The project is implemented in Python using Tensorflow. It is a word-based Recurrent neural network (RNN) inspired by this Tensorflow tutorial. The model is trained in a corpus containing the song titles and the lyrics of many famous songs of Beatles. So, given a sequence of words from Beatles lyrics, it can predict the next words. We could say that it is a model generating Beatle-like lyrics.
As we said the corpus (beatles_lyrics.txt) contains the song titles and the lyrics of many Beatles songs in the following format:
Song title 1
-----------------
Lyric line 1
Lyric line 2
Lyric line 3
Lyric line 4
etc...
Song title 2
-----------------
Lyric line 1
Lyric line 2
Lyric line 3
Lyric line 4
etc...
etc...
I have manually created the corpus with the lyrics I found in this amazing site
As almost every machine learning model, training data need a bit of preprocessing before they are ready to be used as a training input for our RNN. We preprocess the initial corpus by doing the following tasks:
- Convert all letters to lowercase
- Remove blank lines
- Remove special characters (such as ',' , '(' , ')' , '[' , ']' etc)
The following function performs the preprocessing:
stopChars = [',','(',')','.','-','[',']','"']
# preprocessing the corpus by converting all letters to lowercase,
# replacing blank lines with blank string and removing special characters
def preprocessText(text):
text = text.replace('\n', ' ').replace('\t','')
processedText = text.lower()
for char in stopChars:
processedText = processedText.replace(char,'')
return processedTextAfter the text preprocessing step, we need to convert it to a list of words. This procedure is also known as "Tokenization".
The following function performs the tokenization:
def corpusToList(corpus):
corpusList = [w for w in corpus.split(' ')]
corpusList = [i for i in corpusList if i] #removing empty strings from list
return corpusListThen, we trim each word for leading or trailing spaces / tabs.
map(str.strip, corpus_words) # trim wordsNow, it is time to find the unique words (aka vocabulary) from which our dataset is composed of.
vocab = sorted(set(corpus_words))In order to train our model, we need to represent words with numbers. So we map a specific number to each unique word of our corpus and vice versa by creating the following lookup tables. Then we represent the whole corpus as a list of numbers (word_as_int).
print('Corpus length (in words):', len(corpus_words))
print('Unique words in corpus: {}'.format(len(vocab)))
word2idx = {u: i for i, u in enumerate(vocab)}
idx2words = np.array(vocab)
word_as_int = np.array([word2idx[c] for c in corpus_words])Our goal is to predict the next words that will follow in a sequence, given some starting words (a start sequence). In layman's terms, RNNs are able to maintain an internal state that depends on the elements (in our case elements = sequences of words) that the RNN has previously "seen". So, we train the RNN to take as an input a sequence of words and predict the output, which is the following word at each time step. As you can easily understand, if we run the model for many time steps we generate sequences of words!
In order to train it, we have to split our train dataset (aka corpus) in "batches" of sequences of words (as this is what we also want to predict). Then, we need to shuffle them, because we want to make the order with which the songs have been placed in the dataset indifferent for the RNN (and thus for the prediction it will do). If we do not shuffle them, RNN may learn the order of the songs in the corpus to and that may lead it to overfitting
Now it is time to slice the corpus into training batches. Each batch should contain seqLength words from the corpus.
For each splited sequence of words, there is also a target sequence which has the same length with the training one and it is the same but one word shifted to the right. So, we slice the text into seqLength+1 words slices and we use the first seqLength words as training sequence and we extract the target sequence as mentioned.
Example: Let's say our corpus contains the following verse:
I read the news today oh boy
About a lucky man who made the grade
Now, if the seqLength is 14, the training sequence will be :
I read the news today oh boy
About a lucky man who made the
and the target sequence will be:
read the news today oh boy
About a lucky man who made the grade.
We do so with the following lines:
# The maximum length sentence we want for a single input in words
seqLength = 10
examples_per_epoch = len(corpus_words)//(seqLength + 1) # number of seqLength+1 sequences in the corpus
# Create training / targets batches
wordDataset = tf.data.Dataset.from_tensor_slices(word_as_int)
sequencesOfWords = wordDataset.batch(seqLength + 1, drop_remainder=True) # generating batches of 10 words each, typically converting list of words (sequence) to string
def split_input_target(chunk): # This is where right shift happens
input_text = chunk[:-1]
target_text = chunk[1:]
return input_text, target_text # returns training and target sequence for each batch
dataset = sequencesOfWords.map(split_input_target) # dataset now contains a training and a target sequence for each 10 word slice of the corpusAs we mentioned earlier, before we feed our training batches in our RNN, we have to shuffle them to prevent the RNN from learning the order of the songs in the corpus which may lead it to overfitting.
BATCH_SIZE = 64 # each batch contains 64 sequences. Each sequence contains 10 words (seqLength)
BUFFER_SIZE = 100 # Number of batches that will be processed concurrently
dataset = dataset.shuffle(BUFFER_SIZE).batch(BATCH_SIZE, drop_remainder=True)dataset now contains batches of 64 word sequence each, each sequence is filled in the previous step with 10 words.
Our RNN is composed of 3 layers:
- Input layer. It maps the number representin each word to a vector with known dimensions (that are explicitly set)
- GRU (middle) layer: GRU stands for Gated Recurrent Units. The number of units that this layer contains is also explicitly set. This layer could also be replaced by a Long Short-Term Memory (LSTM) layer. More on LSTMs and GRUs in this useful link
- Output layer: It has as many units as the size of the vocabulary
The model definition code:
# Length of the vocabulary in words
vocab_size = len(vocab)
# The embedding dimension
embedding_dim = 256
# Number of GRU units
rnn_units = 1024
def createModel(vocab_size, embedding_dim, rnn_units, batch_size):
model = tf.keras.Sequential([
tf.keras.layers.Embedding(vocab_size, embedding_dim,
batch_input_shape=[batch_size, None]),
tf.keras.layers.GRU(rnn_units,
return_sequences=True,
stateful=True,
recurrent_initializer='glorot_uniform'),
tf.keras.layers.Dense(vocab_size)
])
return model
model = createModel(vocab_size = len(vocab), embedding_dim=embedding_dim, rnn_units=rnn_units, batch_size=BATCH_SIZE)For each word in the input layer, the model passes its embedding to the GRU layer for one step of time. The output of the GRU is then passed to the dense layer which predicts the log-likelihood of the next word.
The schematic below is a bit more descriptive.
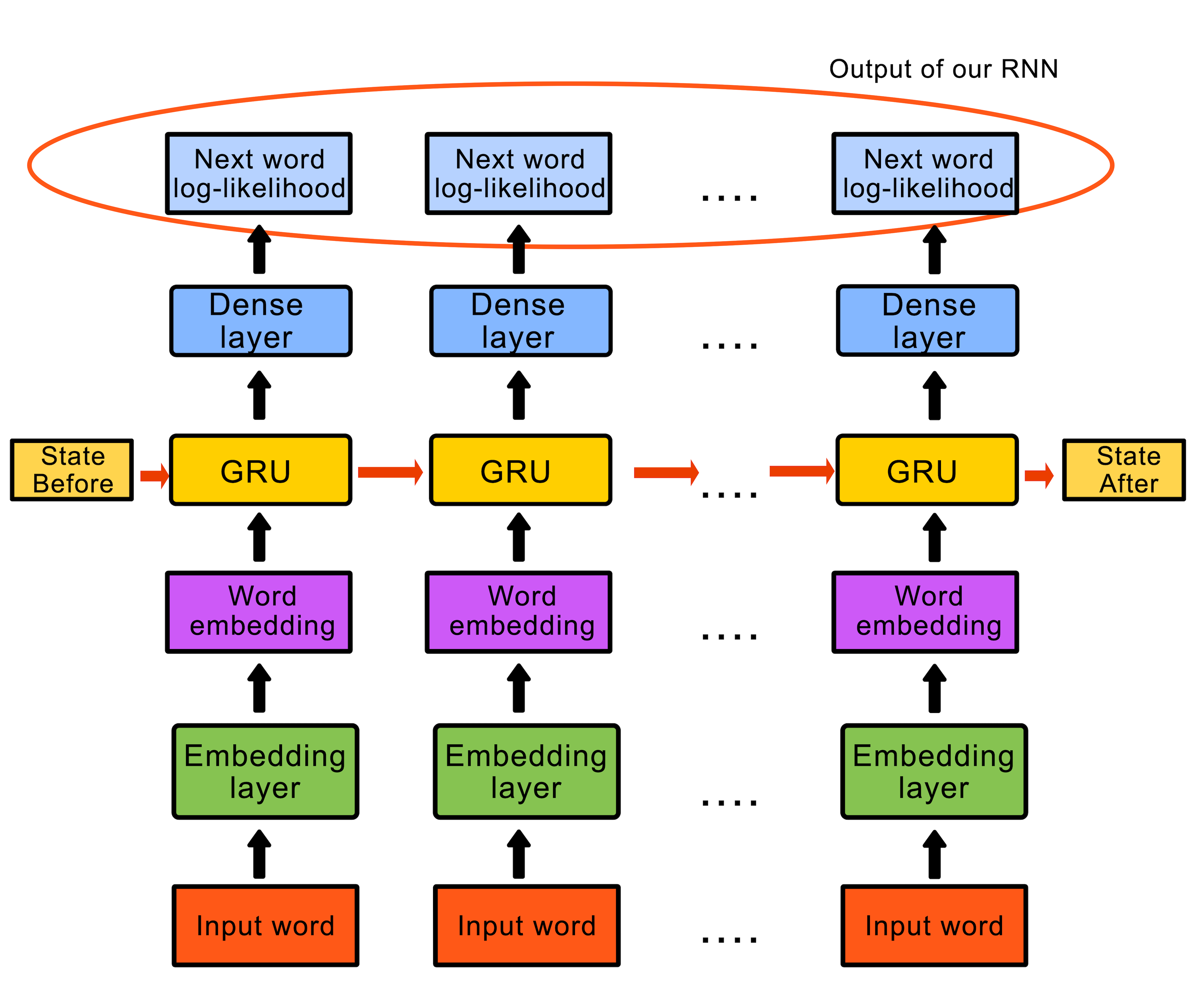
From now on, we can consider the problem as a simple classification problem. If you think about it, our model predicts the "class" of the next word based on its current state and the input words during a time step.
So, as in every classification model, in order to train it we need to calculate the loss in each time step.
We do so by defining the following function:
def loss(labels, logits):
return tf.keras.losses.sparse_categorical_crossentropy(labels, logits, from_logits=True)Then we compile the model using 'adam' oprimizer.
model.compile(optimizer='adam', loss=loss)During the training process, we should save checkpoints of the training in a directory that we have manually created
checkpoint_dir = './training_checkpoints'
checkpoint_prefix = os.path.join(checkpoint_dir, "ckpt_{epoch}")
checkpoint_callback=tf.keras.callbacks.ModelCheckpoint(
filepath=checkpoint_prefix,
save_weights_only=True)Now it is time to execute training. We explicitly set the number of epochs. At this point I would like to remind you that an epoch is one forward pass and one backward pass of all the training examples.
We choose to train for 20 epochs. Note that as you increase number of epochs, the training time will increase too. You should experiment with this number in order to fine tune the model. But be careful, training for too many epochs may lead to overfitting.
EPOCHS = 20
history = model.fit(dataset, epochs=EPOCHS, callbacks=[checkpoint_callback])After the training process is over, we restore the trained model form the latest checkpoint. It is time to generate the lyrics!
tf.train.latest_checkpoint(checkpoint_dir)
model = createModel(len(vocab), embedding_dim, rnn_units, batch_size=1)
model.load_weights(tf.train.latest_checkpoint(checkpoint_dir))
model.build(tf.TensorShape([1, None]))
model.summary()RNNs (as most of Neural network types in general) need an initial state to start predicting. In our case, this initialization is represented by a starting string with which we want the generated lyrics to start. The model generates the probability distribution of the next word using the start string and the RNN state.
Then, with the help of categorical distribution, the index of the predicted word is calculated and the predicted word is used as the input for the next time step of the model
The state that the RNN returns is then fed back to the input of the RNN, in order to help it by providing more context (not just one word). This process continues as it generates predictions and this is why it learns better while it gets more context from the predicted words.
The following function performs the task mentioned above:
def generateLyrics(model, startString, temp):
print("---- Generating lyrics starting with '" + startString + "' ----")
# Number of words to generate
num_generate = 30
# Converting our start string to numbers (vectorizing)
start_string_list = [w for w in startString.split(' ')]
input_eval = [word2idx[s] for s in start_string_list]
input_eval = tf.expand_dims(input_eval, 0)
text_generated = []
model.reset_states()
for i in range(num_generate):
predictions = model(input_eval)
# remove the batch dimension
predictions = tf.squeeze(predictions, 0)
# temp represent how 'conservative' the predictions are.
# Lower temp leads to more predictable (or correct) lyrics
predictions = predictions / temp
predicted_id = tf.random.categorical(predictions, num_samples=1)[-1,0].numpy()
# We pass the predicted word as the next input to the model
# along with the previous hidden state
input_eval = tf.expand_dims([predicted_id], 0)
text_generated.append(' ' + idx2words[predicted_id])
return (startString + ''.join(text_generated))model.py also contains a "demo part". After training process is finished, it saves the model in a binary file (you can then restore it in one line of code and us it instantly to predict values) for future use so we do not have to train it every time we want to generate lyrics.
#save trained model for future use (so we do not have to train it every time we want to generate text)
model.save('saved_model.h5')Then it calls the generateLyrics function with the start string "love" (We all know how much Beatles used) this word in their songs.
Then it propmpts the user to enter a start string and a temp value to generate lyrics.
Some examples that the model gave me:
Start string: "love"
Generated lyrics: "love youyouyouyou as i write this letter send my love to give you all my loving i will send to you all my loving i will send to you don't bother"
Start string: "boys and girls"
temp: 0.4
Generated lyrics: "boys and girls make me sing and shout that georgia's always be blind love is here to stay and that's enough to make you my girl be the only one love me hold"
Start string: "day"
temp: 0.8
Generated lyrics: "day tripper night at my own it will take a walk on home loretta get back get back get back get back get back get back get back get back get"
Hm... Not that bad.