
MemGPT allows you to build LLM agents with self-editing memory
Try out our MemGPT chatbot on Discord!
You can now run MemGPT with open/local LLMs and AutoGen!




Join Discord and message the MemGPT bot (in the #memgpt channel). Then run the following commands (messaged to "MemGPT Bot"):
/profile(to create your profile)/key(to enter your OpenAI key)/create(to create a MemGPT chatbot)
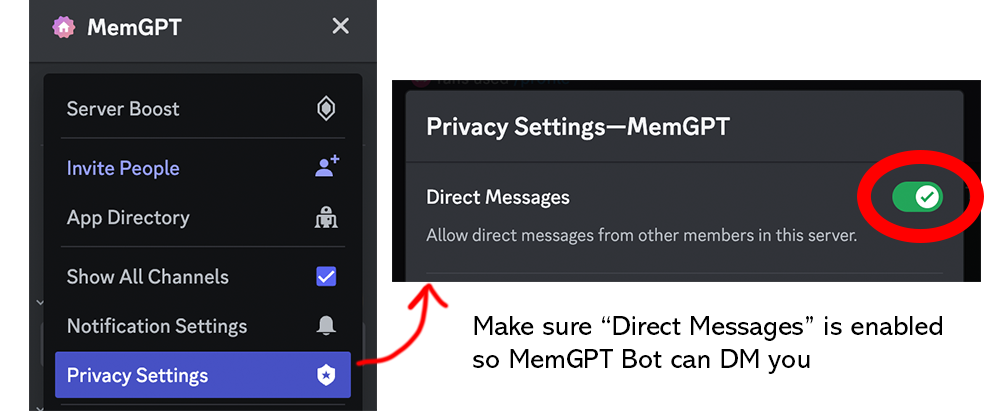
Make sure your privacy settings on this server are open so that MemGPT Bot can DM you:
MemGPT → Privacy Settings → Direct Messages set to ON
You can see the full list of available commands when you enter / into the message box.
Memory-GPT (or MemGPT in short) is a system that intelligently manages different memory tiers in LLMs in order to effectively provide extended context within the LLM's limited context window. For example, MemGPT knows when to push critical information to a vector database and when to retrieve it later in the chat, enabling perpetual conversations. Learn more about MemGPT in our paper.
Install MemGPT:
pip install -U pymemgptNow, you can run MemGPT and start chatting with a MemGPT agent with:
memgpt runIf you're running MemGPT for the first time, you'll see two quickstart options:
- OpenAI: select this if you'd like to run MemGPT with OpenAI models like GPT-4 (requires an OpenAI API key)
- MemGPT Free Endpoint: select this if you'd like to try MemGPT on a top open LLM for free (currently variants of Mixtral 8x7b!)
Neither of these options require you to have an LLM running on your own machine. If you'd like to run MemGPT with your custom LLM setup (or on OpenAI Azure), select Other to proceed to the advanced setup.
You can reconfigure MemGPT's default settings by running:
memgpt configureYou can run the following commands in the MemGPT CLI prompt while chatting with an agent:
/exit: Exit the CLI/attach: Attach a loaded data source to the agent/save: Save a checkpoint of the current agent/conversation state/dump: View the current message log (see the contents of main context)/dump <count>: View the last messages (all if is omitted)/memory: Print the current contents of agent memory/pop: Undo the last message in the conversation/pop <count>: Undo the last messages in the conversation. It defaults to 3, which usually is one turn around in the conversation/retry: Pops the last answer and tries to get another one/rethink <text>: Will replace the inner dialog of the last assistant message with the<text>to help shaping the conversation/rewrite: Will replace the last assistant answer with the given text to correct or force the answer/heartbeat: Send a heartbeat system message to the agent/memorywarning: Send a memory warning system message to the agent
Once you exit the CLI with /exit, you can resume chatting with the same agent by specifying the agent name in memgpt run --agent <NAME>.
See full documentation at: https://memgpt.readme.io
To install MemGPT from source, start by cloning the repo:
git clone git@github.com:cpacker/MemGPT.gitThen navigate to the main MemGPT directory, and do:
pip install -e .Now, you should be able to run memgpt from the command-line using the downloaded source code.
If you are having dependency issues using pip install -e ., we recommend you install the package using Poetry (see below). Installing MemGPT from source using Poetry will ensure that you are using exact package versions that have been tested for the production build.
Installing from source (using Poetry)
First, install Poetry using the official instructions here.
Then, you can install MemGPT from source with:
git clone git@github.com:cpacker/MemGPT.git
poetry shell
poetry installThe fastest way to integrate MemGPT with your own Python projects is through the MemGPT client:
from memgpt import create_client
# Connect to the server as a user
client = create_client()
# Create an agent
agent_info = client.create_agent(
name="my_agent",
persona="You are a friendly agent.",
human="Bob is a friendly human."
)
# Send a message to the agent
messages = client.user_message(agent_id=agent_info.id, message="Hello, agent!")When using MemGPT with open LLMs (such as those downloaded from HuggingFace), the performance of MemGPT will be highly dependent on the LLM's function calling ability.
You can find a list of LLMs/models that are known to work well with MemGPT on the #model-chat channel on Discord, as well as on this spreadsheet.
To evaluate the performance of a model on MemGPT, simply configure the appropriate model settings using memgpt configure, and then initiate the benchmark via memgpt benchmark. The duration will vary depending on your hardware. This will run through a predefined set of prompts through multiple iterations to test the function calling capabilities of a model.
You can help track what LLMs work well with MemGPT by contributing your benchmark results via this form, which will be used to update the spreadsheet.
For issues and feature requests, please open a GitHub issue or message us on our #support channel on Discord.
Datasets used in our paper can be downloaded at Hugging Face.
You can view (and comment on!) the MemGPT developer roadmap on GitHub: cpacker#1044.