Flexible self-contained PostgreSQL metrics monitoring/dashboarding solution
Note: has a self-signed certificate as configured out the box in Docker, so you need to click "Allow / Add exception / Trust" or similar
For the fastest installation / setup experience Docker images are provided via Docker Hub (for a Docker quickstart see here). For doing a custom setup see the "Installing without Docker" paragraph below or turn to the "releases" tab for DEB / RPM / Tar packages.
# fetch and run the latest Docker image, exposing Grafana on port 3000 and administrative web UI on 8080
docker run -d -p 3000:3000 -p 8080:8080 -e PW2_TESTDB=true --name pw2 cybertec/pgwatch2
After some minutes you could open the "db-overview" dashboard and start looking at metrics. For defining your own dashboards you need to log in as admin (admin/pgwatch2admin). NB! If you don't want to add the "test" database (the pgwatch2 configuration db) for monitoring set the NOTESTDB=1 env parameter when launching the image.
For production setups without a container management framework also "--restart unless-stopped" (or custom startup scripts) is highly recommended. Also exposing the config/metrics database ports for backups and usage of volumes is then recommended to enable easier updating to newer pgwatch2 Docker images without going through the backup/restore procedure described towards the end of README. For maximum flexibility, security and update simplicity though, best would to do a custom setup - see paragraph "Installing without Docker" towards the end of README for that.
for v in pg influx grafana pw2 ; do docker volume create $v ; done
# with InfluxDB for metrics storage
docker run -d --name pw2 -v pg:/var/lib/postgresql -v influx:/var/lib/influxdb -v grafana:/var/lib/grafana -v pw2:/pgwatch2/persistent-config -p 8080:8080 -p 3000:3000 -e PW2_TESTDB=true cybertec/pgwatch2
# with Postgres for metrics storage
docker run -d --name pw2 -v pg:/var/lib/postgresql -v grafana:/var/lib/grafana -v pw2:/pgwatch2/persistent-config -p 8080:8080 -p 3000:3000 -e PW2_TESTDB=true cybertec/pgwatch2-postgres
For more advanced usecases (production setup with backups) or for easier problemsolving you can decide to expose all services
# run with all ports exposed
docker run -d --restart unless-stopped -p 3000:3000 -p 5432:5432 -p 8086:8086 -p 8080:8080 -p 8081:8081 -p 8088:8088 -v ... --name pw2 cybertec/pgwatch2
NB! For production usage make sure you also specify listening IPs explicitly (-p IP:host_port:container_port), by default Docker uses 0.0.0.0 (all network devices).
For custom options, more security, or specific component versions one could easily build the image themselves, just Docker needed:
docker build .
For a complete list of all supported Docker environment variables see ENV_VARIABLES.md
- Non-invasive setup, no extensions nor superuser rights required for the base functionality
- Intuitive metrics presentation using the Grafana dashboarding engine with optional Alerting
- Lots of pre-configured dashboards and metric configurations covering all Statistics Collector data
- Easy extensibility by defining metrics in pure SQL (thus they could also be from business domain)
- 4 supported data stores for metrics storage (PostgreSQL, InfluxDB, Graphite, Prometheus)
- Multiple configuration options (YAML, PostgreSQL, ENV) supporting both "push" and "pull" models
- Possible to monitoring all or a subset of DBs of a PostgreSQL cluster
- Global or DB level configuration of metrics/intervals
- Kubernetes/OpenShift ready
- PgBouncer, AWS RDS and Patroni support
- Internal health-check API to monitor metrics gathering status
- Built-in security with SSL connections and passwords encryption
- Very low resource requirements for the collector even when monitoring hundreds of DBs
For more background on the project motivations and design goals see the original series of blogposts announcing the project:
- Project announcement
- Implementation details
- Feature pack 1
- Feature pack 2
- Feature pack 3
- Feature pack 4
- Min 1GB RAM required for Docker setup. Just the gatherer needs <50MB if metric strore is up, otherwise metrics are cached in RAM up to a limit of 10k data points.
- 2 GBs of disk space should be enough for monitoring 1 DB for 1 month with InfluxDB. 1 month is also the default metrics retention policy for Influx running in Docker (configurable). Depending on the amount of schema objects - tables, indexes, stored procedures and especially on number of unique SQL-s, it could be also much more. With Postgres as metric store multiply it with ~5x. There's also a "test data generation" mode in the collector to exactly determine disk footprint - see PW2_TESTDATA_DAYS and PW2_TESTDATA_MULTIPLIER params for that (requires also "ad-hoc" mode params).
- A low-spec (1 vCPU, 2 GB RAM) cloud machine can easily monitor 100 DBs in "exhaustive" settings (i.e. almost all metrics are monitored in 1-2min intervals) without breaking a sweat (<20% load). When a single node where the metrics collector daemon is running is becoming a bottleneck, one can also do "sharding" i.e. limit the amount of monitored databases for that node based on the Group label(s) (--group), which is just a string for logical grouping.
- A single InfluxDB node should handle thousands of requests per second but if this is not enough having a secondary/mirrored InfluxDB is also possible. If more than two needed (e.g. feeding many many Grafana instances or some custom exporting) one should look at Influx Enterprise (on-prem or cloud) or Graphite (which is also supported as metrics storage backend). For PostgreSQL metrics storage one could use streaming replicas for read scaling or for example Citus for write scaling.
- When high metrics write latency is problematic (e.g. using a DBaaS across the atlantic) then increasing the default maximum batching delay of 250ms(--batching-delay-ms / PW2_BATCHING_MAX_DELAY_MS) could give good results.
Settings can be configured for most components, but by default the Docker image doesn't focus on security though but rather on being quickly usable for ad-hoc performance troubleshooting.
- No noticable impact for the monitored DB is expected with the default settings. For some metrics though can happen that the metric reading query (notably "stat_statements") takes some milliseconds, which might be more than an average application query. At any time only 2 metric fetching queries are running in parallel on the monitored DBs, with 5s per default "statement timeout", except for the "bloat" metrics where it is 15min.
- Starting from v1.3.0 there's a non-root Docker version available (suitable for OpenShift)
- The administrative Web UI doesn't have by default any security. Configurable via env. variables.
- Viewing Grafana dashboards by default doesn't require login. Editing needs a password. Configurable via env. variables.
- InfluxDB has no authentication in Docker setup, so one should just not expose the ports when having concerns.
- Dashboards based on "pg_stat_statements" (Stat Statement Overview / Top) expose actual queries. They are mostly stripped of details though, but if no risks can be taken the dashboards (or at least according panels) should be deleted. As an alternative "pg_stat_statements_calls" can be used, which only records total runtimes and call counts.
- Safe certificate connections to Postgres are supported as of v1.5.0
- Encrypting/decrypting passwords stored in the config DB or in YAML config files possible from v1.5.0. An encryption passphrase/file needs to be specified then via PW2_AES_GCM_KEYPHRASE / PW2_AES_GCM_KEYPHRASE_FILE. By default passwords are stored in plaintext.
Alerting is very conveniently (point-and-click style) provided by Grafana - see here for documentation. All most popular notification services are supported. A hint - currently you can set alerts only on Graph panels and there must be no variables used in the query so you cannot use the pre-created pgwatch2 graphs.
If more complex scenarios/check conditions are required TICK stack and Kapacitor can be easily integrated - see here for more details.
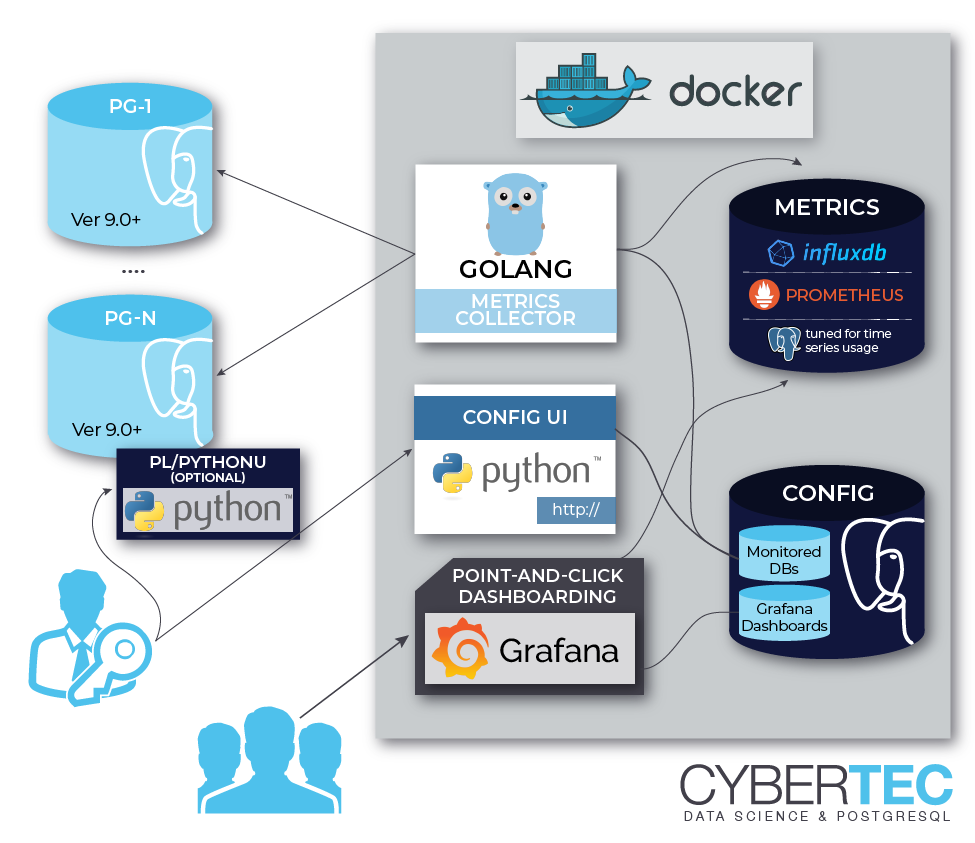
- pgwatch2 metrics gathering daemon / collector written in Go
- Configuration store saying which databases and metrics to gather (3 options):
- A PostgreSQL database
- YAML config files + SQL metrics files
- A temporary "ad-hoc" config i.e. just a single connect string (JDBC or Libpq type) for "throwaway" usage
- Metrics storage DB (4 options)
- InfluxDB Time Series Database for storing metrics.
- PostgreSQL - world's most advanced Open Source RDBMS (based on JSONB, 9.4+ required). See "To use an existing Postgres DB for storing metrics" section below for setup details.
- Graphite (no custom_tags and request batching support)
- JSON files (for testing / special use cases)
- Grafana for dashboarding (point-and-click, a set of predefined dashboards is provided)
- An optional simple Web UI for administering the monitored DBs and metrics and for showing some custom metric overviews, if using PostgreSQL for storing config
NB! All component can be also used separately, thus you can decide to make use of an already existing installation of Postgres, Grafana or InfluxDB and run the pgwatch2 image for example only with the metrics gatherer and the configuration Web UI. These external installations must be accessible from within the Docker though. For info on installation without Docker at all see end of README.
Create a new pgwatch2 DB, preferrably also an accroding role who owns it. Then roll out the schema (pgwatch2/sql/config_store/config_store.sql) and set the following parameters when running the image: PW2_PGHOST, PW2_PGPORT, PW2_PGDATABASE, PW2_PGUSER, PW2_PGPASSWORD, PW2_PGSSL (optional).
Load the pgwatch2 dashboards from grafana_dashboard folder if needed (one can totally define their own) and set the following paramater: PW2_GRAFANA_BASEURL. This parameter only provides correct links to Grafana dashboards from the Web UI. Grafana is the most loosely coupled component for pgwatch2 and basically doesn't have to be used at all. One can make use of the gathered metrics directly over the Influx (or Graphite) API-s.
Set the following env variables: PW2_IHOST, PW2_IPORT, PW2_IDATABASE, PW2_IUSER, PW2_IPASSWORD, PW2_ISSL (optional)
One can also store the metrics in Graphite instead of InfluxDB (no predefined pgwatch2 dashboards for Graphite though). Following parameters needs to be set then: PW2_DATASTORE=graphite, PW2_GRAPHITEHOST, PW2_GRAPHITEPORT
- Roll out the metrics storage schema according to instructions from here
- Following parameters needs to be set for the gatherer:
- --datastore=postgres or PW2_DATASTORE=postgres
- --pg-metric-store-conn-str="postgresql://user:pwd@host:port/db" or PW2_PG_METRIC_STORE_CONN_STR="..."
- optionally also adjust the --pg-retention-days parameter. By default 30 days (at least) of metrics are kept
- If using the Web UI also set the first two parameters (--datastore and --pg-metric-store-conn-str) there, if wanting to clean up data via the UI.
NB! The schema rollout script activates "asynchronous commiting" feature for the metrics storing user role by default!
If this is not wanted (no metrics can be lost in case of a crash), then re-enstate normal (synchronous) commits with:
ALTER ROLE pgwatch2 IN DATABASE $MY_METRICS_DB SET synchronous_commit TO on
- by default the "pgwatch2" configuration database running inside Docker is being monitored so that you can immediately see some graphs, but you should add new databases by opening the "admin interface" at 127.0.0.1:8080/dbs or logging into the Postgres config DB and inserting into "pgwatch2.monitored_db" table (db - pgwatch2 , default user/pw - pgwatch2/pgwatch2admin). Note that it can take up to 2min before you see any metrics for newly inserted databases.
- one can create new Grafana dashboards (and change settings, create users, alerts, ...) after logging in as "admin" (admin/pgwatch2admin)
- metrics (and their intervals) that are to be gathered can be customized for every database by using a preset config like "minimal", "basic" or "exhaustive" (monitored_db.preset_config table) or a custom JSON config.
- to add a new metrics yourself (simple SQL queries returing point-in-time values) head to http://127.0.0.1:8080/metrics. The queries should always include a "epoch_ns" column and "tag_" prefix can be used for columns that should be tags (thus indexed) in InfluxDB.
- a list of available metrics together with some instructions is also visible from the "Documentation" dashboard
- some predefine metrics (cpu_load, stat_statements) require installing helper functions (look into "pgwatch2/sql" folder) on monitored DBs
- for effective graphing you want to familiarize yourself with basic InfluxQL and the non_negative_derivative() function which is very handy as Postgres statistics are mostly evergrowing counters. Documentation here.
- for troubleshooting, logs for the components are visible under http://127.0.0.1:8080/logs/[pgwatch2|postgres|webui|influxdb|grafana] or by logging into the docker container under /var/logs/supervisor/
- As a base requirement you'll need a login user (non-superuser suggested) for connecting to your server and fetching metrics queries. NB! Though theoretically you can use any username you like, but if not using "pgwatch2" you need to adjust the "helper" creation SQL scripts accordingly as in those by default only the "pgwatch2" will be granted execute privileges.
CREATE ROLE pgwatch2 WITH LOGIN PASSWORD 'secret';
-- NB! For very important databases it might make sense to ensure that the user
-- account used for monitoring can only open a limited number of connections (there are according checks in code also though)
ALTER ROLE pgwatch2 CONNECTION LIMIT 3;
GRANT pg_monitor TO pgwatch2; // v10+
- If monitoring below v10 servers and not using superuser and don't also want to grant "pg_monitor" to the monitoring user, define the helper function to enable monitoring of some "protected" internal information, like active sessions info. If using a superuser login (not recommended for remote "pulling", but only "pushing") you can skip this step.
psql -h mydb.com -U superuser -f pgwatch2/sql/metric_fetching_helpers/stat_activity_wrapper.sql mydb
- Additionally for extra insights ("Stat statements" dashboard and CPU load) it's also recommended to install the
pg_stat_statementcontrib extension (Postgres 9.2+ needed to be useful for pgwatch2) and the PL/Python language. The latter one though is usually disabled by DB-as-a-service providers for security reasons. For maximum pg_stat_statement benefit ("Top queries by IO time" dashboard), one should also then enable the track_io_timing setting.
# add pg_stat_statements to your postgresql.conf and restart the server
shared_preload_libraries = 'pg_stat_statements'
After restarting the server install the extensions as superuser
CREATE EXTENSION pg_stat_statements;
CREATE EXTENSION plpythonu;
Now also install the wrapper functions (under superuser role) for enabling "Stat statement" and CPU load info fetching for non-superusers
psql -h mydb.com -U superuser -f pgwatch2/sql/metric_fetching_helpers/stat_statements_wrapper.sql mydb
psql -h mydb.com -U superuser -f pgwatch2/sql/metric_fetching_helpers/cpu_load_plpythonu.sql mydb
For more detailed statistics (OS monitoring, table bloat, WAL size, etc) it is recommended to install also all other helpers
found from the pgwatch2/sql/metric_fetching_helpers folder (or pgwatch2/metrics/00_helpers for YAML based setup).
As of v1.6.0 though helpers are not needed for Postgres-native metrics (e.g. WAL size) if a privileged user (superuser or has pg_monitor GRANT)
is used as all Postres-protected metrics have also "privileged" SQL-s defined for direct access. Another good way to take
ensure that helpers get installed is to 1st run as superuser, by checking the Auto-create helpers? checkbox
(or "is_superuser: true" in YAML mode) when configuring databases and then switch to the normal unprivileged "pgwatch2" user.
NB! When rolling out helpers make sure the search_path is set correctly (same as monitoring role's) as metrics using the
helpers, assume that monitoring role's search_path includes everything needed i.e. they don't qualify any schemas.
-
When installing some "helpers" and laters doing a binary PostgreSQL upgrade via
pg_upgrade, this could result in some error messages thrown. Then just drop those failing helpers on the "to be upgraded" cluster and re-create them after the upgrade process. -
Starting from Postgres v10 helpers are mostly not needed (only for PL/Python ones getting OS statistics) - there are available some special monitoring roles like "pg_monitor", that are exactly meant to be used for such cases where we want to give access to all Statistics Collector views without any other "superuser behaviour". See here for documentation on such special system roles. Note that currently most out-of-the-box metrics first rely on the helpers as v10 is relatively new still, and only when fetching fails, direct access with the "Privileged SQL" is tried.
-
For gathering OS statistics (CPU, IO, disk) there are helpers and metrics provided, based on the "psutil" Python package...but from user reports seems the package behaviour differentiates slightly based on the Linux distro / Kernel version used, so small adjustments might be needed there (e.g. remove a non-existen column). Minimum usable Kernel version required is 3.3. Also note that SQL helpers functions are currently defined for Python 2, so for Python 3 you need to change the
LANGUAGE plpythonupart.
Helpers/wrappers are not needed actually, they just provide a bit more information. For unprivileged users (developers)
with no means to install any wrappers as superuser it's also possible to benefit from pgwatch2 - for such use cases e.g.
the "unprivileged" preset metrics profile and the according "DB overview Unprivileged / Developer" dashboard
is a good starting point as it only assumes existance of pg_stat_statements which is available at all cloud providers.

More screenshots here
- Dynamic management of monitored databases, metrics and their intervals - no need to restart/redeploy
- Safety
- Up to 2 concurrent queries per monitored database (thus more per cluster) are allowed
- Configurable statement timeouts per DB
- SSL connections support for safe over-the-internet monitoring (use "-e PW2_WEBSSL=1 -e PW2_GRAFANASSL=1" when launching Docker)
- Optional authentication for the Web UI and Grafana (by default freely accessible)
- Backup script (take_backup.sh) provided for taking snapshots of the whole Docker setup. To make it easier (run outside the container) one should to expose ports 5432 (Postgres) and 8088 (InfluxDB backup protocol) at least for the loopback address.
Ports exposed by the Docker image:
- 5432 - Postgres configuration (or metrics storage) DB
- 8080 - Management Web UI (monitored hosts, metrics, metrics configurations)
- 8081 - Gatherer healthcheck / statistics on number of gathered metrics (JSON).
- 3000 - Grafana dashboarding
- 8086 - InfluxDB API (when using the InfluxDB version)
- 8088 - InfluxDB Backup port (when using the InfluxDB version)
In the centrally managed (config DB based) mode, for easy configuration changes (adding databases to monitoring, adding metrics) there is a small Python Web application bundled (exposed on Docker port 8080), making use of the CherryPy Web-framework. For mass changes one could technically also log into the configuration database and change the tables in the “pgwatch2” schema directly. Besides managing the metrics gathering configurations, the two other useful features for the Web UI would be the possibility to look at the logs of the single components (when using Docker) and at the “Stat Statements Overview” page, which will e.g. enable finding out the query with the slowest average runtime for a time period.
By default the Web UI is not secured. If some security is needed then the following env. variables can be used to enforce password protection - PW2_WEBNOANONYMOUS, PW2_WEBUSER, PW2_WEBPASSWORD.
By default also the Docker component logs (Postgres, Influx, Grafana, Go daemon, Web UI itself) are exposed via the "/logs" endpoint. If this is not wanted set the PW2_WEBNOCOMPONENTLOGS env. variable.
- postgres - connect data to a single to-be-monitored DB needs to be specified. When using the Web UI and "DB name" field is left empty, then as a one time operation, all non-template DB names are fetched, prefixed with "Unique name" field value and added to monitoring (if not already monitored). Internally monitoring always happens "per DB" not "per cluster".
- postgres-continuous-discovery - connect data to a Postgres cluster (w/o a DB name) needs to be specified and then the metrics daemon will periodically scan the cluster (connecting to the "template1" database, which is expected to exist) and add any found and not yet monitored DBs to monitoring. In this mode it's also possible to specify regular expressions to include/exclude some database names.
- pgbouncer - use to track metrics from PgBouncer's "SHOW STATS" command. In place of the Postgres "DB name" the name of a PgBouncer "pool" to be monitored must be inserted.
- patroni - Patroni is a HA / cluster manager for Postgres that relies on a DCS (Distributed Consensus Store) to store it's state. Typically in such a setup the nodes come and go and also it should not matter who is currently the master. To make it easier to monitor such dynamic constellations pgwatch2 supports reading of cluster node info from all supported DCS-s (etcd, Zookeeper, Consul), but currently only for simpler cases with no security applied (which is actually the common case in a trusted environment).
- patroni-continuous-discovery - as normal Patroni but all DB (or only those matching regex patterns) are monitored.
NB! "continuous" modes expect / need access to the "template1" DB of the specified cluster.
When 'patroni' is selected for "DB type" then the usual host/port fields should be left empty ("dbname" still filled if only one database is to be monitored) and instead "Host config" JSON field should be filled with DCS address, type and scope (cluster) name) information. A sample config looks like:
{
"dcs_type": "etcd",
"dcs_endpoints": ["127.0.0.1:2379"],
"scope": "batman",
"namespace": "/service/"
}
For etcd also username, password, ca_file, cert_file, key_file optional parameters can be defined - other DCS systems are currently supported only without authentication.
Also if you don't use the replicas actively for queries then it might make sense to decrease the volume of gathered metrics and to disable the monitoring of standby-s with the "Master mode only?" checkbox.
There's a good set of pre-defined metrics & configs provided (and installed when using the Docker image) that should cover most people's needs, but when monitoring dozens of hosts the intervals should be probably adjusted to reduce data amounts.
Things to note:
- Some builtin metrics are marked to be only executed when server is a primary or conversely, a standby. The flags can be inspected on the Web UI Metrics tab.
- The "change_events" builtin metric used for detecting DDL & config changes uses internally some other "*_hashes" metrics which are not meant to be used on their own.
Metrics are named SQL queries that can return pretty much everything you find useful and which can have different query text versions for different target PostgreSQL versions. Correct version of the metric definition will be chosen automatically by regularly connecting to the target database and checking the Postgres version and if the monitoring user is a superuser or not. For superusers some metrics are re-defined (v1.6.2) so that no "helpers" are needed for Postgres-native Stats Collector infos. Using superuser accounts for monitoring is of course not really recommended.
For defining metrics definitions you should adhere to a couple of basic concepts though:
- Every metric query should have an “epoch_ns” (nanoseconds since epoch, default InfluxDB timestamp precision) column to record the metrics reading time. If the column is not there, things will still work though as gathering server’s timestamp will be used, you’ll just lose some milliseconds (assuming intra-datacenter monitoring) of precision.
- Queries can only return text, integer, boolean or floating point (a.k.a. double precision) Postgres data types. Note that columns with NULL values are not stored at all in the data layer as it's a bit bothersome to work with NULLs!
- Columns can be optionally “tagged” by prefixing them with “tag_”. By doing this, the column data
will be indexed by the InfluxDB / Postgres giving following advantages:
- Sophisticated auto-discovery support for indexed keys/values, when building charts with Grafana.
- Faster queries for queries on those columns.
- Less disk space used for repeating values in InfluxDB. Thus when you’re for example returning some longish and repetitive status strings (possible with Singlestat or Table panels) that you’ll be looking up by some ID column, it might still make sense to prefix the column with “tag_” to reduce disks space.
- Fixed per host "custom tags" are also supported - these can contain any key-value data important to user and are added to all captured data rows
- For Prometheus the numerical columns are by default mapped to a Value Type of "Counter" (as most Statistics Collector columns are cumulative), but when this is not the case and the column is a "Gauge" then according column attributes should be decalared. For YAML based setups this means adding a "column_attrs.yaml" file in the metric's top folder and for Config DB based setup an according "column_attrs" JSON column should be filled.
- NB! For Prometheus all text fields will be turned into tags / labels as only floats can be stored.
From v1.4.0 one can also deploy pgwatch2 gatherer daemons decentrally, based on YAML config files - for both metric definitions and "hosts to be monitored" definitions. In that case there is no need for the central Postgres "config DB". See "pgwatch2/config/instances.yaml" for sample config file and "pgwatch2/metrics" folder for metrics (and preset metric configuration) definitions. Relevant Gatherer env. vars / flags: PW2_CONFIG / --config, PW2_METRICS_FOLDER / --metrics-folder.
From v1.4.0 it's also possible to run the gatherer daemon in ad-hoc / test mode, by giving a single standard connection string as input, and optionally also specifying the metrics to monitor (preset config name or a custom JSON string). In that case there is no need for the central Postgres "config DB" nor the YAML file specifying which hosts to monitor. NB! When using that mode with the default Docker image, the built-in metric definitions can't be changed via the Web UI. Relevant Gatherer env. vars / flags: --adhoc-conn-str, --adhoc-config, --adhoc-name, --metrics-folder / PW2_ADHOC_CONN_STR, PW2_ADHOC_CONFIG, PW2_ADHOC_NAME, PW2_METRICS_FOLDER, PW2_ADHOC_CREATE_HELPERS.
# launching in ad-hoc / test mode
docker run --rm -p 3000:3000 -p 8080:8080 -e PW2_ADHOC_CONN_STR="postgresql://user:pwd@mydb:5432/mydb1" \
-e PW2_ADHOC_CONFIG=unprivileged --name pw2 cybertec/pgwatch2
# launching in ad-hoc / test mode, creating metrics helpers automatically (requires superuser)
docker run --rm -p 3000:3000 -p 8080:8080 -e PW2_ADHOC_CONN_STR="postgresql://user:pwd@mydb:5432/mydb1" \
-e PW2_ADHOC_CONFIG=exhaustive -e PW2_ADHOC_CREATE_HELPERS=true --name pw2 cybertec/pgwatch2
NB! Using PW2_ADHOC_CREATE_HELPERS (tries to create all of the metrics fetching helpers automatically on the monitored DB) assumes superuser privileges and does not clean up the helpers on exitings so for a permanent setting one could change the user to an unprivileged 'pgwatch2' user.
pgwatch2 code part doesn't need too much maintenance itself (most issues seem to be related to dashboards that users can actually change themselves) but the main components that pgwatch2 relies on (Grafana, InfluxDB) are pretty active and get useful features and fixes quite regularly, thus we'll also try to push new 'latest' images, so it would make sense to check for updates time to time on Docker Hub. NB! You could also choose to build your own image any time and the build scripts will download the latest components for you.
If possible (e.g. previously gathered metrics are not important and there are no user added dashboard/graphs) then the easiest way to get the latest Docker image would be just to stop the old one and doing 'docker pull/run' again as described in beginning of the README.
If using a custom setup, switching out single components should be quite easy, just follow the component provider's
instructions. Migrating data from the current Docker container to a newer version of the pgwatch2 Docker
image on the other hand needs quite some steps currently. See the take_backup.sh script
here for more details. To make updates a
bit easier, the preferred way should be though to think about it previously and use Docker volumes accordingly - see the
Dockerfile for details. On some rare occasions updating to newer pgwatch2 Web UI or gahterer daemon might additionally
still require rollout of some manual config DB schema migrations scripts from the "migrations" subfolder - error messages
will include "missing columns" or "wrong datatype" then. SQL "patches" might be provided also for important metric updates,
but for dashboard changes there will be none - users need to import them from JSON directly!
Basically there are two options – first, go into the Docker container (e.g. docker exec -it pw2 /bin/bash) and just update the component yourself – i.e. download the latest Grafana .deb package and install it with “dpkg -i …”. This is actually the simplest way. The other way would be to fetch the latest pgwatch2 image, which already has the latest version of components, using “docker pull” and then restore the data (InfluxDB + Postgres) from a backup of old setup. For restoring one needs to go inside the Docker container again but by following the steps described in take_backup.sh it shouldn't be a real problem.
A tip: to make the restore process easier it would already make sense to mount the host folder with the backups in it on the new container with “-v ~/pgwatch2_backups:/pgwatch2_backups:rw,z” when starting the Docker image. Otherwise one needs to set up SSH or use something like S3 for example. Also note that ports 5432 and 8088 need to be exposed to take backups outside of Docker.
Below are sample steps to do a custom install from scratch using a Postgres configuration DB for both pgwatch2 config and Grafana config. NB! pgwatch2 config can also be stored YAML and Grafana can use embedded Sqlite DB so technically only DB that is absolutely needed is the metrics storage DB, here Influx. All examples assuming Ubuntu.
-
Install Postgres and create DB-s/roles for pgwatch2/Grafana
sudo apt install postgresqlDefault port: 5432
1.1. Create an User and a DB to hold Grafana config
psql -c "create user pgwatch2_grafana password 'xyz'" psql -c "create database pgwatch2_grafana owner pgwatch2_grafana"1.2. Create an User and a DB to hold pgwatch2 config
psql -c "create user pgwatch2 password 'xyz'" psql -c "create database pgwatch2 owner pgwatch2"1.3 Roll out the pgwatch2 schema (will holds connection strings of DB-s to be monitored + metric definitions)
psql -f pgwatch2/sql/config_store/config_store.sql pgwatch2 psql -f pgwatch2/sql/config_store/metric_definitions.sql pgwatch2 -
Install InfluxDB (for Postgres as metrics storage DB see instructions here)
INFLUX_LATEST=$(curl -so- https://api.github.com/repos/influxdata/influxdb/tags | grep -Eo '"v[0-9\.]+"' | grep -Eo '[0-9\.]+' | sort -nr | head -1) wget https://dl.influxdata.com/influxdb/releases/influxdb_${INFLUX_LATEST}_amd64.deb sudo dpkg -i influxdb_${INFLUX_LATEST}_amd64.debTake a look/edit the Influx config at /etc/influxdb/influxdb.conf and it's recommend to create also a separate limited login user e.g. "pgwatch2" to be used by the metrics gathering daemon to store metrics. See here on configuring InfluxDB and here for creating new users.
Default port for the API: 8086
-
Install Grafana
GRAFANA_LATEST=$(curl -so- https://api.github.com/repos/grafana/grafana/tags | grep -Eo '"v[0-9\.]+"' | grep -Eo '[0-9\.]+' | sort -nr | head -1) wget https://s3-us-west-2.amazonaws.com/grafana-releases/release/grafana_${GRAFANA_LATEST}_amd64.deb sudo dpkg -i grafana_${GRAFANA_LATEST}_amd64.debDefault port: 3000
2.1. Configure Grafana config to use our pgwatch2_grafana DB
Place something like below in the "[database]" section of /etc/grafana/grafana.ini
[database] type = postgres host = my-postgres-db:5432 name = pgwatch2_grafana user = pgwatch2_grafana password = xyzTaking a look at [server], [security] and [auth*] sections is also recommended.
2.2. Set up the Influx datasource as default
Use the Grafana UI (Admin -> Data sources) or adjust and execute the "pgwatch2/bootstrap/grafana_datasource.sql"
2.3. Add pgwatch2 predefined dashboards to Grafana
This could be done by importing the JSON-s from the "grafana_dashboards" folder manually (Import Dashboard from the Grafana top menu) or via the Docker bootstrap script (pgwatch2/bootstrap/set_up_grafana_dashboards.sh). Script needs some adjustment for connect data and file paths though and also the "grafana_datasource.sql" part should be commented out if already executed in the previous step.
-
Install Python 3 and start the Web UI
NB! The Web UI is not strictly required but makes life a lot easier. Technically it would be fine also to manage connection strings of the monitored DB-s directly in the "pgwatch2.monitored_db" table and add/adjust metrics in the "pgwatch2.metric" table, and "preset configs" in the "pgwatch2.preset_config" table.
# first we need Python 3 and "pip" - the Python package manager sudo apt install python3 python3-pip sudo pip3 install -U -r webpy/requirements.txt4.0. Optional step: for use cases where exposing component (Grafana, Postgres, Influx, gatherer daemon, Web UI itself) logs via the Web UI could be benficial, one should also change the log file paths hardcoded in the SERVICES variable of the pgwatch2.py source file. Defaults are set to work with the Docker image.
4.1. Start the Web UI
cd webpy python3 web.pyDefault port for the Web UI: 8080
4.2. Configure DB-s to monitor from "/dbs" page
NB! To get most out of your metrics some wrappers/extensions are required on the DB-s under monitoring. See section Steps to configure your database for monitoring on setup information.
-
Install Go and compile the gatherer
NB! There are pre-built binaries DEB / RPM / Tar packages also avaialble on the "releases" tab so this step is not really mandatory if maximum control or code changes are not required.
Check for the latest Go version from https://golang.org/dl/
# install Go (latest version preferably, but at least 1.10) wget https://dl.google.com/go/go1.11.linux-amd64.tar.gz tar -C /usr/local -xzf go1.11.linux-amd64.tar.gz export PATH=$PATH:/usr/local/go/bin # compile the gatherer daemon cd pgwatch2 ./build_gatherer.sh # an executable named "pgwatch2" should be generated ...5.1. Run the gatherer
./pgwatch2 --host=my-postgres-db --user=pgwatch2 --password=xyz \ --ihost=my-influx-db --iuser=pgwatch2 --ipassword=xyz # for all starting options run "./pgwatch2 --help"Congrats! Now the metrics should start flowing in and after some minutes one should already see some graphs in Grafana.
-
Install and configure SystemD init scripts for the Gatherer and the Web UI here and here or make sure to hatch up some "init scripts" so that the pgwatch2 daemon and the Web UI would be started automatically when the system reboots. For externally packaged components (Grafana, Influx, Postgres) it should be the case already.
For a custom installation there's quite some freedom in doing updates - fully independent components (Grafana, InfluxDB, PostgreSQL) can be updated any time without worrying too much about the other components. Only "tightly coupled" components are the pgwatch2 metrics collector, config DB and the optional Web UI - if the pgwatch2 config is kept in the database. If YAML approach (see the "File based operation" paragraph above) is used then things are more simple - the collector can be updated any time as YAML schema has default values for everything and also there's no Web UI (and Config DB = YAML files) and there order of component updates doesn't matter.
Check / download the latest version from the official website or use the Github API:
VER=$(curl -so- https://api.github.com/repos/grafana/grafana/tags | grep -Eo '"v[0-9\.]+"' | grep -Eo '[0-9\.]+' | sort -nr | head -1)
wget -q -O grafana.deb https://dl.grafana.com/oss/release/grafana_${VER}_amd64.deb
dpkg -i grafana.deb
NB! There are no update scripts for the "preset" Grafana dashboards as it would break possible user applied changes. If you know that there are no user changes then one can just delete or rename the existing ones and import the latest JSON definitions from here. Also note that the dashboards don't change too frequently so it only makes sense to update if you haven't updated them for half a year or more, or if you pick up see some change decriptions from the CHANGELOG.
Database updates can be quite complex, with many steps, so it makes sense to follow the manufacturer's instructions here.
For InfluxDB typically something like that is enough though (assuming Debian based distros):
influx -version # check current version
VER=$(curl -so- https://api.github.com/repos/influxdata/influxdb/tags | grep -Eo '"v[0-9\.]+"' | grep -Eo '[0-9\.]+' | sort -nr | head -1)
wget -q -O influxdb.deb https://dl.influxdata.com/influxdb/releases/influxdb_${VER}_amd64.deb
dpkg -i influxdb.deb
For PostgreSQL one should distinguish between minor version updates and major version upgrades. Minor updates are quite straightforward and problem-free, consisting of running something like (assuming Debian based distros):
apt update && apt install postgresql
sudo systemctl restart postgresql
For PostgreSQL major version upgrades one should read the according relase notes (e.g. here) and be prepared for the unavoidable downtime.
This is the pgwatch2 specific part, with some coupling between the following components - SQL schema, metrics collector, and the optional Web UI.
Here one should check from the CHANGELOG if pgwatch2 schema needs updating. If yes, then manual applying of schema diffs is required before running the new gatherer or Web UI. If no, i.e. no schema changes, all components can be updated independently in random order.
-
Given that we initially installed pgwatch v1.6.0, and now the latest version is 1.6.2, based on the release notes and SQL diffs we need to apply the following files:
psql -U pgwatch2 -f pgwatch2/sql/config_store/migrations/v1.6.1-1_patroni_cont_discovery.sql pgwatch2 psql -U pgwatch2 -f v1.6.2_superuser_metrics.sql pgwatch2NB! When installing from packages the "diffs" are at: /etc/pgwatch2/sql/config_store/migrations/
-
Compile or install the gatherer from RPM / DEB / tarball packages. See the above "Installing without Docker" paragraph for building details.
-
Update the optional Python Web UI if using it to administer monitored DB-s and metric configs. The Web UI is not in the pre-built packages as deploying self-contained Python that runs on all platforms is not overly easy. If Web UI is started directly on the Github sources (
git clone && cd webpy && ./web.py) then it is actually updated automatically as CherryPy web server monitors the file changes. If there were some breaking schema changes though, it might stop working and needs a restart after applying schema "diffs". -
If using SystemD service files to auto-start the collector or the Web UI, you might want to also check for possible updates there - "webpy/startup-scripts/pgwatch2-webui.service" for the Web UI or "pgwatch2/startup-scripts/pgwatch2.service" (/etc/pgwatch2/startup-scripts/pgwatch2.service for pre-built packages).
-
Checking / updating metric definitions.
In the YAML mode you always get it automatically when refreshing the sources via Github or pre-built packages, but with Config DB approach one needs to do it manually. Given that there are no user added metrics, is simple enough though - just delete all old ones and re-insert everything from the latest metric definition SQL file.
pg_dump -t pgwatch2.metrics pgwatch2 > old_metrics.sql # a just-in-case backup psql -U pgwatch2 -c "truncate pgwatch2.metrics" pgwatch2 psql -U pgwatch2 -f pgwatch2/sql/config_store/metric_definitions.sql pgwatch2 # or when using pre-built packages # psql -U pgwatch2 -f /etc/pgwatch2/sql/config_store/metric_definitions.sql pgwatch2