Author: Rob Petrovec petrock@colostate.edu
Colorado State University
CS533 - Database Management Systems
Fall '22 Term Project
This project is for a CUDA GPU aware script that implements a Binary Classifier Model Factory. It is designed to help find the best set of hyperparameters for an MLP model. It was scoped as a phishing vs legitimate website classifier, but could be adapted for any binary classification task. It will run a grid style hyperparameter search against one or more datasets and use Stratified K-Fold Cross Validation to compare the performance of each model. The script will generate accuracy, loss & data mining graphs, along the results of each model configuration. As the script progresses it will write the results to a file sorted in descending order by accuracy. This allows the user to monitor the progress of the script and quickly see which model configurations are performing the best in real time.
The script was tested with Python 3.9, Pytorch 1.11.0, and cudatoolkit 11.5.1 using anaconda 22.9.0 on macOS Ventura 13.0 & AlmaLinux 8.6. It may work with other operating systems and package versions, but has not been tested. An environment.yml file has been supplied for quick & easy bring up of the project.
% git clone https://github.com/petrock99/phishingMLPFactory.git
% cd phishingMLPFactory
% conda activate
% conda env create -f environment.yml -p ./envs
% conda activate ./envs
% python main.py
% python main.py -h
usage: main.py [-h] [--csv_names CSV_NAME [CSV_NAME ...]]
[--hidden_layers N_NODES [N_NODES ...]]
[--learning_rates LEARNING_RATE [LEARNING_RATE ...]] [--force_cpu]
[--batch_size BATCH_SIZE] [--epochs N_EPOCHS] [--validation_split SPLIT]
[--accuracy_threshold THRESHOLD] [--early_stop_patience PATIENCE]
[--common_value_threshold THRESHOLD] [--k_folds FOLDS]
optional arguments:
-h, --help show this help message and exit
--csv_names CSV_NAME [CSV_NAME ...]
One or more .csv or .csv.zip names inside the './datasets'
directory. Default: 'DS4Tan.csv'
--hidden_layers N_NODES [N_NODES ...]
Space separated list of the numbers representing the nodes in each
hidden layer. Useful for testing a specific layer configuration.
Default: A matrix of 42 hidden layer configurations.
--learning_rates LEARNING_RATE [LEARNING_RATE ...]
Space separated list of learning rates to train with. Values
between 0 & 1. Default: '0.01, 0.001, 0.0001'
--force_cpu Force running on the CPU instead of GPU. Default: Run on GPU if
available, otherwise CPU.
--batch_size BATCH_SIZE
Batch size used during processing. Zero will load the entire
dataset in one batch. Default: 0
--epochs N_EPOCHS Max number of epochs for training. A lower value is recommended if
'--validation_split' is zero. Default: 5000
--validation_split SPLIT
The percentage of the dataset set aside for validation and Early
Stopping during training. Remainder of the dataset will be used for
training. Value between 0 & 1. Default: 0.2
--accuracy_threshold THRESHOLD
Minimum accuracy percentage needed to print results to the console.
Value between 0 & 1. Default: 0.965
--early_stop_patience PATIENCE
Number of epochs to wait for change before training is stopped.
Ignored if '--validation_split' is zero. Default: 150
--common_value_threshold THRESHOLD
Minimum percentage of feature samples with the same value to allow.
Value between 0 & 1. Default: 0.95
--k_folds FOLDS Number of folds to use for K-Fold Validation. Default: 5
% python main.py
Run the script with its default values.
% python main.py --learning_rates 0.001 --hidden_layers 10 20 30 --validation_split 0.1
Run the script with a learning rate of 0.001, 3 hidden layers with 10, 20 & 30 nodes respectively, and a training/validation split of 90/10.
% python main.py --epochs 100 --validation_split 0 --csv_names data1.csv data2.csv
Run the default set of hyperparameters against './datasets/data1.csv' & './datasets/data2.csv' datasets for 100 epochs per training cycle. Validation and early stopping are disabled during training as well.
The script will use the list of .csv file names supplied by the --csv_names argument to find datasets within the ./datasets directory. If a .csv.zip file is present with no corresponding .csv file, the script will decompress the .csv.zip and use the resulting .csv as a dataset.
The .csv files must contain a Label feature that indicates the expected classification of each sample. The values of the Label feature must be either -1 & 1, or 0 & 1 for Legitimate & Phishing samples respectively. The values of all other features must be either floating point or integer values.
At run time, the script will preprocess the dataset to filter out irrelevant data. It will remove samples containing NaN values as well as duplicate samples. It will also remove features with a high percentage of samples with the same value (configurable via --common_value_threshold). It will then balance the dataset so that there is a 50/50 split of Legitimate & Phishing samples. This is to ensure the classifier isn't biased by the dataset one way or the other. A "dataset_filtered.csv" file is generated containing the filtered dataset used by the script.
The script uses an 80/20 training/validation split of the dataset, by default. It is configurable via --validation_split. The validation set is used for Early Stopping during training and to graph how the training is progressing.
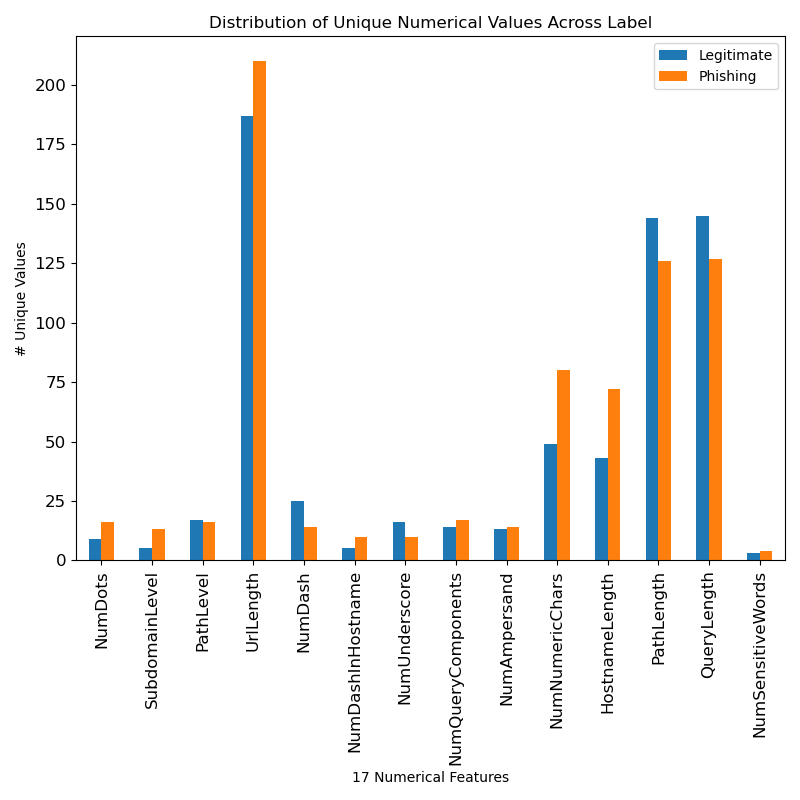
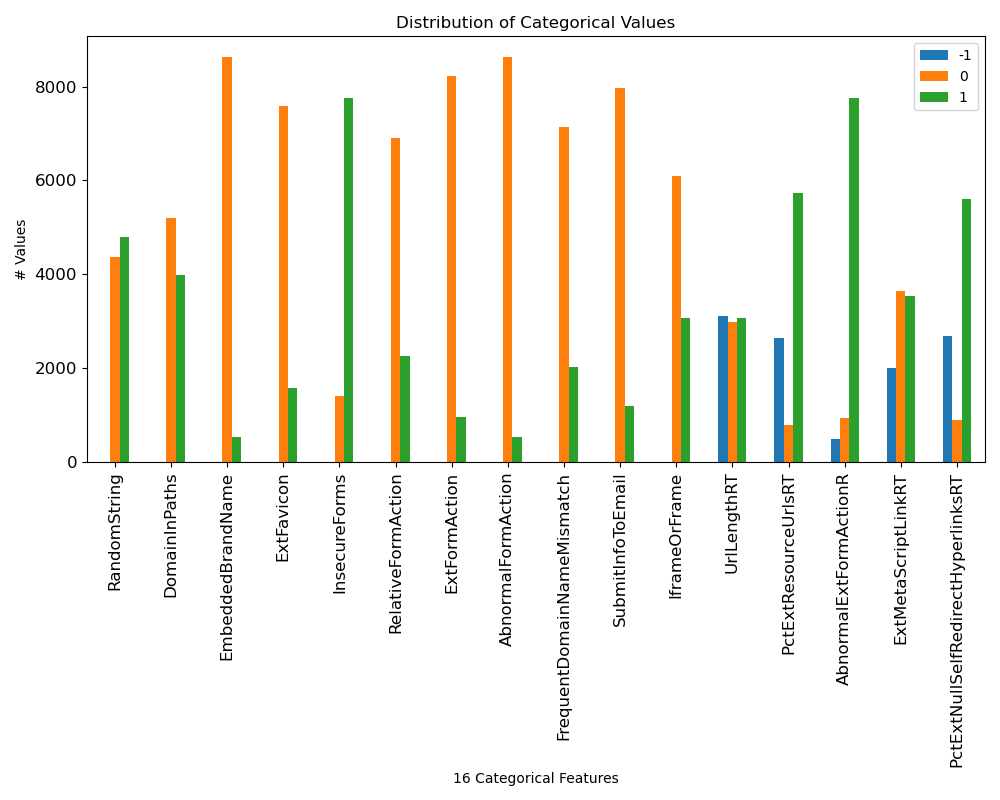
Data mining graphs are generated to help quantify the data and guide dataset & model decisions:
- Correlation graphs of all the features and just the numeric features
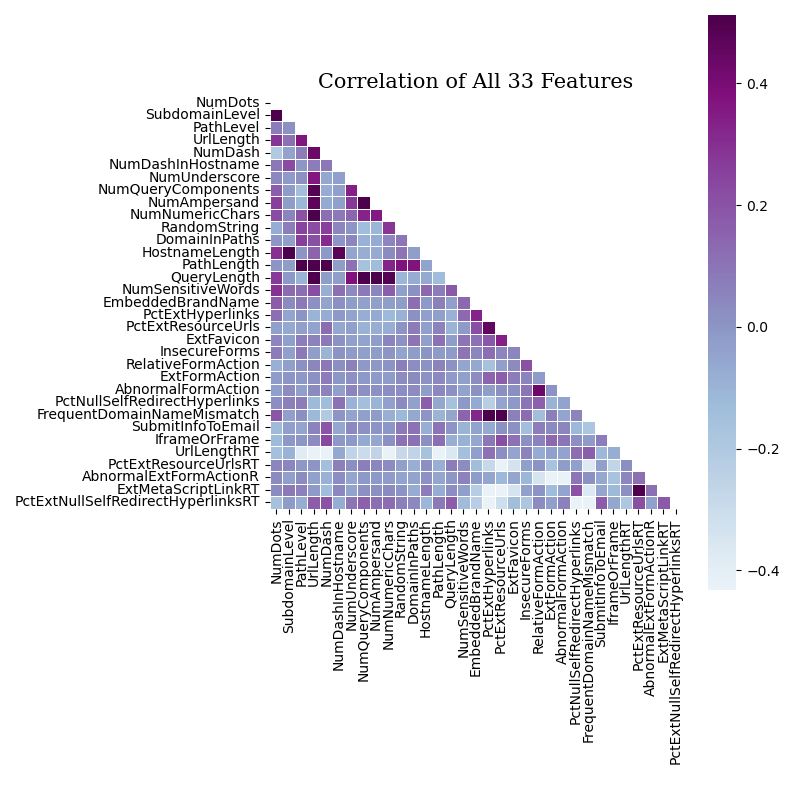
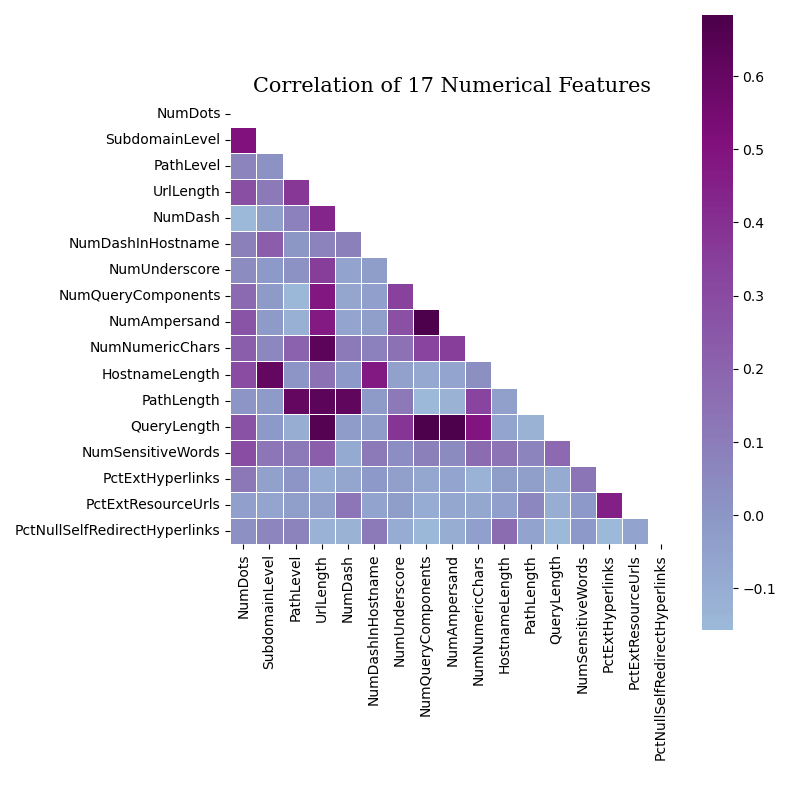
- Distribution graphs of unique numerical features and categorical features
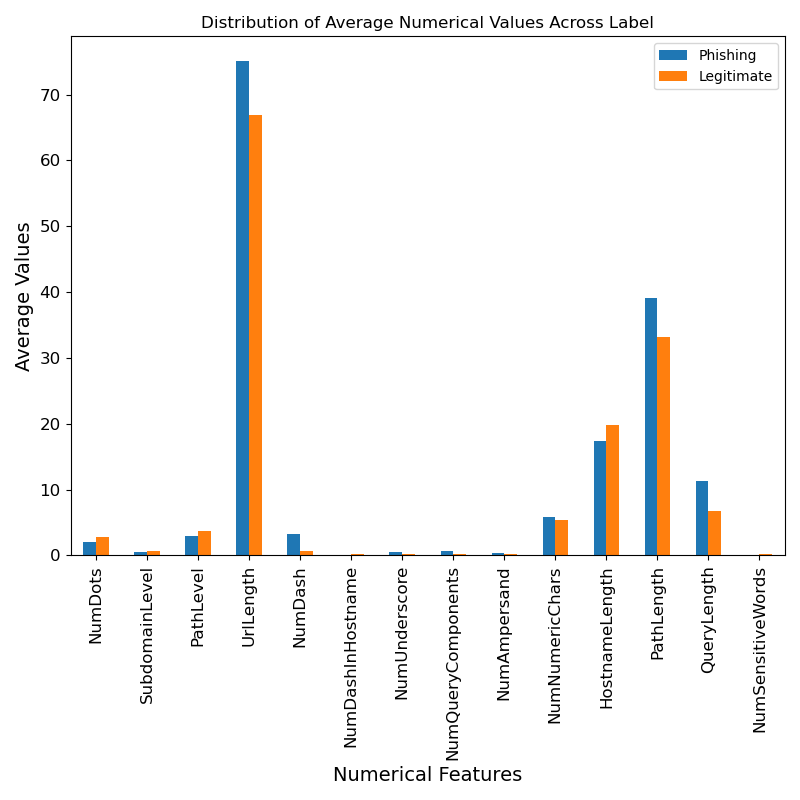
- Average distribution graph of numerical features
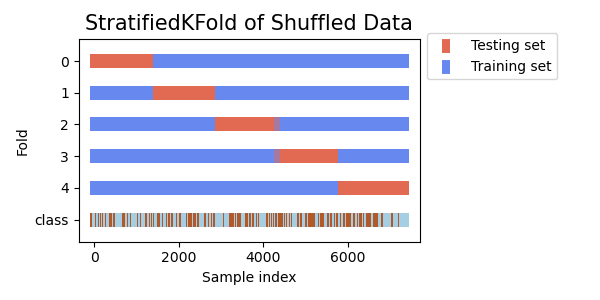
- Stratified K-Fold Distribution of the Training set






The script will do a Grid Style Hyperparameter search with each specified dataset (via --csv_names). Each will generate a results file and graph image files for each dataset. The hyperparameters used are the number of hidden layers, the number of nodes within each hidden layer and the learning rate.
A 80/20 training/validation split of the dataset is used by default, configurable via --validation_split. Stratified K-Fold Cross Validation is employed on the training set to compare the resulting models. The number of folds is configurable via --k_folds and defaults to five. During each training epoch, the model processes the validation set to gauge how well the model is training. Training is stopped early if the validation loss does not decrease after 150 epochs. This is configurable via --early_stop_patience. The script keeps track of the model state corresponding to the lowest validation loss value. It will use that 'best model' state during testing. This allows the model to find its ideal state and number of epochs without excessive over-processing and with minimal overfitting.
For each fold the script will process the training, validation & test sets in batches (configurable via --batch_size). Each batch accuracy and loss is averaged to produce the per fold accuracy and loss. The per fold accuracy and loss is averaged to find the overall accuracy and loss of the model. By default the script processes the entire dataset in one big batch. This greatly improved the speed of the script. The supplied datasets are relatively small and easily fit within GPU and CPU memory. Some investigation may be needed to speed up batching if larger datasets are used.
The script will take advantage of GPUs that support CUDA. If the script is run on non-CUDA hardware it will use the CPU. --force_cpu can be used to force the use of the CPU. In my experiments the GPU did not show significant speed improvement over CPU. That is likely a bug in the code that will need to be tracked down.
The script will create timestamped directories in the ./results directory to write the results of each dataset & model configuration into. The timestamp corresponds to the start time of processing each dataset. The directory name is in the format "dataset year-month-day at hour.minute.second", for example "DS4Tan 22-10-21 at 20.52.08". Using a timestamp in the folder name helps create a semi-unique folder name to avoid name collisions and to help differentiate & compare the results from multiple datasets and runs.
If a model configuration performance meets or excedes an accuracy threshold the results of the model performance will be printed. The results include the accuracy of each fold and percentages for the overall accuracy, area under the ROC curve, Precision, Recall, F1, False Positive & False Negative as well as the Confusion Matrix. If the overall accuracy is below the threshold a short message expressing the models low performance is printed. This threshold is configurable via --accuracy_threshold.
An image file for each model configuration containing the accuracy & loss graphs of each fold will be generated in the timestamped results directory. An example graph is shown below. The file name format is "[hidden layer list]-learning rate-results.png". For example, "[50, 50]-0.001-results.png" represents a model configuration with two hidden layers with 50 nodes each and a learning rate of 0.001. Training AUC & Validation AUC represent the training and validation area under the ROC curve. Max Val Accuracy and Min Val Loss, represented by the green dots in the graphs, indicates the maximum accuracy & minimum loss achieved during validation. Min Val Loss also indicates the epoch at which the model state was saved for use during testing.

At the start of every run, a metrics file is created in the timestamped results directory with the format "dataset-metrics.txt". For example, "DS4Tan-metrics.txt". This file contains information about the dataset and model configuration. In addition it contains a list of results from each model that was processed. This includes the model configuration, data points about each fold, overall accuracy and other metrics to help analyze the performance of the model. This results list is sorted by accuracy in descending order and is continually updated throughout training. This allows the user to monitor the performance of each configuration live and get a good sense of how well the models are performing. One common method to view changes to a file live is by using the watch -head command. It will keep the beginning of the file pinned to the top of the terminal window so the model configuration with the highest accuracy at that moment is always visible. The script will print out the proper command, and path to the metrics file, at the beginning of each run, for easy copying and pasting into a separate terminal window.
-- Dataset 'DS4Tan.csv' --
Split: 80.0 / 20.0
All: (9168, 34)
Training: (7334, 33) / (7334, 1)
Validate: (1834, 33) / (1834, 1)
-- Stats --
Batch Size: Full Dataset
Early Stop Patience: 150
Common Column Value Threshold: 0.95
Number of Folds: 5
-- Metrics in Accuracy Descending Order --
****************************************
hidden layers: [50, 50], learning rate: 0.001
fold: 0 -- Accuracy: 0.9775, AUC: 0.9953, Min Val Loss: 0.0786, Min Val Loss Epoch: 327, Elapsed Time: 0:00:29.045767
fold: 1 -- Accuracy: 0.9748, AUC: 0.9940, Min Val Loss: 0.0781, Min Val Loss Epoch: 340, Elapsed Time: 0:00:29.800506
fold: 2 -- Accuracy: 0.9652, AUC: 0.9911, Min Val Loss: 0.0860, Min Val Loss Epoch: 255, Elapsed Time: 0:00:24.785619
fold: 3 -- Accuracy: 0.9748, AUC: 0.9967, Min Val Loss: 0.0820, Min Val Loss Epoch: 314, Elapsed Time: 0:00:28.130508
fold: 4 -- Accuracy: 0.9789, AUC: 0.9955, Min Val Loss: 0.0803, Min Val Loss Epoch: 302, Elapsed Time: 0:00:27.507045
Accuracy %: 97.4230
Area Under Curve %: 99.4518
Precision %: 97.4144
Recall %: 97.4367
F1 %: 97.4239
False Pos %: 2.5907
False Neg %: 2.5634
Elapsed Time: 0:02:21.058911
Confusion Matrix:
[[714. 19.]
[ 19. 715.]]
****************************************
hidden layers: [5, 10], learning rate: 0.01
fold: 0 -- Accuracy: 0.9721, AUC: 0.9931, Min Val Loss: 0.0795, Min Val Loss Epoch: 268, Elapsed Time: 0:00:24.364997
fold: 1 -- Accuracy: 0.9734, AUC: 0.9954, Min Val Loss: 0.0861, Min Val Loss Epoch: 458, Elapsed Time: 0:00:35.555528
fold: 2 -- Accuracy: 0.9680, AUC: 0.9943, Min Val Loss: 0.0860, Min Val Loss Epoch: 201, Elapsed Time: 0:00:20.658526
fold: 3 -- Accuracy: 0.9734, AUC: 0.9951, Min Val Loss: 0.0886, Min Val Loss Epoch: 205, Elapsed Time: 0:00:20.863612
fold: 4 -- Accuracy: 0.9714, AUC: 0.9942, Min Val Loss: 0.0897, Min Val Loss Epoch: 132, Elapsed Time: 0:00:16.481482
Accuracy %: 97.1639
Area Under Curve %: 99.4431
Precision %: 97.0381
Recall %: 97.3001
F1 %: 97.1677
False Pos %: 2.9725
False Neg %: 2.6998
Elapsed Time: 0:01:59.809393
Confusion Matrix:
[[712. 22.]
[ 20. 714.]]
...
------------------------------------------
Elapsed Time: 0:03:24.754395
Eight sample datasets are included with this project.
-
DS4Tran.csv
- The base dataset that all the other datasets are generated from. It contains 10k samples with a 50/50 split of legitimate/phishing website data samples.
-
DS4Tan_nopct.csv
- Same as DSTran.csv but with the PctXXX features removed.
-
DS4Tan_1.csv
- Based on DSTran.csv with odd features removed, starting at 'TildeSymbol', and some feature values offset to avoid zeros.
Common features between DS4Tan_1.csv and DS4Tan_2.csv are 'NumDots','SubdomainLevel','PathLevel','UrlLength','NumDash','NumDashInHostname'.
Removed features include 'TildeSymbol', 'NumPercent', 'NumAmpersand', 'NumNumericChars', 'RandomString', 'DomainInSubdomains', 'HttpsInHostname', 'PathLength', 'DoubleSlashInPath', 'EmbeddedBrandName', 'PctExtResourceUrls', 'InsecureForms', 'ExtFormAction', 'PctNullSelfRedirectHyperlinks', 'FakeLinkInStatusBar', 'PopUpWindow', 'IframeOrFrame', 'ImagesOnlyInForm', 'UrlLengthRT', 'AbnormalExtFormActionR' and 'PctExtNullSelfRedirectHyperlinksRT'.
- Based on DSTran.csv with odd features removed, starting at 'TildeSymbol', and some feature values offset to avoid zeros.
-
DS4Tan_1_nopct.csv
- Based on DS4Tan_1.csv but with the PctXXX features removed.
-
DS4Tan_2.csv
- Based on DSTran.csv with even features removed, starting at 'TildeSymbol', and some feature values offset to avoid zeros.
Common features between DS4Tan_1.csv and DS4Tan_2.csv are 'NumDots','SubdomainLevel','PathLevel','UrlLength','NumDash','NumDashInHostname'.
Removed features include 'NumUnderscore', 'NumQueryComponents', 'NumHash', 'NoHttps', 'IpAddress', 'DomainInPaths', 'HostnameLength', 'QueryLength', 'NumSensitiveWords', 'PctExtHyperlinks', 'ExtFavicon', 'RelativeFormAction', 'AbnormalFormAction', 'FrequentDomainNameMismatch', 'RightClickDisabled', 'SubmitInfoToEmail', 'MissingTitle', 'SubdomainLevelRT', 'PctExtResourceUrlsRT', 'ExtMetaScriptLinkRT'.
- Based on DSTran.csv with even features removed, starting at 'TildeSymbol', and some feature values offset to avoid zeros.
-
DS4Tan_2_nopct.csv
- Based on DS4Tan_2.csv but with the PctXXX features removed.
-
DS4_merged_generated.csv
- A generated dataset based on DS4Tan_1.csv and DS4Tan_2.csv. It is unclear, at this time, how the samples were generated. A major issue with this dataset is that all of the floating point values have been rounded to the nearest integer. This makes features, like the PctExtHyperlinks, into binary values of either 0 or 1. This severely limits the usefulness of the dataset because the PctXXX features are major distinguishing features. Efforts are underway to regenerate this dataset with the floating point values reinstated.
-
DS4_merged_generated_nopct.csv
- Based on DS4_merged_generated.csv but with the PctXXX features removed.
Various experiments were performed during development of this project using the included datasets. The script was initially developed on the DS4Tan.csv dataset with a simple train/test Hold-Out validation scheme. It achieved accuracies in the 92% to 95% range fairly quickly. Over several weeks of development, train/validate/test scheme was adopted along with an Early Stopping technique. This improved performance to between 94% and 98%. In addition, support for results directory uniquing, continually updating metrics log files, graph image generation, command line argument support and other features to help with data analysis were implemented. Finally Stratified K-Fold Cross Validation was adopted with a train/validate scheme. This achieved accuracies between 95% and 97%.
One of the goals of this project was to find and compare the highest performing models for each dataset. Due to an issue in how DS4_merged_generated.csv was created all of the values were changed from floating point to integer via rounding. This made all the PctXXX features contain only 1s or 0s, effectively crippling the dataset. In order to make a somewhat proper comparison of datasets and models the XXX_nopct.csv datasets were created with all of the PctXXX features removed. These modified datasets were also run through the script.
Each experiment ran the script with its default settings against all of the datasets. This includes learning rates of .01, 0.001, 0.0001 and 43 hidden layer configurations. Each hidden layer configuration indicates the number of layers and the number of nodes in each layer. This resulted in a total of 126 model configurations per dataset for a grand total of 1008. Below is the list of hidden layers the script uses.
[5, 5], [10, 10], [5, 10], [10, 5], [10, 25], [25, 10],
[50, 50], [100, 100], [50, 50, 50], [100, 100, 100],
[200, 200], [300, 300], [400, 400], [500, 500], [100, 150],
[150, 100], [100, 300], [300, 100], [200, 300], [300, 200],
[400, 500], [500, 400], [800, 600], [600, 800],
[100, 200, 50], [50, 200, 100], [100, 200, 300],
[300, 200, 100], [50, 100, 200], [200, 100, 50],
[100, 50, 100, 50], [50, 100, 50, 100], [300, 100, 300, 100],
[100, 300, 100, 300], [600, 100, 600, 100],
[100, 600, 100, 600], [103, 307], [307, 103],
[173, 421, 223], [223, 421, 173], [173, 421, 223, 829, 103],
[103, 829, 223, 421, 173]
A table of the best performing model against each dataset is below.

- Fix DS4_merged_generated.csv floating point to integer problem and rerun the experiments on it.
- Find out how DS4_merged_generated.csv is created.
- Figure out why running the script on a GPU isn't significantly faster than on the CPU.
- Set up multiprocessing support so more than one dataset, or model configuration, can be processed at one time.
- Set up multi-GPU support to take advantage of some of CSUs hardware.
- Add a --result_path command line argument to specify where the results will be written.
- Change the timestamped results folder to be just the date and time. The timestamped results directory then contains a folder per dataset. Each dataset folder would contain the results from that dataset.
- Add support to generate a results table file from the metrics file for each dataset.
- Add support for paths to --csv_names.
- Add support for multiple lists of hidden layers to --hidden_layers.
- Profile the script to see if any performance speed ups could be achieved.
The final set of experiments consisted of running the script with default values against all of the supplied datasets. It was distributed among a few CS department machines with CUDA GPUs. After many hours of processing some observations became clear:
- DS4Tran.csv performed the best overall with a 97.4% accuracy on a model configured with [50, 50] hidden layers and a learning rate of 0.001
- DS4Tran_nopct.csv_ did the second best with a 95.9% accuracy on a model configured with [50, 50] hidden layers and a learning rate of 0.0001
- Datasets with the PctXXX features removed produced about 2% lower accuracies than datasets with the PctXXX features.
- All the datasets, except for DS4_merged_generated.csv and DS4_merged_generated_nopct.csv contained a lot of duplicate samples and columns with 95% of the values the same. This reduced the dataset down considerably. Its unclear if it had an effect on the results, however.
- DS4_merged_generated.csv (94.61%) performed slightly worse than DS4Tan_2.csv (94.68%)
- DS4_merged_generated.csv (94.61%) performed worse than DS4Tan_1.csv (95.4%) & DS4Tan.csv (97.4%).
- DS4_merged_generated.csv (94.61%) performed about the same as DS4_merged_generated_nopct.csv (94.5%).
- It appears that the binary values of the PctXXX features in DS4_merged_generated.csv didn't have much of an effect. The model likely learned to ignore them.
- DS4_merged_generated_nopct.csv (94.5%) performed marginally better than DS4Tan_1_nopct.csv (93.96%) and DS4Tan_2_nopct.csv (93%) datasets.
- DS4_merged_generated_nopct.csv (94.5%) performed about 1.5% worse than DS4Tran_nopct.csv_ (95.9%).
- Models with a learning rate of 0.01 converged very quickly. Sometimes in less than 100 epochs.
- The accuracy and loss curves for models with a 0.01 learning rate were very erratic. This indicates the model will produce unreliable results. A high accuracy or low loss were almost by chance.
- To run all of the experiments, distributed across multiple machines in parallel, it took roughly 16 hours to complete with about 88 hours of total CPU time.
- Models with a learning rate of 0.001 converged at a moderate pace. Typically within 200 and 500 epochs.
- Models with a learning rate of 0.0001 converged very slowly. Often taking 3000 to 4000 epochs for the loss values to stop decreasing and the training to stop.
- The accuracy and loss curves for models with 0.001 and 0.0001 learning rates were smooth and followed similar trajectories.
- Adding Early Stopping support to the training phase took a lot of the guess work out of finding the number of epochs to produce the best results. In most cases Early Stopping was early in name only. The number of epochs to find the Minimum Validation Loss ranged from 100 to 5000.
- The loss curve after the Minimum Validation Loss point was noticeably trending upwards. This indicates that the model was starting to overfit after the Minimum Validation Loss point.
- By using the Minimum Validation Loss to determine the model state to use for testing it help reduce the possibility of overfitting.
- Minimum Validation Loss and Maximum Validation Accuracy were not at the same epoch. I'm curious why that was the case.
- Stratified K-Fold Cross Validation helped tremendously in comparing different models.
- The area under the ROC curve percentages did not help much in evaluating the models. They were all between 98% and 99.9%.