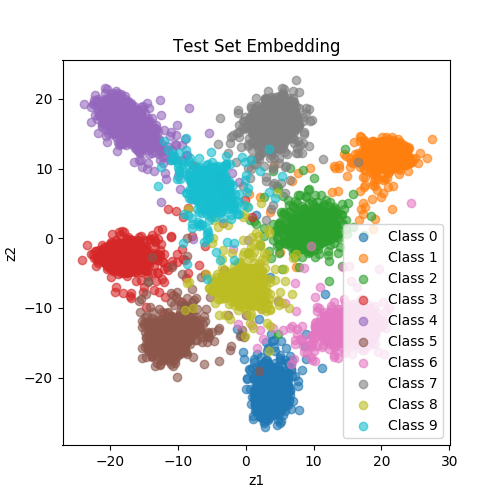 |
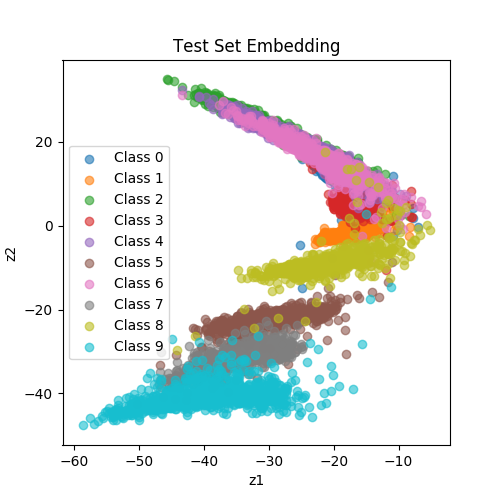 |
| SiameseNet (TripetLoss) |
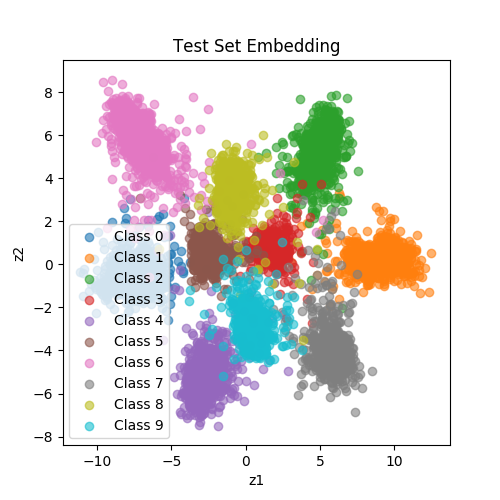 |
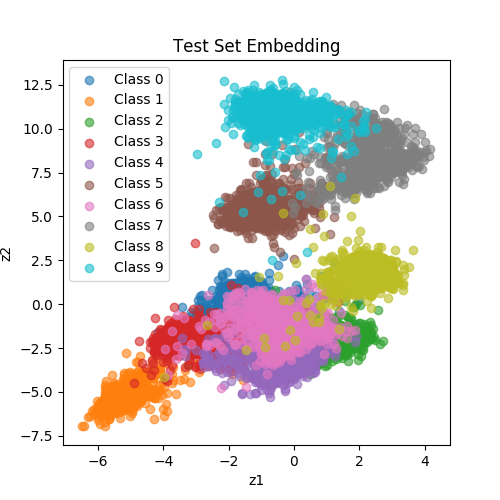 |
| VAE (TBD) |
Acknowledgements
- @adambielski's siamese-tripet: experiments here are mainly based on his experiments.
References
- Koch, G.R. (2015). Siamese Neural Networks for One-Shot Image Recognition.
- Hadsell, R., Chopra, S., & LeCun, Y. (2006). Dimensionality reduction by learning an invariant mapping. In Proceedings of the IEEE conference on CVPR (pp. 1735-1742).
- Schroff, F., Kalenichenko, D., & Philbin, J. (2015). Facenet: A unified embedding for face recognition and clustering. In Proceedings of the IEEE conference on CVPR (pp. 815-823).