Still need to figure out CTCLoss nan problem
A pytorch implementation of speech recognition based on DeepMind's Paper: WaveNet: A Generative Model for Raw Audio.
The purpose of this implementation is Well-structured, reusable and easily understandable.
A tensorflow implementation here: buriburisuri/speech-to-text-wavenet
Although WaveNet was designed as a Text-to-Speech model, the paper mentions that they also tested it in the speech recognition task. They didn't give specific details about the implementation, only showed that they achieved 18.8 PER on the test dataset from a model trained directly on raw audio on TIMIT.
I modify the WaveNet model from https://github.com/golbin/WaveNet and apply the PyTorch bindings for Warp-ctc for the speech recognition experiment.
The final architecture is shown in the following figure.
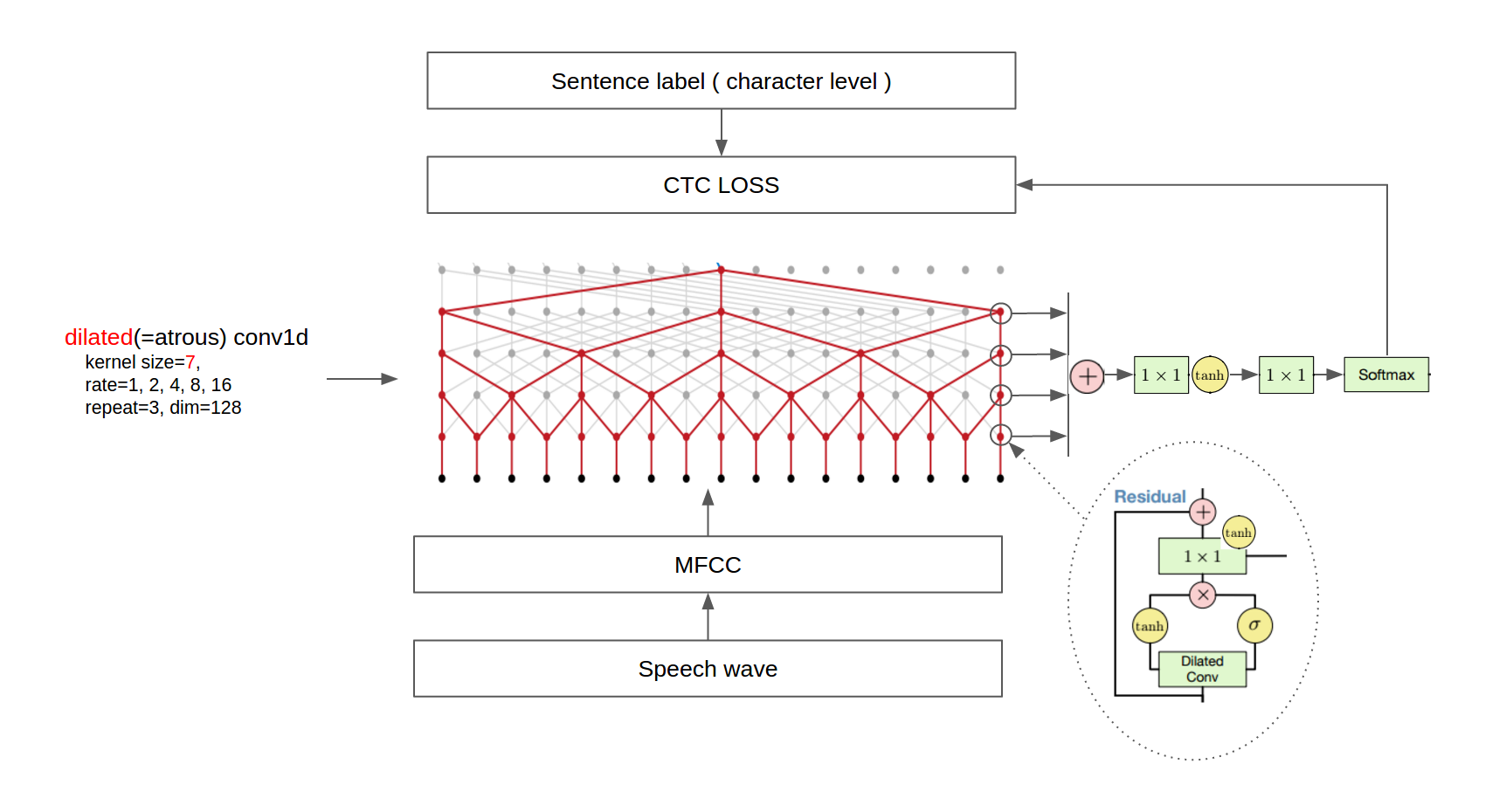
(Image source: buriburisuri/speech-to-text-wavenet)
-
System
- Linux
- CPU or (NVIDIA GPU + CUDA CuDNN)
- Python 3.6
-
Libraries
- PyTorch = 0.4.0
- librosa = 0.5.0
- https://github.com/SeanNaren/warp-ctc
- pandas >= 0.19.2
- scikits.audiolab==0.11.0
We used VCTK, LibriSpeech and TEDLIUM release 2 corpus. Total number of sentences in the training set composed of the above three corpus is 240,612. Valid and test set is built using only LibriSpeech and TEDLIUM corpuse, because VCTK corpus does not have valid and test set. After downloading the each corpus, extract them in the 'asset/data/VCTK-Corpus', 'asset/data/LibriSpeech' and 'asset/data/TEDLIUM_release2' directories.
The TEDLIUM release 2 dataset provides audio data in the SPH format, so we should convert them to some format librosa library can handle. Run the following command in the 'asset/data' directory convert SPH to wave format.
find -type f -name '*.sph' | awk '{printf "sox -t sph %s -b 16 -t wav %s\n", $0, $0".wav" }' | bash
If you don't have installed sox, please installed it first.
sudo apt-get install sox
We found the main bottle neck is disk read time when training, so we decide to pre-process the whole audio data into
the MFCC feature files which is much smaller. And we highly recommend using SSD instead of hard drive.
Run the following command in the console to pre-process whole dataset.
python preprocess.py
python train.py