AirlineDataHub is a comprehensive data engineering solution designed to simplify the analysis and warehousing of aviation data. By leveraging the power of Python for data extraction and cleaning, SQL for data storage and manipulation, and AWS services for scalable data storage and analytics, this repository provides a robust foundation for data handling in the aviation sector.
Starting with the ingestion of CSV files from AWS S3 buckets, the project employs ETL pipelines that facilitate exploratory data analysis (EDA) to uncover initial insights but also engage in comprehensive data modeling to structure data effectively for analysis. Once processed, this data is loaded into AWS Redshift, leveraging its powerful analytics capabilities.
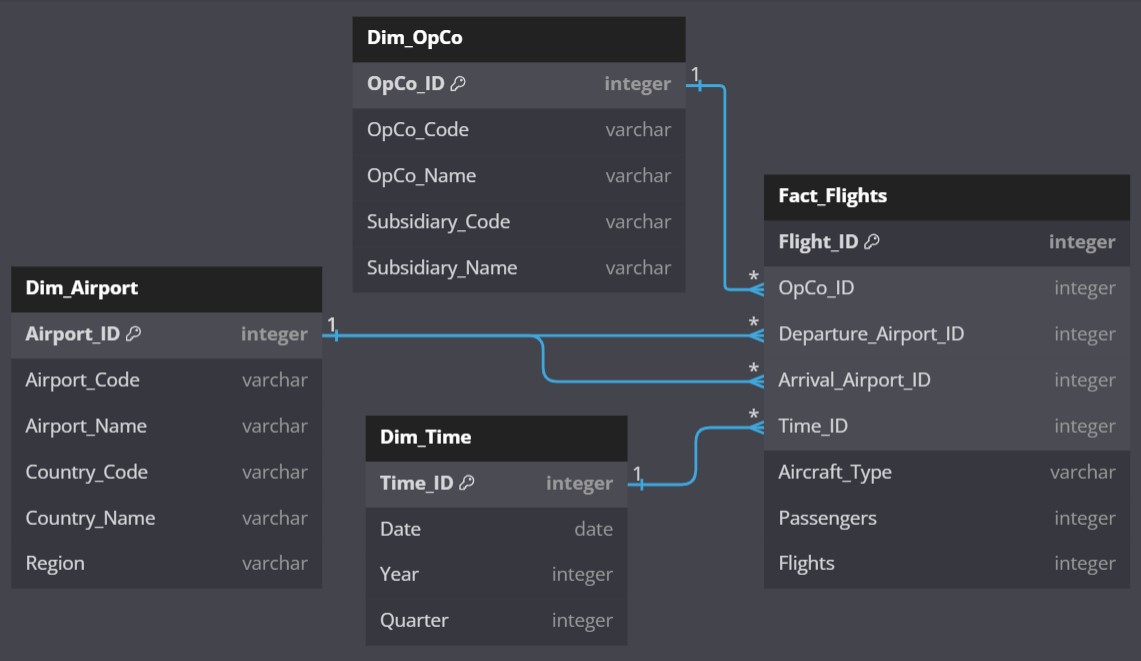
Good practices in data engineering were followed, with a particular focus on the development of a data model that is inherently optimized for analysis:
For a detailed explanation of the repository structure, please refer to the Repository Structure Documentation.
-
Clone the Repository:
git clone https://github.com/pablo-git8/AirlineDataHub.git cd AirlineDataHub -
Environment Setup:
-
AWS S3 and Redshift Configuration:
- Configure your AWS CLI with the necessary access credentials.
- Ensure there is an existent S3 bucket with the data
- Ensure your AWS Redshift cluster is set up and accessible.
-
Environment Variables:
- Copy the
.env.examplefile to.envand update it with your actual configuration details.
- Copy the
-
Running the Pipeline: To execute the full data pipeline, navigate to the
pipelinedirectory and run:./run-pipeline.sh -
Exploratory Data Analysis (EDA): Launch Jupyter Notebooks for checking the development processes, data exploration and prototyping:
jupyter notebook notebooks/data_exploration.ipynb jupyter notebook notebooks/data_transformation.ipynb jupyter notebook notebooks/data_modeling.ipynbThese files provide the ground basis for script development for the pipeline. Have a look at the scripts here:
../src/ingestion.py # Loads raw data from S3 and saves a raw copy ../src/transforms.py # Perform all necessary transformation and saves a cleaned copy ../src/loading-sqlite.py # Data modeling. Creates transitory DDBB for later copy to a Data Warehouse ../src/loading-redshift.py # Loads the data to AWS RedshiftAdditionally the following script creates an aggregated table optimized for showing the number of passengers by
OpCo,Country,Region,Year,Quarter of the year (Q1, Q2, Q3 or Q4):../src/create_agg_table.py # Creates aggregated table into SQL DDBB -
Testing: Run unit tests to ensure reliability:
poetry run pytest tests/
For more detailed information about the project overview, data model, and specific components, refer to the docs directory.
-
ER Diagram and Database Schema: Visual representations of the data model and database schema are available in
ER_diagram.jpganddb_schema.pdf, respectively. -
Project Overview: For a comprehensive overview of the project, including its goals, methodologies, and technologies used, check out
project_overview.md.
If you prefer to use Docker, ensure Docker and Docker Compose are installed.
To build the Docker image for running the pipeline, follow these steps:
- Navigate to the root of the repository where the docker/ directory is located:
cd path/to/AirlineDataHub
-
Create a .env file that contains all the necessary environment variables (check
.env.examplefile for guidance) -
Build the Docker image using the Dockerfile in the
dockerdirectory. Replaceairlinedatahub-imagewith a name of your choice for the Docker image:
docker build -f docker/Dockerfile -t airlinedatahub-image .
- Once the Docker image is built, you can run the container using the following command. This will execute the pipeline script within the container as specified in the Dockerfile's
CMDinstruction.
docker run --env-file /path/to/your/.env airlinedatahub-image
- For running it with Docker Compose, simply run:
docker-compose up --build
AirlineDataHub is released under the MIT License.
For any queries or further assistance, please contact Pablo Ruiz Lopez.