本项目是关于Yi的多模态系列模型,如Yi-VL-6B/34B等的实验与应用。

以命令行(CLI)的模型进行模型推理,需要将图片下载至images文件夹,同时将single_inference.py略作调整,以支持多次提问。
运行命令如下:
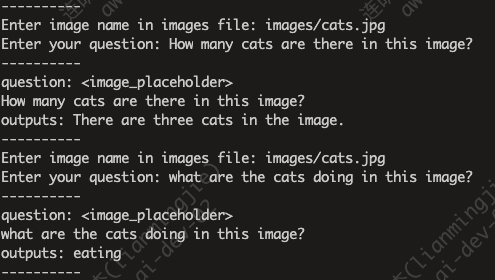
CUDA_VISIBLE_DEVICES=0 python single_inference.py --model-path /data-ai/usr/models/Yi-VL-34B --image-file images/cats.jpg --question "How many cats are there in this image?"模型推理时使用一张A100(显存80G)就可满足推理要求。
示例图片如下:

回复结果如下:
基于此,我们将会用gradio模块,对Yi-VL-34B模型和GPT-4V模型的结果进行对比。
Python代码参考gradio_server.py.
以下是对不同模型和问题的回复:
- 图片:taishan.jpg,问题:这张图片是**的哪座山?

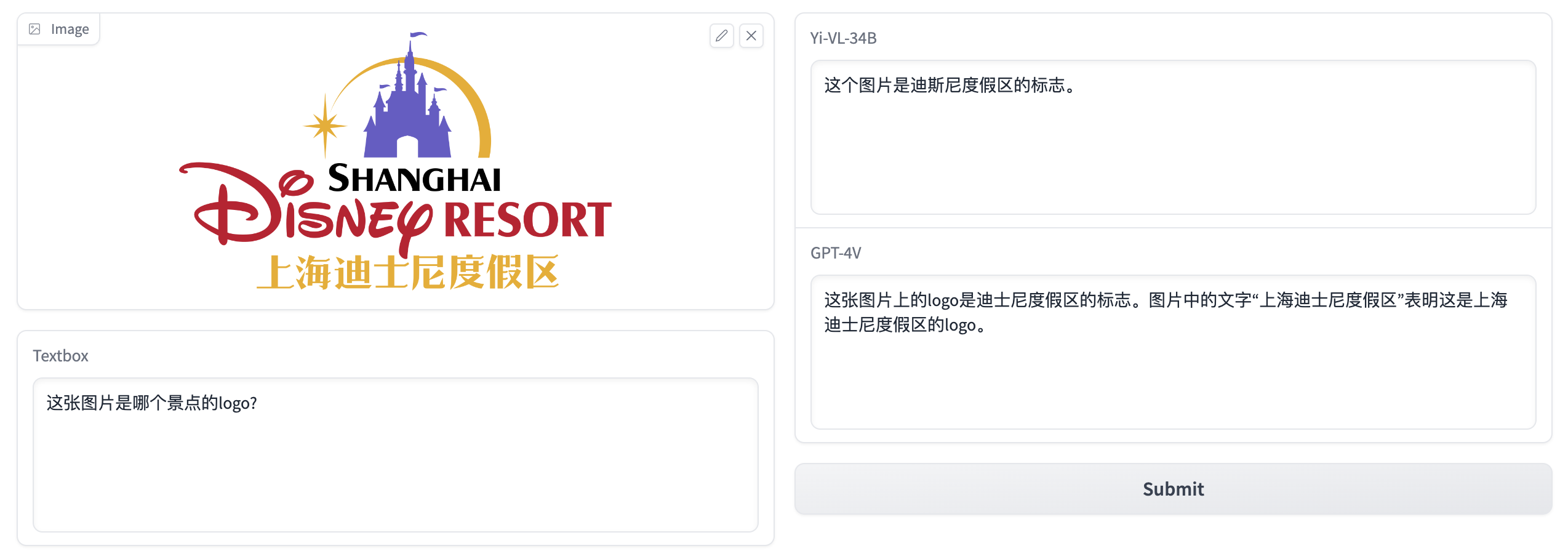
- 图片:dishini.jpg,问题:这张图片是哪个景点的logo?
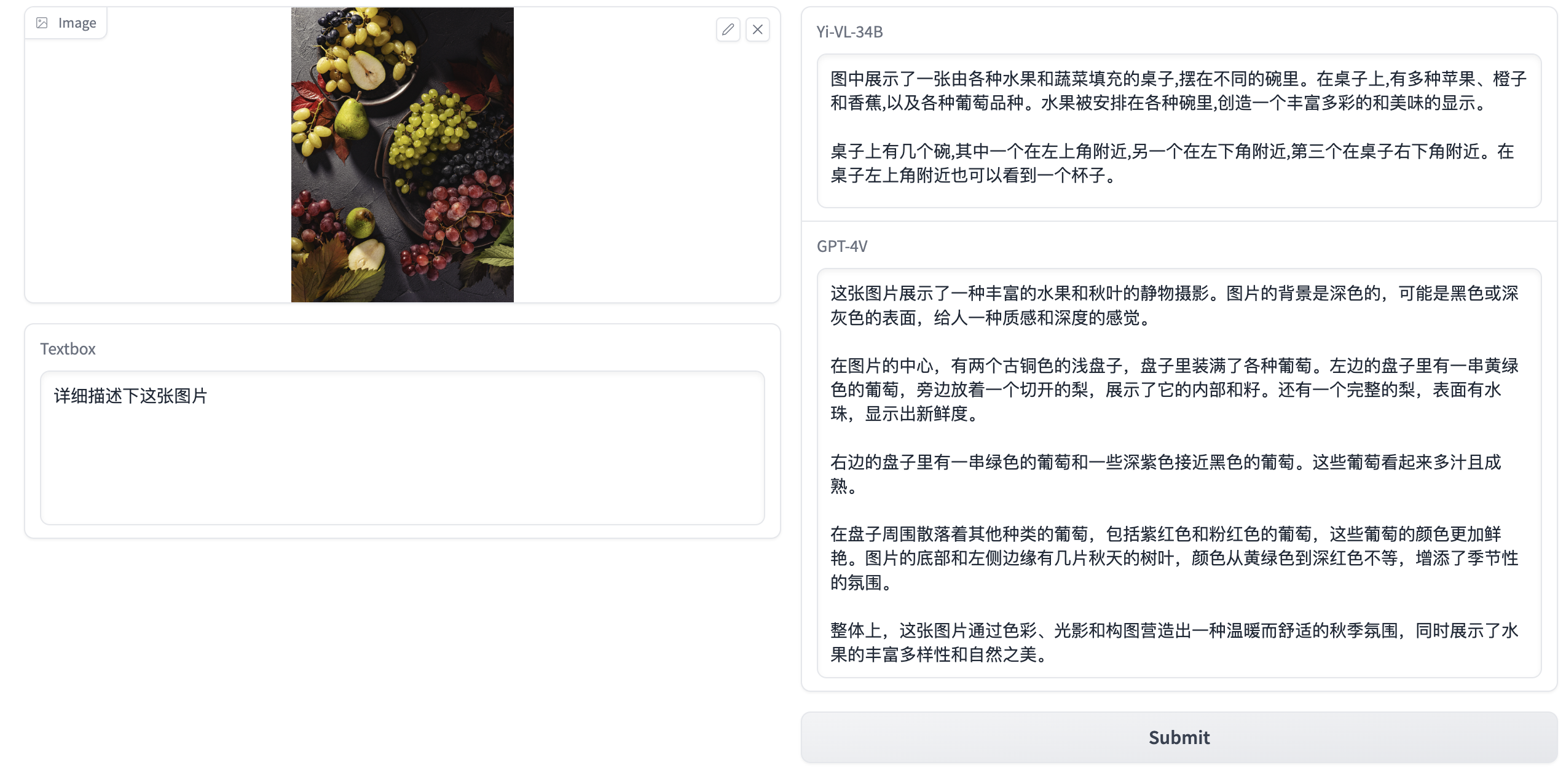
- 图片:fruit.jpg,问题:详细描述下这张图片
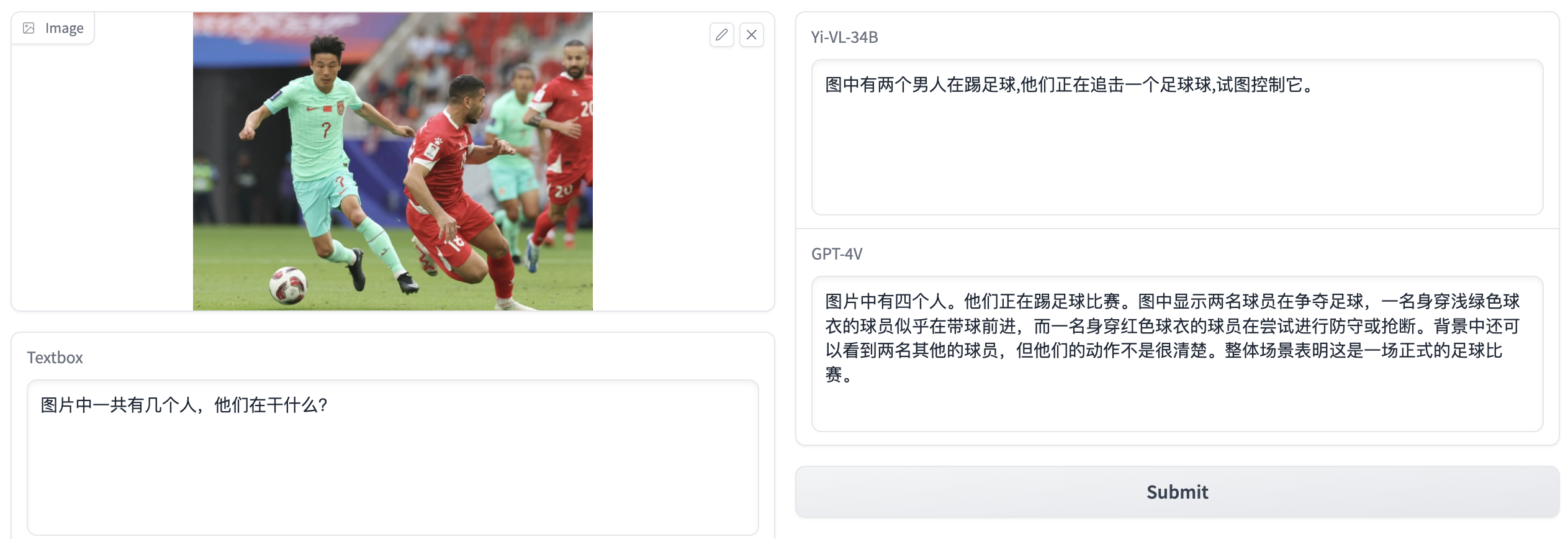
- 图片:football.jpg,问题:图片中一个有几个人,他们在干什么?
- 图片:cartoon.jpg,问题:这张图片是哪部日本的动漫?
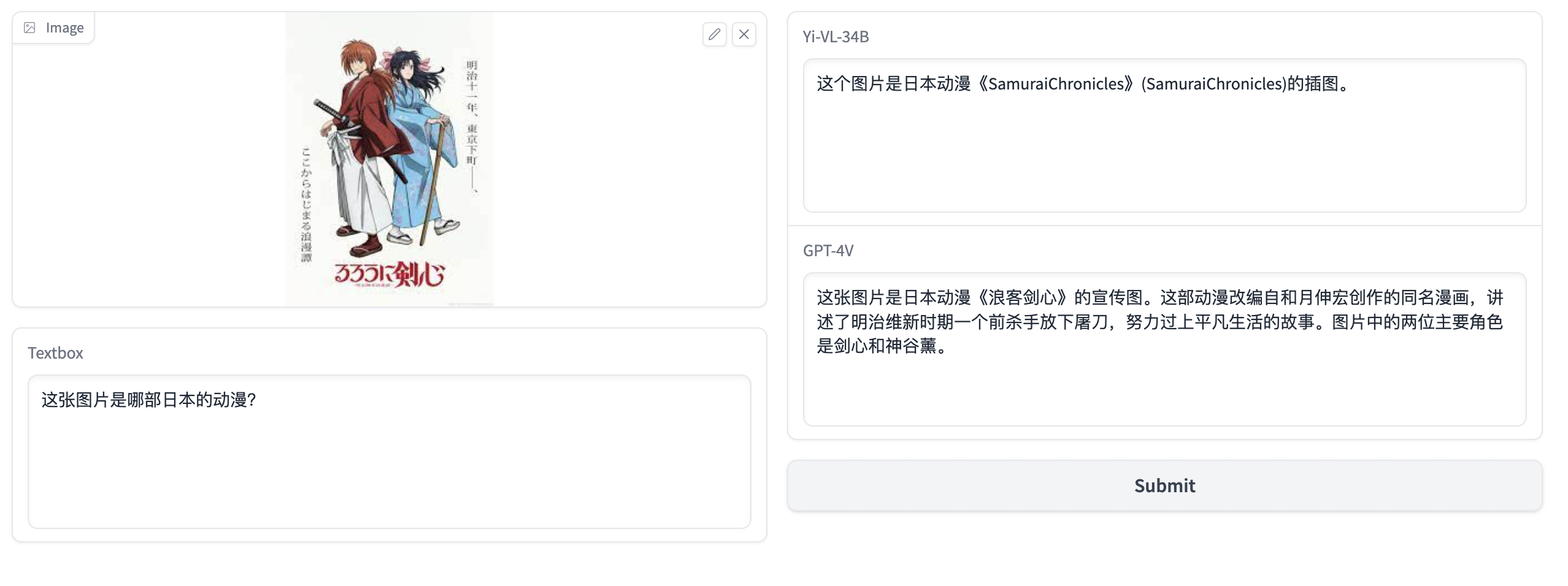
从以上的几个测试用例来看,Yi-VL-34B模型的效果很不错,但对比GPT-4V模型,不管在图片理解,还是模型的回答上,仍有一定的差距。
最后,我们来看一个验证码的例子(因为GPT-4V是不能用来破解验证码的!)

可以看到,Yi-VL-34B模型在尝试回答,但给出了错误答案,而GPT-4V模型则会报错,报错信息如下:
{
"error": {
"message": "Your input image may contain content that is not allowed by our safety system.",
"type": "invalid_request_error",
"param": null,
"code": "content_policy_violation"
}
}无疑,GPT-4V模型这样的设计是合情合理的。