How to combine wgan and spectral norm?
zhangqianhui opened this issue · 58 comments
Your spectral normalization normalizes the spectral norm of the weight matrix W so that it satisfies the Lipschitz constraint = 1. So we consider whether to combine the wasserstein gan with spectral normalization or not?
So, we have done some related experiments using wgan with sn normalization(remove gradient penalty). However, The network is very unstable and hard to generate very high-quality samples.
We hope to know how to combine wgan and your sn normalization without gradient penalty?
Hi,
We have tried the combination of wgan loss and spectral normalization, but it does not work.
We are not sure why that happens, and also happy if you have ideas on that problem!
Recently, I combine wgan loss and spectral norm, and got a better result than before.
Some changes in our experiments.
(1) D network, using spectral norm, but remove fully_connect layers
(2) Using RMSprop instead of Adam.
(3) Add a regu term for D loss(proposed by pg-gan) to keep the output values from drifting too far away from zero:
0.0001 * tf.reduce_mean(tf.square(self.D_pro_logits))
You can try, these are for reference only.
If necessary, I will public this code.
--OO--
Thanks so much! and there perhaps are some people who have the same issue, so I appreciate if you make your implementation public.
@takerum Ask you some questions:
- Table 2 in SN-GAN paper, How do you calculate the FID score of real data? (7.8)
- Table 2 How many generated samples are used for getting FID or Inception scores? 5000 or 50000?
@takerum Your paper used 5000 samples to compute FID and Inception score. But in improved-gan paper, they use 50000 samples to get Inceptions scores.
????
Table 2 in SN-GAN paper, How do you calculate the FID score of real data? (7.8)
We sample 10000 images on test set and 5000 images on training set and calculate FID on the two sets of the images.
Table 2 How many generated samples are used for getting FID or Inception scores? 5000 or 50000?
Your paper used 5000 samples to compute FID and Inception score. But in improved-gan paper, they use 50000 samples to get Inceptions scores.
Both of the original paper and our paper use 50,000 samples for calculating the "mean" and "std" of the inception scores.
The original paper and our paper calculate inception score with 5,000 samples and repeated 10 times to estimate the mean and variance of inception scores on each independently generated set of images.
For FID, we calculate it with 5,000 samples and report the value, because we found that the variation of FID within independent sets is very small compared to the value of FID.
ok, thanks
I got 7.78 scores of FID for real data.
For FID, we calculate it with 5,000 samples and report the value, because we found that the variation of FID within independent sets is very small compared to the value of FID.
Friendly PSA: don't do this. The FID estimator has very low variance across runs, but very strong bias, especially due to the sample size; the numbers can only be compared with a consistent sample size, and most people use 50,000. Check out section 4 (starting page 7) and appendix D (starting page 30) of our paper Demystifying MMD GANs for more about this.
@takerum Now, I use tensorflow to implement dcgan+sn.
The training parameter is
batch_size=16; softplus function for standard loss; learn_rate=0.002; sn=True; not resnet; n_critic=5;
beta2=0.9; iterations = 100,000; dataset=cifar10; The architecture is same to Table 3(a)
I got 7.06+-0.08 inception scores, which is lower than 7.42+-0.08 of table 2 in your paper.
Can you tell me the reason?
So, I want to ask you some question about the experiments corresponding to inception score of sn-gans in cifar10(7.42+-0.08) ?
(1)What is the number of all iterations?
(2)Are you using decay of learning rate?
(3)The init methods of weights.
please look at https://github.com/pfnet-research/chainer-gan-lib.
This repository includes the reproducing code of SN-GANs on CIFAR-10 dataset.
thank you
@takerum , using the default parameters?
def main():
parser = argparse.ArgumentParser(description='Train script')
parser.add_argument('--algorithm', '-a', type=str, default="dcgan", help='GAN algorithm')
parser.add_argument('--architecture', type=str, default="dcgan", help='Network architecture')
parser.add_argument('--batchsize', type=int, default=64)
parser.add_argument('--max_iter', type=int, default=100000)
parser.add_argument('--gpu', '-g', type=int, default=0, help='GPU ID (negative value indicates CPU)')
parser.add_argument('--out', '-o', default='result', help='Directory to output the result')
parser.add_argument('--snapshot_interval', type=int, default=10000, help='Interval of snapshot')
parser.add_argument('--evaluation_interval', type=int, default=10000, help='Interval of evaluation')
parser.add_argument('--display_interval', type=int, default=100, help='Interval of displaying log to console')
parser.add_argument('--n_dis', type=int, default=5, help='number of discriminator update per generator update')
parser.add_argument('--gamma', type=float, default=0.5, help='hyperparameter gamma')
parser.add_argument('--lam', type=float, default=10, help='gradient penalty')
parser.add_argument('--adam_alpha', type=float, default=0.0002, help='alpha in Adam optimizer')
parser.add_argument('--adam_beta1', type=float, default=0.0, help='beta1 in Adam optimizer')
parser.add_argument('--adam_beta2', type=float, default=0.9, help='beta2 in Adam optimizer')
parser.add_argument('--output_dim', type=int, default=256, help='output dimension of the discriminator (for cramer GAN)')
yes we used the default parameters other than those we specified here: https://github.com/pfnet-research/chainer-gan-lib/blob/master/example.sh#L8
Thanks!
@zhangqianhui Thanks for the suggestion! Should we include all below? Or which one is the most important for that wgan works with spectral norm?
(1) D network, using spectral norm, but remove fully_connect layers
(2) Using RMSprop instead of Adam.
(3) Add a regu term for D loss(proposed by pg-gan) to keep the output values from drifting too far away from
Sorry, I am not sure. You can try.
@takerum hello, can you help me to check this implement of spectral norma function below?
def spectral_norm(w, iteration= 1):
w_shape = w.shape.as_list()
w = tf.reshape(w, [-1, w_shape[-1]])
# w = tf.reshape(w, [1, w.shape.as_list()[0] * w.shape.as_list()[1]])
u = tf.get_variable("u", [1, w.shape.as_list()[-1]], initializer=tf.truncated_normal_initializer(), trainable=False)
u_hat = u
v_hat = None
for i in range(iteration):
"""
power iteration
Usually iteration = 1 will be enough
"""
v_ = tf.matmul(u_hat, tf.transpose(w))
v_hat = _l2normalize(v_)
u_ = tf.matmul(v_hat, w)
u_hat = _l2normalize(u_)
#real_sn = tf.svd(w, compute_uv=False)[...,0]
sigma = tf.matmul(tf.matmul(v_hat, w), tf.transpose(u_hat))
w_norm = w / sigma
#Get the real spectral norm
#real_sn_after = tf.svd(w_norm, compute_uv=False)[..., 0]
#frobenius norm
#f_norm = tf.norm(w, ord='fro', axis=[0, 1])
#tf.summary.scalar("real_sn", real_sn)
tf.summary.scalar("powder_sigma", tf.reduce_mean(sigma))
#tf.summary.scalar("real_sn_afterln", real_sn_after)
#tf.summary.scalar("f_norm", f_norm)
with tf.control_dependencies([u.assign(u_hat)]):
w_norm = tf.reshape(w_norm, w_shape)
return w_norm
I can not find the problem, but hard to get the same scores using the default hyper-paramters that you mentioned above?
@zhangqianhui I think you should try to add u_hat = tf.stop_gradient(u_hat) and v_hat = tf.stop_gradient(v_hat) to avoid the gradient from v_hat and u_hat to w. Like the code below from @takerum, _v and _u have no gradient to W, but sigma has.
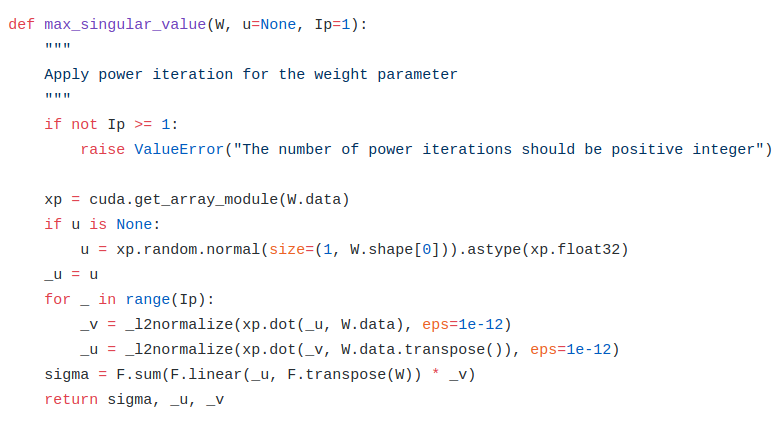
My implementation: https://github.com/LynnHo/GAN-Techniques-Tensorflow/blob/master/tflib/layers/layers.py
@zhangqianhui This is my SN implementation in TF.
def sn(W, collections=None, seed=None, return_norm=False, name='sn'):
shape = W.get_shape().as_list()
if len(shape) == 1:
sigma = tf.reduce_max(tf.abs(W))
else:
if len(shape) == 4:
_W = tf.reshape(W, (-1, shape[3]))
shape = (shape[0] * shape[1] * shape[2], shape[3])
else:
_W = W
u = tf.get_variable(
name=name + "_u",
shape=(FLAGS.num_sn_samples, shape[0]),
initializer=tf.random_normal_initializer,
collections=collections,
trainable=False
)
_u = u
for _ in range(FLAGS.Ip_sn):
_v = tf.nn.l2_normalize(tf.matmul(_u, _W), 1)
_u = tf.nn.l2_normalize(tf.matmul(_v, tf.transpose(_W)), 1)
_u = tf.stop_gradient(_u)
_v = tf.stop_gradient(_v)
sigma = tf.reduce_mean(tf.reduce_sum(_u * tf.transpose(tf.matmul(_W, tf.transpose(_v))), 1))
update_u_op = tf.assign(u, _u)
with tf.control_dependencies([update_u_op]):
sigma = tf.identity(sigma)
if return_norm:
return W / sigma, sigma
else:
return W / sigma
@zhangqianhui
您好,您是使用WGAN损失函数Ex∼qdata[D(x)]−Ez∼p(z)[D(G(z))] 和在判别器中使用谱归一化?这样进行有效果吗?
之前我试过直接在WGAN-GP加入谱归一化,结果生成器和判别器的loss都是nan。
@IPNUISTlegal
It works in my experiments, but could not get the higher inception scores than sn-gan
@zhangqianhui
@takerum
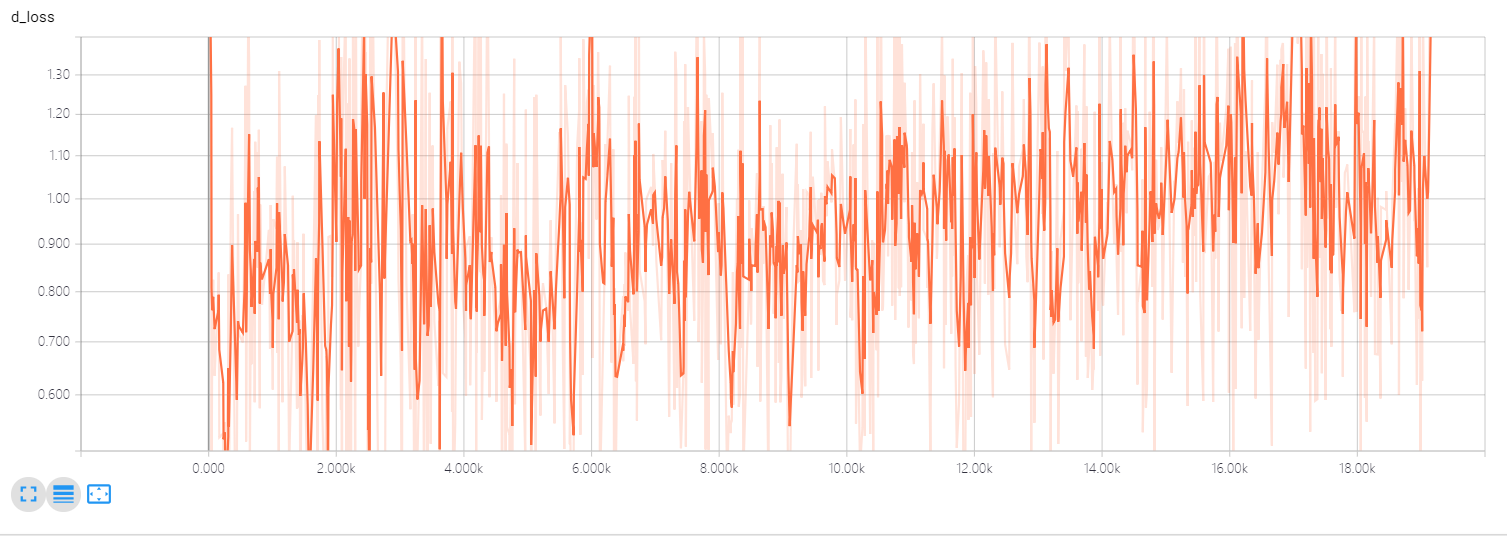
i apply hinge loss and spectral normalization to my experiment ,which actually outperform the WGAN-GP loss function with the same network structure.
a little pity, the discriminator loss does not convergence to a certain value and crazy up and down swing!
why?confused me many days
thx!(#^.^#)
Is it the curve of D loss using hinge loss ?
@zhangqianhui
yeah,it is the D loss using hinge loss and does not convergence to a certain value.
why?
thx
@IPNUISTlegal I think it is the normal curve. How is the quality the generated samples?
@zhangqianhui
that,combine hinge loss and apply SN to discriminator network , a little outperforms the WGAN-GP loss function with the same network structure.
why it is normal curve?
to my known, D loss value should decrease as the number of iterations increases , just like the G loss,
i am noob in GAN. thx!
I am confused that your problem, you can send your wechat id to my gmail(zhang163220@gmail.com).
@takerum hello, I ran your code using this parameter and got 7.24944 inception score, lower than 7.50 . Is it correct? Do you run many times to use the highest score?
The parameters:
def main():
parser = argparse.ArgumentParser(description='Train script')
parser.add_argument('--algorithm', '-a', type=str, default="stdgan", help='GAN algorithm')
parser.add_argument('--architecture', type=str, default="sndcgan", help='Network architecture')
parser.add_argument('--batchsize', type=int, default=64)
parser.add_argument('--max_iter', type=int, default=100000)
parser.add_argument('--gpu', '-g', type=int, default=0, help='GPU ID (negative value indicates CPU)')
parser.add_argument('--out', '-o', default='result', help='Directory to output the result')
parser.add_argument('--snapshot_interval', type=int, default=10000, help='Interval of snapshot')
parser.add_argument('--evaluation_interval', type=int, default=10000, help='Interval of evaluation')
parser.add_argument('--display_interval', type=int, default=100, help='Interval of displaying log to console')
parser.add_argument('--n_dis', type=int, default=5, help='number of discriminator update per generator update')
parser.add_argument('--gamma', type=float, default=0.5, help='hyperparameter gamma')
parser.add_argument('--lam', type=float, default=10, help='gradient penalty')
parser.add_argument('--adam_alpha', type=float, default=0.0002, help='alpha in Adam optimizer')
parser.add_argument('--adam_beta1', type=float, default=0.0, help='beta1 in Adam optimizer')
parser.add_argument('--adam_beta2', type=float, default=0.9, help='beta2 in Adam optimizer')
parser.add_argument('--output_dim', type=int, default=256, help='output dimension of the discriminator (for cramer GAN)')
The scores:
0.926269 1.18002 7.24944 0.108181 25.3894
total [##################################################] 100.00%
this epoch [..................................................] 0.00%
100000 iter, 640 epoch / 100000 iterations
1.33 iters/sec. Estimated time to finish: 0:00:00.
I tried only once and just reported it.
The hyper-parameters that achieve 7.5 are alpha=0.0002, beta1=0.5, beta2=0.999 (setting C in the paper), which seem to be different from the ones you set.
ok, I will try again.
@takerum , Hello, when training sn_gan on cifar10 dataset, just use the training data of cifar10 ? I found using the training data and test data for training can get more high inception scores.
Yes, only the training data is used for the training.
thanks
@takerum How many is max_iter on STL dataset in your paper.
what does 'max_iter' refer to? the number of iterations?
Hi, the code combining wgan loss and spectral norm is available now?
@HuaqiangWei sorry, no. I think this combination make no sense
@HuaqiangWei sorry, no. I think this combination make no sense
Thank you for your answer. But according to the paper, isn't spectral normalization a substitute for gradient punishment in WGAN-GP?
@HuaqiangWei sorry, no. I think this combination make no sense
Hi, In "Sn for GANs", It is shown that there are improvements, when SN is combined with WGAN-GP. Since SN achieves L-1 constraints, theoretically speaking, why SN with vanilla WGAN makes no sense? @zhangqianhui could you please explain?
It is hard to say. Yes you can use SN to achieve the constraints, but SN with vanilla WGAN is hard to get more high-quality samples generation than vanilla gan with sn in my experiments.
It is hard to say. Yes you can use SN to achieve the constraints, but SN with vanilla WGAN is hard to get more high-quality samples generation than vanilla gan with sn in my experiments.
Yeah, actually I have been trying SN + vanilla WGAN for 1 month with frustration. Generally the results are worse than WGAN-GP.
Maybe @takerum has an explanation in a theoretical aspect?
@zhangqianhui
I don't quite understand 'combine wgan and spectral norm'.
Actually I think currently the D (or critic) is approximating the wasserstein distance between p_r and p_g,
isn't it?
I just simply glimpse the sn code and I assume that it doesn't use cross entropy loss and doesn't use sigmoid at the end of D neither.
If so, I think sn-gan is optimizing the Wasserstein distance, the same with WGAN.
@zhangqianhui
I don't quite understand 'combine wgan and spectral norm'.
Actually I think currently the D (or critic) is approximating the wasserstein distance between p_r and p_g,
isn't it?I just simply glimpse the sn code and I assume that it doesn't use
cross entropy lossand doesn't usesigmoidat the end of D neither.
If so, I think sn-gan is optimizing the Wasserstein distance, the same with WGAN.
In the original paper, they didn't use vanilla WGAN loss + SN (when they did, it performs worse). What they tried is WGAN+GP+SN
@zhangqianhui This is my SN implementation in TF.
def sn(W, collections=None, seed=None, return_norm=False, name='sn'): shape = W.get_shape().as_list() if len(shape) == 1: sigma = tf.reduce_max(tf.abs(W)) else: if len(shape) == 4: _W = tf.reshape(W, (-1, shape[3])) shape = (shape[0] * shape[1] * shape[2], shape[3]) else: _W = W u = tf.get_variable( name=name + "_u", shape=(FLAGS.num_sn_samples, shape[0]), initializer=tf.random_normal_initializer, collections=collections, trainable=False ) _u = u for _ in range(FLAGS.Ip_sn): _v = tf.nn.l2_normalize(tf.matmul(_u, _W), 1) _u = tf.nn.l2_normalize(tf.matmul(_v, tf.transpose(_W)), 1) _u = tf.stop_gradient(_u) _v = tf.stop_gradient(_v) sigma = tf.reduce_mean(tf.reduce_sum(_u * tf.transpose(tf.matmul(_W, tf.transpose(_v))), 1)) update_u_op = tf.assign(u, _u) with tf.control_dependencies([update_u_op]): sigma = tf.identity(sigma) if return_norm: return W / sigma, sigma else: return W / sigma
@takerum
hi. I have some questions about the code.
_W.shape = (shape[0] * shape[1] * shape[2], shape[3])
_u.shape = (FLAGS.num_sn_samples, shape[0])
tf.matmul(_u, _W)
This formula cannot be calculated
Just put spectral norm in the generator too and it works. No gradient penalty needed.
@dougsouza
What kind of CNN architecture do you use?
@w86763777, I used the same network as SNGAN + Self Attention. I did not pursue much, but noticed that using SN on G helps to stabilize training. It is also a good idea to get rid of fully connected layers and use a smaller learning rate. Even though training is "stable", results are not very good and some spikes in the loss sometimes lead to collapse.
Hi guys, I kind of have this feeling that equation 7 in this paper (spectral normalization) requires a stronger necessary condition than the one used in the gradient penalty paper (Proposition 1 in improved training of wasserstein gan). Equation 7 only makes sense when equation 1 holds, which however might not be the real case in more complexed generator models. Perhaps this is the reason why spectral norm cannot simply be used to replace gradient penalty?
@IPNUISTlegal
It works in my experiments, but could not get the higher inception scores than sn-gan
Happen to see your post here. I never obtain success on WGAN loss with SN. Do you obtain the results with other tricks such as the regularization of D loss (which is similar to GP) you mentioned above?
I am also interested if anyone has achieved good results with just SN on WGAN.
I seem so see it in literature and blog posts as a good candidate to GP, but am unable to find any good code example where the Discriminator/Critic converges nicely.