A Reproducible Dataset to Study Transportation, Residential Context, and Well-being in Santiago, Chile in R
In this notebook we read and preprocess the raw data collected as a paper-based survey conducted face-to-face in Santiago in 2016 by Dr. Beatriz Mella-Lira. The survey collected information on a wide range of travel-related issues (socio-demographics, health-related, perceptions and travel behaviour, travel choices and planning, social interaction factors, built environment, and so on).
The data collection considered a quota-sampling method based on the information from the Pre-census of 2012, and with a total of 451 persons.
To access the raw material used for generating this dataset, we first
need to learn how to use this repository in RStudio.
This project repository utilizes the {renv} package to establish a reproducible environment. It is designed to facilitate work with the bSantiago dataset, titled A Reproducible Dataset to Study Transportation, Residential Context, and Well-being in Santiago, Chile in R.
The repository offers the necessary setup to recreate the environment used for generating the dataset. This encompasses the specific version of R and all the packages utilized in the dataset.
Begin by installing R as a programming language, ensuring that you select the appropriate version for your operating system. You can find R as a core package here: https://cran.rstudio.com/.
Install RStudio, again ensuring that you choose the correct version for your operating system. RStudio serves as an Integrated Development Environment (IDE) and can be downloaded from: https://www.rstudio.com/products/rstudio/download/.
If you’re using Windows, download and run the Rtools43 installer from this link: https://cran.r-project.org/bin/windows/Rtools/rtools43/rtools.html. For Mac users, you may need to install Xcode, though we can’t verify this since we don’t have access to Macs. You can find more information here: https://mac.r-project.org/tools/.
Download the code from the repository available at:
https://github.com/paezha/bSantiago. The repository contains a
renv.lock file specifying all package versions used in the data-set.
Open the file and store it in a suitable directory. Save it to a
location on your computer where you can easily access it. You can use
the code below as well:
install.packages("remotes")
remotes::install_github("paezha/bSantiago")
Locate the downloaded repository folder and open the .Rproj file named
“bSantiago” to launch the R project in RStudio. This ensures that you
are working within the project’s environment.
Install the renv package by running the command
install.packages(“renv”) in the RStudio console. This package helps
manage the project’s dependencies and ensures a consistent environment
for reproducibility. The following code is the same:
install.packages("Renv")
After installing renv, close and reopen RStudio. You may receive a
message indicating that your library is out of sync with the lock file.
To synchronize them, run the command renv::restore() in the RStudio
console.
renv::restore()
As a general tip if any individual library fails to install, run:
install.packages("name of the library")
replacing “name of the library” with the package name. Then run
renv::restore() again. Repeat this process if needed.
Check the status of the renv environment by running renv::status()
in the R Console. Ensure that the versions of packages on your system
match those specified in the renv.lock file.
renv::status()
Now here is the instructions on how to use raw material to generate all the necessary information based on the research objectives. After opening a new R Markdown file you can go through the following steps:
- Open a New R Markdown File:
In RStudio, go to the “File” menu and select “New File,” then choose “R
Markdown” from the dropdown menu. Alternatively, you can use the
keyboard shortcut Ctrl + Shift + N (Windows) or Cmd + Shift + N (Mac).
Select the appropriate template from the list of options. Since you’re
working with the bSantiago dataset, choose a template relevant to your
analysis or reporting needs. For example, you might select a template
for data exploration, analysis, or report generation.
Provide a name for your R Markdown file and choose a location to save it.
- Accessing the Dataset:
Once your R Markdown file is open, you can start accessing the
bSantiago dataset. This may involve loading the dataset into your R
environment using appropriate functions such as read.csv() or readxlsx()
depending on the format of the dataset including both CSV and Excel.
Ensure that the dataset file is located in a directory accessible to
your R session. You may need to set the working directory using
setwd() or use relative file paths to access the dataset file. Here
are the code for loading dataset (Answers), survey (questions and
dictionary) and communa file which is a data frame including geographic
information of respondents to the survey.
SantiagoSurvey <- readxl::read_xlsx(paste0(here(), "/data-raw/SantiagoSurvey2016.xlsx"))
SantiagoSurvey_csv <- readr::read_csv(paste0(here(), "/data-raw/SantiagoSurvey2016.csv"))
SantiagoSurvey_dicxl <- readxl::read_xlsx(paste0(here(), "/data-raw/SantiagoSurvey2016-Survey-Questions-and-Dictionary.xlsx"))
SantiagoSurvey_diccsv <- readr::read_csv(paste0(here(), "/data-raw/SantiagoSurvey2016-Survey-Questions-and-Dictionary.csv"))
comunas_1 <- st_read(paste0(here(), "/data-raw/comunas_1/comunas_1Polygon.shp"))
- Preprocessing the Dataset:
Once the dataset is loaded depending on the nature of your analysis and research objectives, you may need to preprocess the dataset before conducting any analysis. This may include tasks such as data cleaning, data transformation, data merging, and data aggregation.
- Exploratory Data Analysis (EDA):
Once the dataset is preprocessed, you can perform exploratory data analysis to gain insights into the data distribution, relationships between variables, and potential patterns or trends.
After completing the data preprocessing steps in your R Markdown document, you might want to knit the document to produce a final report or output. Here’s how you can knit your R Markdown document and handle some common scenarios:
- Knitting to HTML, PDF, or Other Formats:
To knit your R Markdown document, click the “Knit” button in the RStudio toolbar.
Choose the output format you want (HTML, PDF, Word, etc.) from the dropdown menu.
RStudio will then execute the R code chunks in your document and render the output in the specified format.
- Handling Errors:
If there are any errors during the knitting process, RStudio will display error messages in the console. Review the error messages to identify and fix any issues in your R Markdown document or R code.
- Viewing the Output:
Once the knitting process is complete, RStudio will open the output file in a new tab or window.
You can view the output file directly in RStudio or open it in your default web browser or PDF viewer.
By following these steps and considerations, you can successfully knit your R Markdown document and generate a final report or output based on your data preprocessing and analysis.
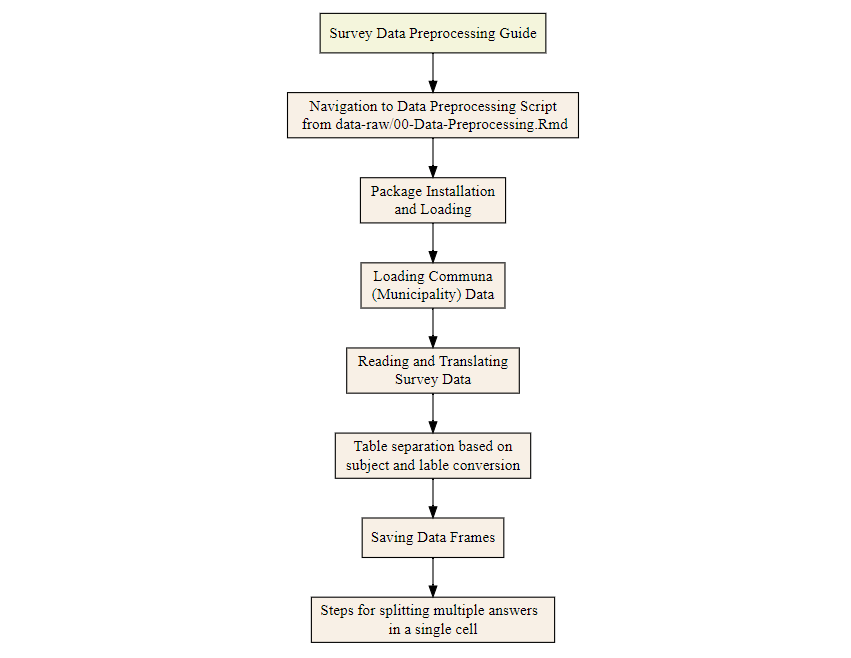
Here is a brief flowchart starting from raw data to ready for analysis dataset: