




Hotshot-XL is an AI text-to-GIF model trained to work alongside Stable Diffusion XL.
Hotshot-XL can generate GIFs with any fine-tuned SDXL model. This means two things:
- You’ll be able to make GIFs with any existing or newly fine-tuned SDXL model you may want to use.
- If you'd like to make GIFs of personalized subjects, you can load your own SDXL based LORAs, and not have to worry about fine-tuning Hotshot-XL. This is awesome because it’s usually much easier to find suitable images for training data than it is to find videos. It also hopefully fits into everyone's existing LORA usage/workflows :) See more here.
Hotshot-XL is compatible with SDXL ControlNet to make GIFs in the composition/layout you’d like. See the ControlNet section below.
Hotshot-XL was trained to generate 1 second GIFs at 8 FPS.
Hotshot-XL was trained on various aspect ratios. For best results with the base Hotshot-XL model, we recommend using it with an SDXL model that has been fine-tuned with 512x512 images. You can find an SDXL model we fine-tuned for 512x512 resolutions here.
Try Hotshot-XL yourself here: https://www.hotshot.co
Or, if you'd like to run Hotshot-XL yourself locally, continue on to the sections below.
If you’re running Hotshot-XL yourself, you are going to be able to have a lot more flexibility/control with the model. As a very simple example, you’ll be able to change the sampler. We’ve seen best results with Euler-A so far, but you may find interesting results with some other ones.
pip install virtualenv --upgrade
virtualenv -p $(which python3) venv
source venv/bin/activate
pip install -r requirements.txt
# Make sure you have git-lfs installed (https://git-lfs.com)
git lfs install
git clone https://huggingface.co/hotshotco/Hotshot-XL
or visit https://huggingface.co/hotshotco/Hotshot-XL
- Note: To maximize data and training efficiency, Hotshot-XL was trained at various aspect ratios around 512x512 resolution. For best results with the base Hotshot-XL model, we recommend using it with an SDXL model that has been fine-tuned with images around the 512x512 resolution. You can download an SDXL model we trained with images at 512x512 resolution below, or bring your own SDXL base model.
# Make sure you have git-lfs installed (https://git-lfs.com)
git lfs install
git clone https://huggingface.co/hotshotco/SDXL-512
or visit https://huggingface.co/hotshotco/SDXL-512
python inference.py \
--prompt="a bulldog in the captains chair of a spaceship, hd, high quality" \
--output="output.gif"
What to Expect:
| Prompt | Sasquatch scuba diving | a camel smoking a cigarette | Ronald McDonald sitting at a vanity mirror putting on lipstick | drake licking his lips and staring through a window at a cupcake |
|---|---|---|---|---|
| Output |  |
 |
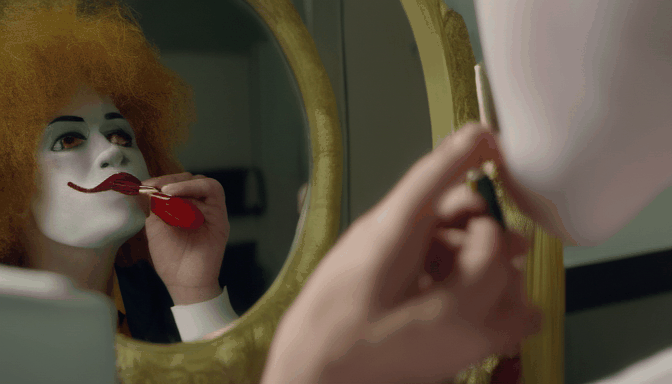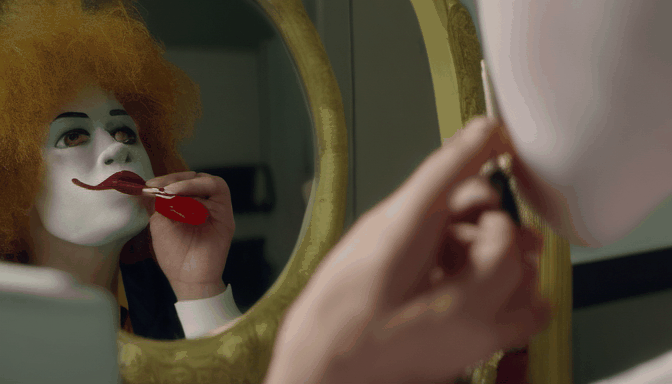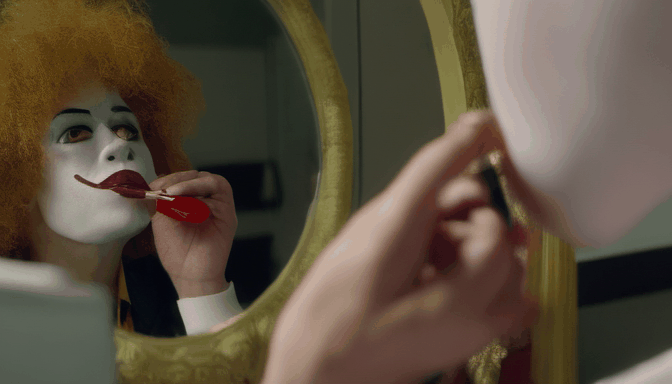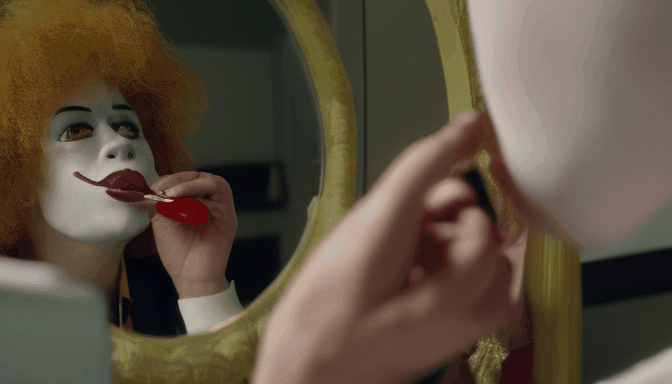 |
 |
python inference.py \
--prompt="a bulldog in the captains chair of a spaceship, hd, high quality" \
--output="output.gif" \
--spatial_unet_base="path/to/stabilityai/stable-diffusion-xl-base-1.0/unet" \
--lora="path/to/lora"
What to Expect:
Note: The outputs below use the DDIMScheduler.
| Prompt | sks person screaming at a capri sun | sks person kissing kermit the frog | sks person wearing a tuxedo holding up a glass of champagne, fireworks in background, hd, high quality, 4K |
|---|---|---|---|
| Output |  |
 |
 |
python inference.py \
--prompt="a girl jumping up and down and pumping her fist, hd, high quality" \
--output="output.gif" \
--control_type="depth" \
--gif="https://media1.giphy.com/media/v1.Y2lkPTc5MGI3NjExbXNneXJicG1mOHJ2dzQ2Y2JteDY1ZWlrdjNjMjl3ZWxyeWFxY2EzdyZlcD12MV9pbnRlcm5hbF9naWZfYnlfaWQmY3Q9Zw/YOTAoXBgMCmFeQQzuZ/giphy.gif"
By default, Hotshot-XL will create key frames from your source gif using 8 equally spaced frames and crop the keyframes to the default aspect ratio. For finer grained control, learn how to vary aspect ratios and vary frame rates/lengths.
Hotshot-XL currently supports the use of one ControlNet model at a time; supporting Multi-ControlNet would be exciting.
What to Expect:
| Prompt | pixar style girl putting two thumbs up, happy, high quality, 8k, 3d, animated disney render | keanu reaves holding a sign that says "HELP", hd, high quality | a woman laughing, hd, high quality | barack obama making a rainbow with their hands, the word "MAGIC" in front of them, wearing a blue and white striped hoodie, hd, high quality |
|---|---|---|---|---|
| Output |  |
 |
 |
 |
| Control |  |
 |
 |
 |
- Note: The base SDXL model is trained to best create images around 1024x1024 resolution. To maximize data and training efficiency, Hotshot-XL was trained at aspect ratios around 512x512 resolution. Please see Additional Notes for a list of aspect ratios the base Hotshot-XL model was trained with.
Like SDXL, Hotshot-XL was trained at various aspect ratios with aspect ratio bucketing, and includes support for SDXL parameters like target-size and original-size. This means you can create GIFs at several different aspect ratios and resolutions, just with the base Hotshot-XL model.
python inference.py \
--prompt="a bulldog in the captains chair of a spaceship, hd, high quality" \
--output="output.gif" \
--width=<WIDTH> \
--height=<HEIGHT>
What to Expect:
| 512x512 | 672x384 | 384x672 | |
|---|---|---|---|
| a monkey playing guitar, nature footage, hd, high quality |  |
 |
 |
By default, Hotshot-XL is trained to generate GIFs that are 1 second long with 8FPS. If you'd like to play with generating GIFs with varying frame rates and time lengths, you can try out the parameters video_length and video_duration.
video_length sets the number of frames. The default value is 8.
video_duration sets the runtime of the output gif in milliseconds. The default value is 1000.
Please note that you should expect unstable/"jittery" results when modifying these parameters as the model was only trained with 1s videos @ 8fps. You'll be able to improve the stability of results for different time lengths and frame rates by fine-tuning Hotshot-XL. Please let us know if you do!
python inference.py \
--prompt="a bulldog in the captains chair of a spaceship, hd, high quality" \
--output="output.gif" \
--video_length=16 \
--video_duration=2000
Hotshot-XL is trained to generate GIFs alongside SDXL. If you'd like to generate just an image, you can simply set video_length=1 in your inference call and the Hotshot-XL temporal layers will be ignored, as you'd expect.
python inference.py \
--prompt="a bulldog in the captains chair of a spaceship, hd, high quality" \
--output="output.jpg" \
--video_length=1
Hotshot-XL was trained at the following aspect ratios; to reliably generate GIFs outside the range of these aspect ratios, you will want to fine-tune Hotshot-XL with videos at the resolution of your desired aspect ratio.
| Aspect Ratio | Size |
|---|---|
| 0.42 | 320 x 768 |
| 0.57 | 384 x 672 |
| 0.68 | 416 x 608 |
| 1.00 | 512 x 512 |
| 1.46 | 608 x 416 |
| 1.75 | 672 x 384 |
| 2.40 | 768 x 320 |
The following section relates to fine-tuning the Hotshot-XL temporal model with additional text/video pairs. If you're trying to generate GIFs of personalized concepts/subjects, we'd recommend not fine-tuning Hotshot-XL, but instead training your own SDXL based LORAs and just loading those.
The fine_tune.py script expects your samples to be structured like this:
fine_tune_dataset
├── sample_001
│ ├── 0.jpg
│ ├── 1.jpg
│ ├── 2.jpg
...
...
│ ├── n.jpg
│ └── prompt.txt
Each sample directory should contain your n key frames and a prompt.txt file which contains the prompt.
The final checkpoint will be saved to output_dir.
We've found it useful to send validation GIFs to Weights & Biases every so often. If you choose to use validation with Weights & Biases, you can set how often this runs with the validate_every_steps parameter.
accelerate launch fine_tune.py \
--output_dir="<OUTPUT_DIR>" \
--data_dir="fine_tune_dataset" \
--report_to="wandb" \
--run_validation_at_start \
--resolution=512 \
--mixed_precision=fp16 \
--train_batch_size=4 \
--learning_rate=1.25e-05 \
--lr_scheduler="constant" \
--lr_warmup_steps=0 \
--max_train_steps=1000 \
--save_n_steps=20 \
--validate_every_steps=50 \
--vae_b16 \
--gradient_checkpointing \
--noise_offset=0.05 \
--snr_gamma \
--test_prompts="man sits at a table in a cafe, he greets another man with a smile and a handshakes"
There are lots of ways we are excited about improving Hotshot-XL. For example:
- Fine-Tuning Hotshot-XL at larger frame rates to create longer/higher frame-rate GIFs
- Fine-Tuning Hotshot-XL at larger resolutions to create higher resolution GIFs
- Training temporal layers for a latent upscaler to produce higher resolution GIFs
- Training an image conditioned "frame prediction" model for more coherent, longer GIFs
- Training temporal layers for a VAE to mitigate flickering/dithering in outputs
- Supporting Multi-ControlNet for greater control over GIF generation
- Training & integrating different ControlNet models for further control over GIF generation (finer facial expression control would be very cool)
- Moving Hotshot-XL into AITemplate for faster inference times
We 💗 contributions from the open-source community! Please let us know in the issues or PRs if you're interested in working on these improvements or anything else!
Text-to-Video models are improving quickly and the development of Hotshot-XL has been greatly inspired by the following amazing works and teams:
We hope that releasing this model/codebase helps the community to continue pushing these creative tools forward in an open and responsible way.