A curated list of resources for Document Understanding (DU) topic related to Intelligent Document Processing (IDP), which is relative to Robotic Process Automation (RPA) from unstructured data, especially form Visually Rich Documents (VRDs).
Note 1: bolded positions are more important then others.
Note 2: due to the novelty of the field, this list is under construction - contributions are welcome (thank you in advance!). Please remember to use following convention:
- Title of a publication / dataset / resource title, [code/data/Website
]
List of authors Conference/Journal name Year
Dataset size: Train(no of examples), Dev(no of examples), Test(no of examples) [Optional for dataset papers/resources]; Abstract/short description ...

Documents are a core part of many businesses in many fields such as law, finance, and technology among others. Automatic understanding of documents such as invoices, contracts, and resumes is lucrative, opening up many new avenues of business. The fields of natural language processing and computer vision have seen tremendous progress through the development of deep learning such that these methods have started to become infused in contemporary document understanding systems. source
- Business Document Information Extraction: Towards Practical Benchmarks
Matyáš Skalický, Štěpán Šimsa, Michal Uřičář, Milan Šulc CLEF 2022
Information extraction from semi-structured documents is crucial for frictionless business-to-business (B2B) communication. While machine learning problems related to Document Information Extraction (IE) have been studied for decades, many common problem definitions and benchmarks do not reflect domain-specific aspects and practical needs for automating B2B document communication. We review the landscape of Document IE problems, datasets and benchmarks. We highlight the practical aspects missing in the common definitions and define the Key Information Localization and Extraction (KILE) and Line Item Recognition (LIR) problems. There is a lack of relevant datasets and benchmarks for Document IE on semi-structured business documents as their content is typically legally protected or sensitive. We discuss potential sources of available documents including synthetic data.
-
Document AI: Benchmarks, Models and Applications
Lei Cui, Yiheng Xu, Tengchao Lv, Furu Wei arxiv 2021
Document AI, or Document Intelligence, is a relatively new research topic that refers to the techniques for automatically reading, understanding, and analyzing business documents. It is an important research direction for natural language processing and computer vision. In recent years, the popularity of deep learning technology has greatly advanced the development of Document AI, such as document layout analysis, visual information extraction, document visual question answering, document image classification, etc. This paper briefly reviews some of the representative models, tasks, and benchmark datasets. Furthermore, we also introduce early-stage heuristic rule-based document analysis, statistical machine learning algorithms, and deep learning approaches especially pre-training methods. Finally, we look into future directions for Document AI research. -
Dipali Baviskar, Swati Ahirrao, Vidyasagar Potdar, Ketan Kotecha IEEE Access 2021
The unstructured data impacts 95% of the organizations and costs them millions of dollars annually. If managed well, it can significantly improve business productivity. The traditional information extraction techniques are limited in their functionality, but AI-based techniques can provide a better solution. A thorough investigation of AI-based techniques for automatic information extraction from unstructured documents is missing in the literature. The purpose of this Systematic Literature Review (SLR) is to recognize, and analyze research on the techniques used for automatic information extraction from unstructured documents and to provide directions for future research. The SLR guidelines proposed by Kitchenham and Charters were adhered to conduct a literature search on various databases between 2010 and 2020. We found that: 1. The existing information extraction techniques are template-based or rule-based, 2. The existing methods lack the capability to tackle complex document layouts in real-time situations such as invoices and purchase orders, 3.The datasets available publicly are task-specific and of low quality. Hence, there is a need to develop a new dataset that reflects real-world problems. Our SLR discovered that AI-based approaches have a strong potential to extract useful information from unstructured documents automatically. However, they face certain challenges in processing multiple layouts of the unstructured documents. Our SLR brings out conceptualization of a framework for construction of high-quality unstructured documents dataset with strong data validation techniques for automated information extraction. Our SLR also reveals a need for a close association between the businesses and researchers to handle various challenges of the unstructured data analysis.
-
A Survey of Deep Learning Approaches for OCR and Document Understanding
Nishant Subramani, Alexandre Matton, Malcolm Greaves, Adrian Lam ML-RSA Workshop at NeurIPS 2020
Documents are a core part of many businesses in many fields such as law, finance, and technology among others. Automatic understanding of documents such as invoices, contracts, and resumes is lucrative, opening up many new avenues of business. The fields of natural language processing and computer vision have seen tremendous progress through the development of deep learning such that these methods have started to become infused in contemporary document understanding systems. In this survey paper, we review different techniques for document understanding for documents written in English and consolidate methodologies present in literature to act as a jumping-off point for researchers exploring this area. -
Conversations with Documents. An Exploration of Document-Centered Assistance
Maartje ter Hoeve, Robert Sim, Elnaz Nouri, Adam Fourney, Maarten de Rijke, Ryen W. White CHIIR 2020
The role of conversational assistants has become more prevalent in helping people increase their productivity. Document-centered assistance, for example to help an individual quickly review a document, has seen less significant progress, even though it has the potential to tremendously increase a user's productivity. This type of document-centered assistance is the focus of this paper. Our contributions are three-fold: (1) We first present a survey to understand the space of document-centered assistance and the capabilities people expect in this scenario. (2) We investigate the types of queries that users will pose while seeking assistance with documents, and show that document-centered questions form the majority of these queries. (3) We present a set of initial machine learned models that show that (a) we can accurately detect document-centered questions, and (b) we can build reasonably accurate models for answering such questions. These positive results are encouraging, and suggest that even greater results may be attained with continued study of this interesting and novel problem space. Our findings have implications for the design of intelligent systems to support task completion via natural interactions with documents.
- Future paradigms of automated processing of business documents
Matteo Cristania, Andrea Bertolasob, Simone Scannapiecoc, Claudio Tomazzolia International Journal of Information Management 2018
In this paper we summarize the results obtained so far in the communities interested in the development of automated processing techniques as applied to business documents, and devise a few evolutions that are demanded by the current stage of either those techniques by themselves or by collateral sector advancements. It emerges a clear picture of a field that has put an enormous effort in solving problems that changed a lot during the last 30 years, and is now rapidly evolving to incorporate document processing into workflow management systems on one side and to include features derived by the introduction of cloud computing technologies on the other side. We propose an architectural schema for business document processing that comes from the two above evolution lines.
-
Machine Learning for Intelligent Processing of Printed Documents
F. Esposito, D. Malerba, F. Lisi - 2004
A paper document processing system is an information system component which transforms information on printed or handwritten documents into a computer-revisable form. In intelligent systems for paper document processing this information capture process is based on knowledge of the specific layout and logical structures of the documents. This article proposes the application of machine learning techniques to acquire the specific knowledge required by an intelligent document processing system, named WISDOM++, that manages printed documents, such as letters and journals. Knowledge is represented by means of decision trees and first-order rules automatically generated from a set of training documents. In particular, an incremental decision tree learning system is applied for the acquisition of decision trees used for the classification of segmented blocks, while a first-order learning system is applied for the induction of rules used for the layout-based classification and understanding of documents. Issues concerning the incremental induction of decision trees and the handling of both numeric and symbolic data in first-order rule learning are discussed, and the validity of the proposed solutions is empirically evaluated by processing a set of real printed documents. -
Document Understanding: Research Directions
S. Srihari, S. Lam, V. Govindaraju, R. Srihari, J. Hull - 1994
A document image is a visual representation of a printed page such as a journal article page, a facsimile cover page, a technical document, an office letter, etc. Document understanding as a research endeavor consists of studying all processes involved in taking a document through various representations: from a scanned physical document to high-level semantic descriptions of the document. Some of the types of representation that are useful are: editable descriptions, descriptions that enable exact reproductions and high-level semantic descriptions about document content. This report is a definition of five research subdomains within document understanding as pertaining to predominantly printed documents. The topics described are: modular architectures for document understanding; decomposition and structural analysis of documents; model-based OCR; table, diagram and image understanding; and performance evaluation under distortion and noise.
- Key Information Extraction (KIE)
- Document Layout Analysis (DLA)
- Document Question Answering (DQA)
- Scientific Document Understanding (SDU)
- Optical Character Recogtion (OCR)
- Related
- The RVL-CDIP Dataset - dataset consists of 400,000 grayscale images in 16 classes, with 25,000 images per class
- The Industry Documents Library - a portal to millions of documents created by industries that influence public health, hosted by the UCSF Library
- Color Document Dataset - from the Intelligent Sensory Information Systems, University of Amsterdam
- The IIT CDIP Collection - dataset consists of documents from the states' lawsuit against the tobacco industry in the 1990s, consists of around 7 million documents
- borb
- is a pure python library to read, write and manipulate PDF documents. It represents a PDF document as a JSON-like datastructure of nested lists, dictionaries and primitives (numbers, string, booleans, etc).
- pawls
- PDF Annotations with Labels and Structure is software that makes it easy to collect a series of annotations associated with a PDF document
- pdfplumber
- Plumb a PDF for detailed information about each text character, rectangle, and line. Plus: Table extraction and visual debugging
- Pdfminer.six
- Pdfminer.six is a community maintained fork of the original PDFMiner. It is a tool for extracting information from PDF documents. It focuses on getting and analyzing text data
- Layout Parser
- Layout Parser is a deep learning based tool for document image layout analysis tasks
- Tabulo
- Table extraction from images
- OCRmyPDF
- OCRmyPDF adds an OCR text layer to scanned PDF files, allowing them to be searched or copy-pasted
- PDFBox
- The Apache PDFBox library is an open source Java tool for working with PDF documents. This project allows creation of new PDF documents, manipulation of existing documents and the ability to extract content from documents
- PdfPig
- This project allows users to read and extract text and other content from PDF files. In addition the library can be used to create simple PDF documents containing text and geometrical shapes. This project aims to port PDFBox to C#
- parsing-prickly-pdfs
- Resources and worksheet for the NICAR 2016 workshop of the same name
- pdf-text-extraction-benchmark
- PDF tools benchmark
- Born digital pdf scanner
- checking if pdf is born-digital
- OpenContracts
Apache2-licensed, PDF annotating platform for visually-rich documents that preserves the original layout and exports x,y positional data for tokens as well as span starts and stops. Based on PAWLs, but with a Python-based backend and readily deployable on your local machine, company intranet or the web via Docker Compose.













- International Conference on Document Analysis and Recognition (ICDAR) [2021, 2019, 2017]
- Workshop on Document Intelligence (DI) [2021, 2019]
- Financial Narrative Processing Workshop (FNP) [2021, 2020, 2019 ]
- Workshop on Economics and Natural Language Processing (ECONLP) [2021, 2019, 2018 ]
- INTERNATIONAL WORKSHOP ON DOCUMENT ANALYSIS SYSTEMS (DAS) [2020, 2018, 2016]
- ACM International Conference on AI in Finance (ICAIF)
- The AAAI-21 Workshop on Knowledge Discovery from Unstructured Data in Financial Services
- CVPR 2020 Workshop on Text and Documents in the Deep Learning Era
- KDD Workshop on Machine Learning in Finance (KDD MLF 2020)
- FinIR 2020: The First Workshop on Information Retrieval in Finance
- 2nd KDD Workshop on Anomaly Detection in Finance (KDD 2019)
- Document Understanding Conference (DUC 2007)
- The AAAI-21 Workshop on Scientific Document Understanding (SDU 2021)
- First Workshop on Scholarly Document Processing (SDProc 2020)
- International Workshop on SCIentific DOCument Analysis (SCIDOCA) [2020, 2018, 2017 ]
- A Survey of Document Understanding Models, 2021
- Document Form Extraction, 2021
- How to automate processes with unstructured data, 2021
- A Comprehensive Guide to OCR with RPA and Document Understanding, 2021
- Information Extraction from Receipts with Graph Convolutional Networks, 2021
- How to extract structured data from invoices, 2021
- Extracting Structured Data from Templatic Documents, 2020
- To apply AI for good, think form extraction, 2020
- UiPath Document Understanding Solution Architecture and Approach, 2020
- How Can I Automate Data Extraction from Complex Documents?, 2020
- LegalTech: Information Extraction in legal documents, 2020
Big companies:
Smaller:
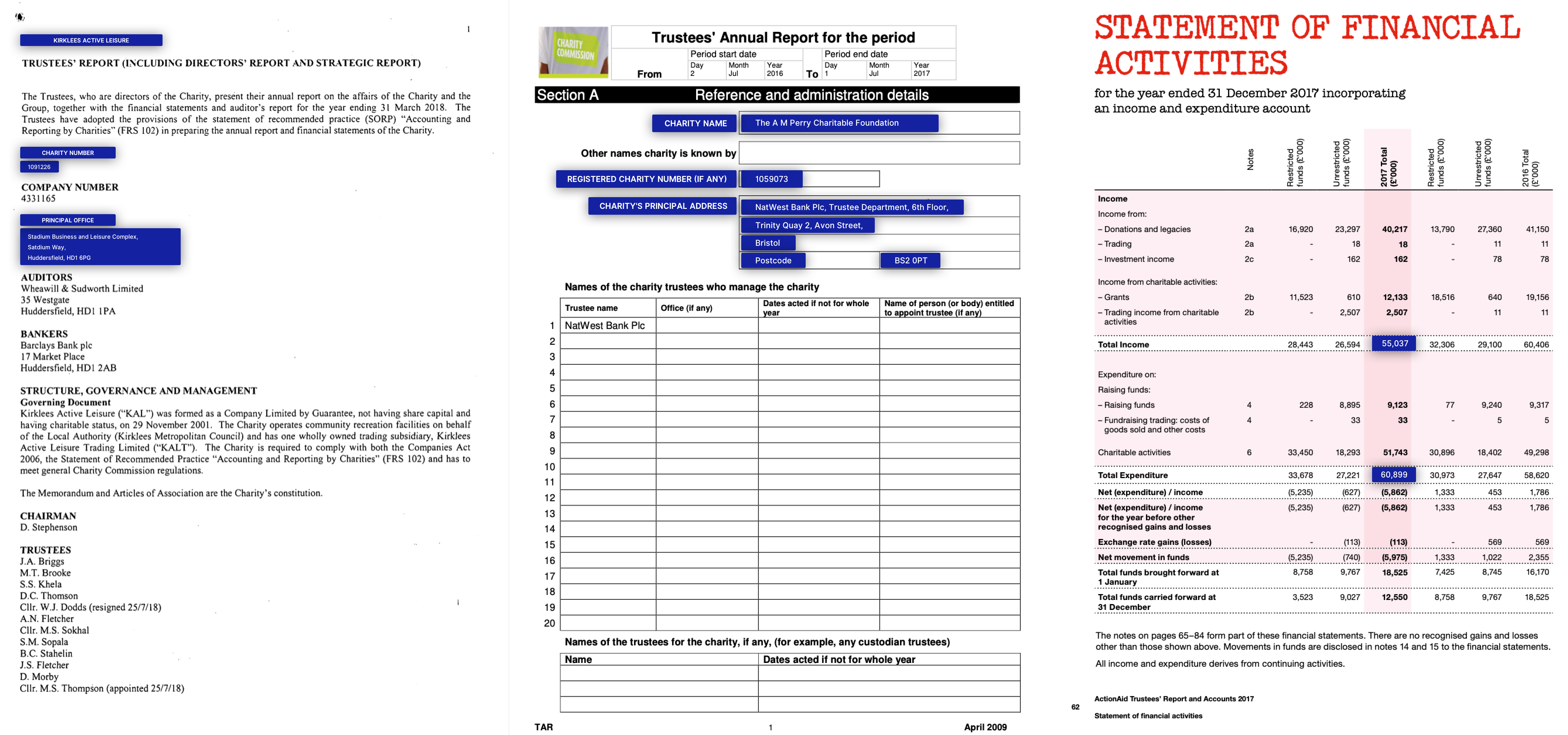
In VRDs the importance of the layout information is crucial to understand the whole document correctly (this is the case with almost all business documents). For humans spatial information improves readability and speeds document understanding.


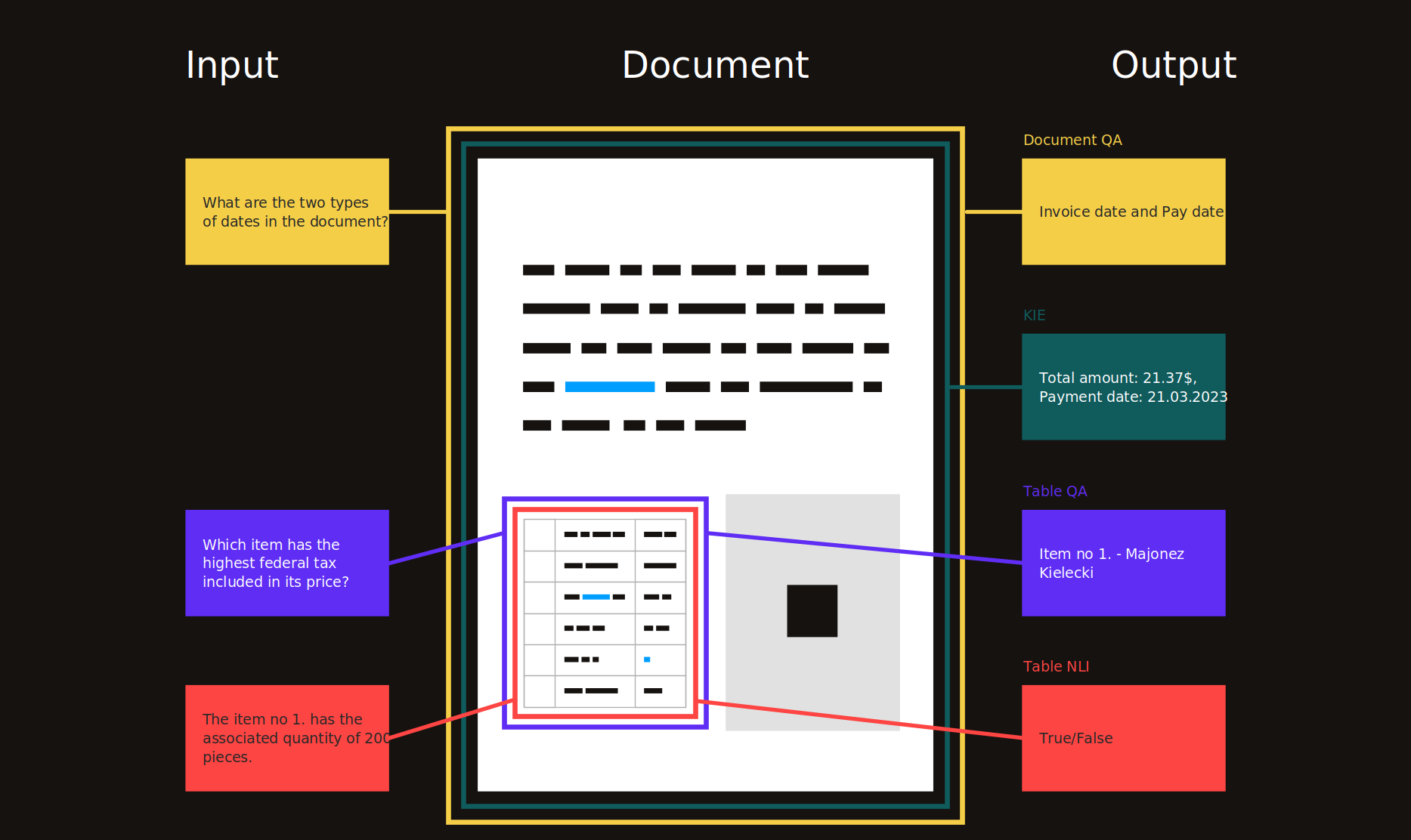
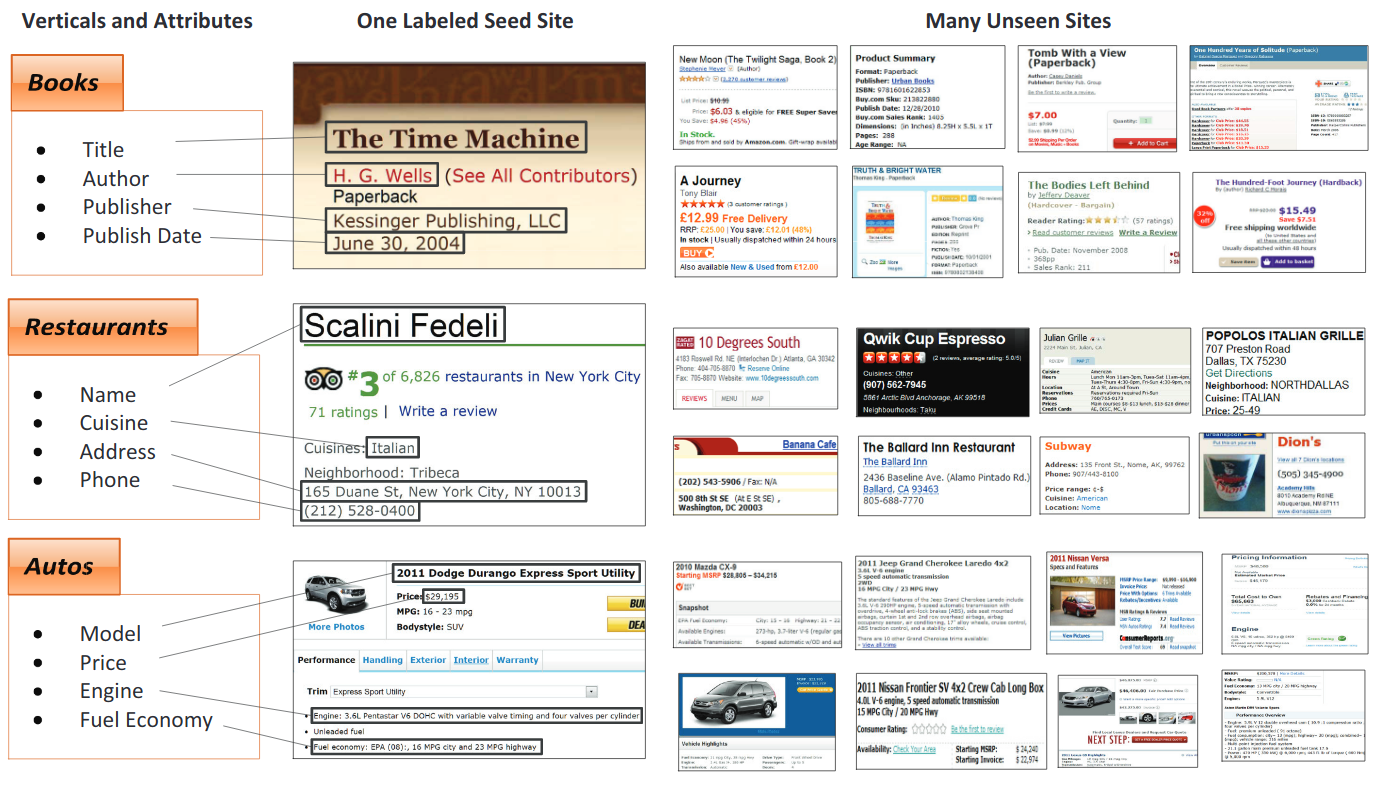
The aim of this task is to extract texts of a number of key fields from a given collection of documents containing similar key entities.
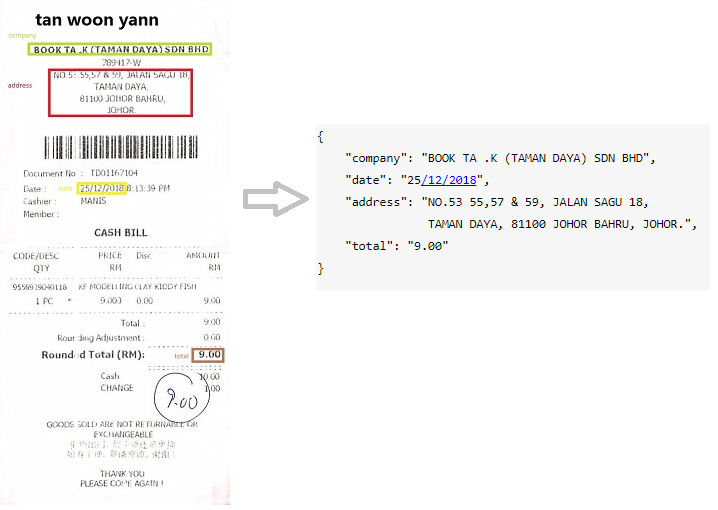
Examples of a real business applications and data for Kleister datasets (The key entities are in blue)
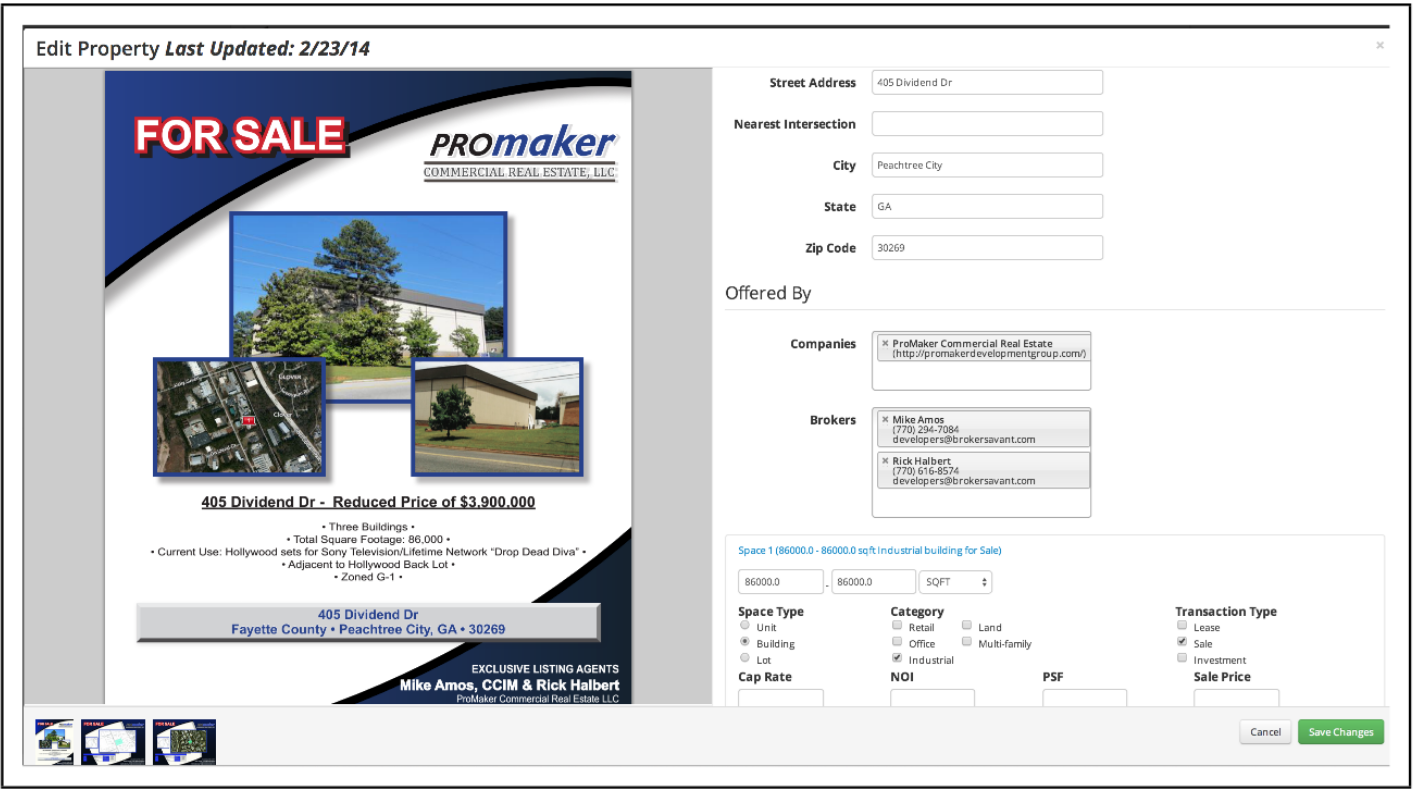
An example of a commercial real estate flyer and manually entered listing information © ProMaker Commercial Real Estate LLC, © BrokerSavant Inc.

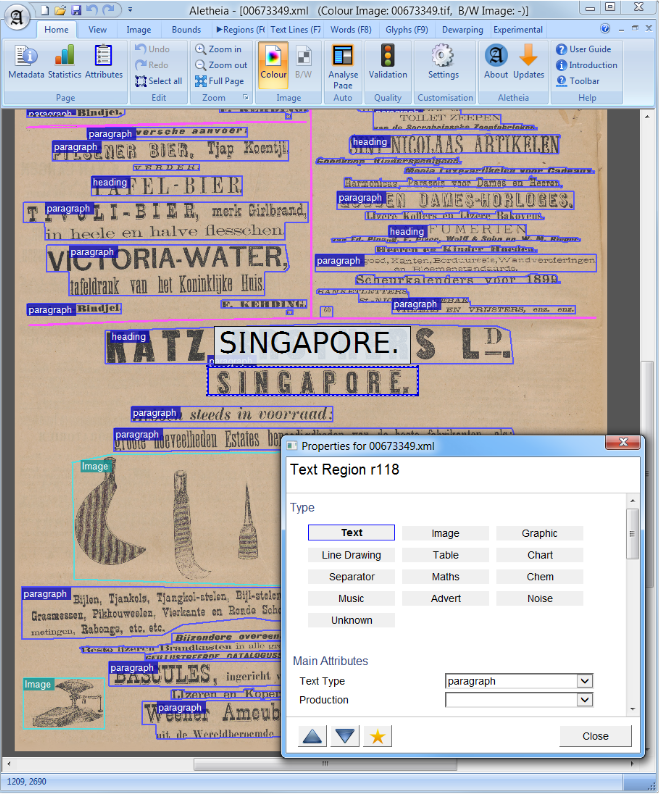
In computer vision or natural language processing, document layout analysis is the process of identifying and categorizing the regions of interest in the scanned image of a text document. A reading system requires the segmentation of text zones from non-textual ones and the arrangement in their correct reading order. Detection and labeling of the different zones (or blocks) as text body, illustrations, math symbols, and tables embedded in a document is called geometric layout analysis. But text zones play different logical roles inside the document (titles, captions, footnotes, etc.) and this kind of semantic labeling is the scope of the logical layout analysis. (https://en.wikipedia.org/wiki/Document_layout_analysis)
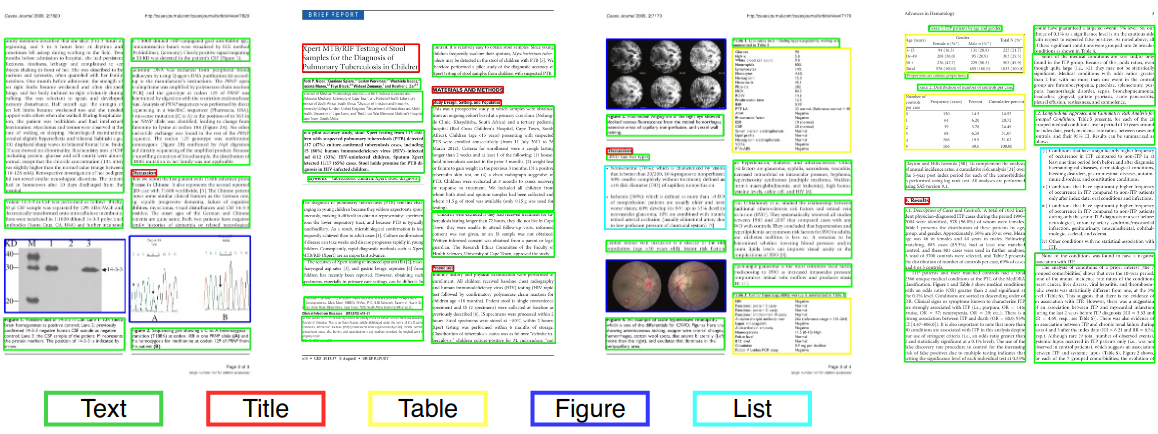

Red: text block, Blue: figure.


Tilt model demo
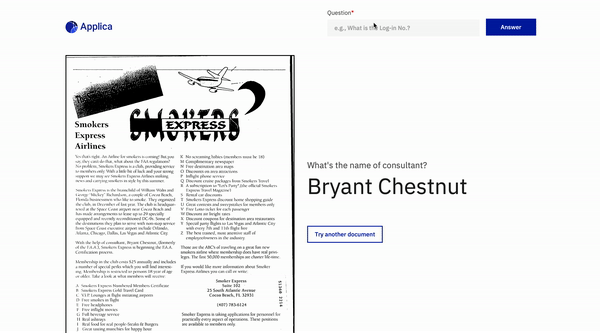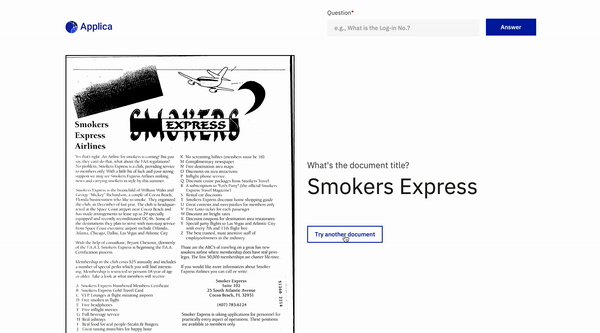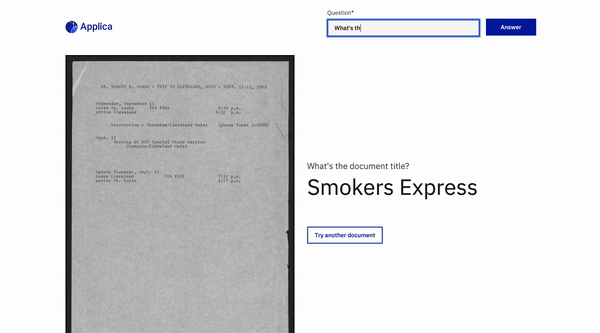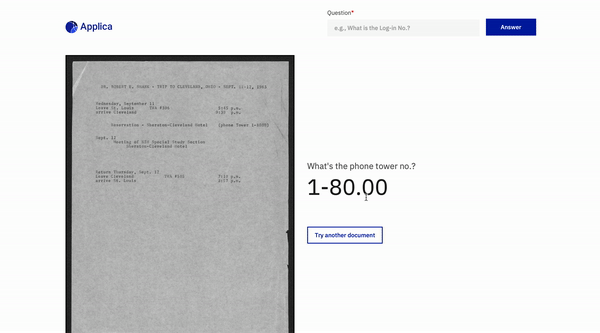
Domain
- https://github.com/kba/awesome-ocr
- https://github.com/Liquid-Legal-Institute/Legal-Text-Analytics
- https://github.com/icoxfog417/awesome-financial-nlp
- https://github.com/BobLd/DocumentLayoutAnalysis
- https://github.com/bikash/DocumentUnderstanding
- https://github.com/harpribot/awesome-information-retrieval
- https://github.com/roomylee/awesome-relation-extraction
- https://github.com/caufieldjh/awesome-bioie
- https://github.com/HelloRusk/entity-related-papers
- https://github.com/pliang279/awesome-multimodal-ml
- https://github.com/thunlp/LegalPapers
- https://github.com/heartexlabs/awesome-data-labeling












General AI/DL/ML
- https://github.com/jsbroks/awesome-dataset-tools
- https://github.com/EthicalML/awesome-production-machine-learning
- https://github.com/eugeneyan/applied-ml
- https://github.com/awesomedata/awesome-public-datasets
- https://github.com/keon/awesome-nlp
- https://github.com/thunlp/PLMpapers
- https://github.com/jbhuang0604/awesome-computer-vision#awesome-lists
- https://github.com/papers-we-love/papers-we-love
- https://github.com/BAILOOL/DoYouEvenLearn
- https://github.com/hibayesian/awesome-automl-papers









