ETL — Apache Kafka
Apache Kafka[fn:kafka] to platforma open-source do rozproszonego przetwarzania danych w postaci strumieniowej.
Na początku była rozwijana przez LinkedIn, następnie otrzymała wsparcie od Apache Software Foundation. Napisana jest w językach Scala i Java.
W uproszczeniu, pełni rolę pośrednika pomiędzy instancjami wysyłającymi dane (sender, producer) i odbierającymi je (receiver, consumer). Kafka przetwarza jednostki danych zwane zdarzeniami lub wiadomościami (events, messages). Przykładowym zdarzeniem może być np. transakcja finansowa, zmiana współrzędnych geograficznych, odczyt sensora w urządzeniu IoT itp. Zdarzenia (events) są przyporządkowane do kategorii zwanych topics. Konsumenci (consumers) mogą otrzymywać dane, gdy zasubskrybują jakiś topic- wówczas otrzymują dane w postaci strumienia (stream).
Do Kafki podłączamy 4 typy elementów:
- Producers - aplikacje udostępniające strumienie
- Consumers - aplikacje subskrybujące i odbierające strumienie
- Stream Processors - aplikacje pobierające strumienie i produkujące kolejne strumienie (transformujące strumienie)
- Connectors - procesy/aplikacje łączące topiki Kafki z jakimiś aplikacjami, systemami bazodanowymi itp.
Dla każdego z tych typów mamy osobne API Kafki.
W naszym przypadku Producentem jest aplikacja Prometheus, a konsumentem baza danych Cockroach. W celu ładowania danych z Prometheusa użyto odpowiedniego adaptera[fn:adapter] stworzonego przez firmę Telefónica.
[fn:kafka]https://kafka.apache.org [fn:adapter]https://github.com/Telefonica/prometheus-kafka-adapter
Data warehouse — CockroachDB
CockroachDB[fn:cockroach] to rozproszona baza danych, której core jest dostępny za darmo.
Wysokopoziomowo to relacyjna baza danych, wykorzystuje SQL. Niskopoziomowo wykorzystuje mechanizm typu klucz-wartość, o wysokim stopniu spójności.
Baza została zaprojektowana do wysokiej i niskokosztowej skalowalności przy zachowaniu dużej odporności na awarie.
CockroachDB wspiera protokół wymiany danych bazy PostgreSQL, co oznacza, że jest kompatybilna z tą bazą danych (i narzędziami opartymi o nią).
W naszym projekcie baza danych CockroachDB służy jako hurtownia danych. Trafiają tam dane po preprocessingu (po przejściu przez różne ETL w Kafce).
Zarządzanie usługami — Docker
Docker[fn:docker] to platforma Open Source umożliwiająca tworzenie kontenerów (containers) i uruchamianie w nich aplikacji.
Kontenery są formą wirtualizacji. Są to aplikacje, które izolują jakiś kod (program) wraz z potrzebnymi mu bibliotekami od reszty środowiska (systemu). W kontenerach jesteśmy w stanie uruchamiać aplikacje napisane pod system Linux w systemie Windows.
Kontenery różnią się od maszyn wirtualnych tym, że wykorzystują jądro systemu operacyjnego gospodarza - nie instalujemy kolejnego systemu operacyjnego ,,w całości”, jedynie potrzebne komponenty. Są więc znacznie lżejsze.
Aby uruchomić kontener w systemie Windows, musimy wpierw podjąć następujące kroki:
- w panelu Funkcje systemu Windows uruchamiamy potrzebne funkcje: (Może być konieczne ponowne uruchomienie komputera)
- Platforma funkcji Hypervisor systemu Windows
- Platforma maszyn wirtualnych
- Podsystem Windows dla systemu Linux.
- zainstalowanie WSL 2
W projekcie wykorzystujemy mechanizm docker compose. Za jego pomocą z użyciem jednego pliku
instrukcji dla Dockera jesteśmy w stanie automatycznie wygenerować kontenery dla wszystkich
potrzebnych nam serwisów - Docker sam pobierze obrazy (images) kontenerów z repozytorium,
a następnie je uruchomi.
Nasz plik z instrukcjami docker compose: docker-compose.yml. Widzimy tam, że tworzymy osobny
kontener dla każdej z aplikacji: Zookeeper, Kafka, adapter do Kafki, Grafana, CockroachDB.
W pliku określamy nazwę obrazu kontenera i parametry takie jak woluminy, porty przez które
możliwa będzie komunikacja.
[fn:docker]https://www.docker.com
Tworzenie wykresów — Grafana
Grafana[fn:grafana] to system open source przeznaczony do monitorowania i analizy zbiorów danych (zwykle dużych, poszerzających się w czasie, często pochodzących z wielu źródeł). Jest to aplikacja webowa (korzystamy z niej z użyciem przeglądarki internetowej). Umożliwia m. in.:
- tworzenie zapytań
- interaktywną wizualizację
- alertowanie
W Grafanie tworzymy dashboardy - raporty w formie pulpitów prezentujące wizualne analizy (głównie wizualizacje). Podstawowym ,,klockiem”, z którego budujemy dashboard, jest panel - dla każdego panelu tworzymy zapytanie, definiujemy typ wizualizacji itd.
Dostępnych jest wiele typów wizualizacji - np. wykres liniowy, wykres słupkowy, wskaźnik (gauge), mapa cieplna (heatmap) i inne. Można też wyświetlać wyniki obliczeń w formie liczb i tekst.
W Grafanie możemy dodawać wiele źródeł danych. Wspieranych jest większość popularnie używanych DBMS - w tym relacyjne, NoSQL, bazy do szeregów czasowych.
Grafanę wykorzystujemy jako narzędzie do przeprowadzania docelowych analiz danych po transformacjach przygotowujących je do tych analiz. Dane te przechowujemy w bazie danych CockroachDB.
[fn:grafana]https://grafana.com/
Źródło danych — Prometheus
Prometheus[fn:prometheus] to open source’owy toolkit do monitoringu i alertowania. Przechowuje szeregi czasowe w modelu wielowymiarowym. Zawiera własny język zapytań PromQL.
W naszym projekcie W Prometheuszu przechowujemy surowe dane zebrane w monitoringu serwera, które następnie są przekazywane do obróbki.
[fn:prometheus]https://prometheus.io
Apache Kafka[fn:kafka]
- W celu ładowania danych z Prometheusa użyto odpowiedniego adaptera[fn:adapter] stworzonego przez firmę Telefónica.
- Klient Kafki — Faust[fn:faust]
[fn:kafka]https://kafka.apache.org [fn:adapter]https://github.com/Telefonica/prometheus-kafka-adapter [fn:faust]https://github.com/faust-streaming/faust
CockroachDB[fn:cockroach] (kompatybilny z PostgreSQL) [fn:cockroach]https://www.cockroachlabs.com/
Cały projekt można podzielić na trzy kluczowe elementy:
- Usługi zewnętrzne;
- Transformacje danych w ETL;
- Analiza danych przetworzonych.
Pierwszy element jako jedyną zależność posiada Dockera. Dwie następne natomiast opierają się o Pythona w wersji
docker compose upW przypadku braku podkomendy compose należy pobrać docker-compose z repozytorium Pythona przez komendę oraz uruchomić usługi
pip install -U docker-composePozostałe części projektu można przygotować do uruchomienia uruchomienie następujących komend (instrukcje dla Linuxa, dla Windowsa zmienia się jedynie pierwsza komenda).
source .venv/bin/activate.sh
pip install -r requirements.txt[fn:docker-installation] https://docs.docker.com/get-docker/
W celu uruchomienia projektu należy najpierw uruchomić usługi zewnętrzne. Można to zrobić korzystając z Dockera.
docker compose upJeśli ta komenda nie działa — należy użyć opcji z myślnikiem
docker-compose upWszystkie usługi można zatrzymać przez kombinację klawiszy Ctrl + C.
Usługi, które zostały napisane przez nas należy uruchomić bezpośrednio przez Pythona.
python FOLDER/main.pyGdzie FOLDER należy zastąpić odpowiednią nazwą.
W celu przystosowania projektu do własnej infrastruktury należy uruchomić Promehteusa z wybranymi eksporterami zgodnie z [[https://prometheus.io/docs/prometheus/latest/installation/][dokumentacją[fn::https://prometheus.io/docs/prometheus/latest/installation/]]] wybraną metodą.
Ponad to należy zmienić w pliku etls/app.py adresy IP, hasła oraz nazwy bazy danych czy użytkowników zgodnie z ustawieniami.
Zadaniem modułów Extract-Transform-Load był export danych do takiej struktury, by można było dokonywać swobodnej analizy na wielu wymiarach.
Schemat modułu ETL przedstawia rysunek. Jak widać, składa się on z kilku części składowych, których działanie i konfigurację opiszemy poniżej.

Pierwszym etapem było wyeksportowanie danych z Prometheusa do brokera Kafka. Do tego celu użyliśmy adaptera przygotowanego przez firmę Telefonica. Format serializacji ustawiliśmy na JSON.
Centralnym modułem naszego programu w Fauście jest plik app.py:
import faust
import faust.tables.sets
import psycopg2
from data_parse_and_clean import parse_measurement, flat_dict_from_record
from data_push import create_table, insert_measurement
from record import MeasurementRecord, ParsedRecord
app = faust.App(
"wad_distributor",
broker="kafka://100.111.43.19:9091",
value_serializer="json",
)
conn = psycopg2.connect(
host="100.111.43.19",
database="mda",
user="mda",
port=26257,
)
existing_labels = app.Table("labels", partitions=1, default=list)
metrics_topic = app.topic("metrics", value_type=MeasurementRecord)
@app.agent(metrics_topic)
async def systemd_push(measurements):
async for measurement in measurements:
measurement = parse_measurement(measurement=measurement)
measurement = flat_dict_from_record(measurement)
insert_measurement(conn, measurement, existing_columns=existing_labels)
@app.timer(interval=10.0)
async def commiting():
print("commiting")
conn.commit()
if __name__ == "__main__":
create_table(conn)
app.main()
conn.close()Najpierw, po zaimportowaniu odpowiednich modułów, tworzymy obiekty: aplikacji Fausta oraz połączenia z bazą danych psycopg2. Następnie tworzymy tabelę Fausta, w której będziemy przechowywać nazwy istniejących kolumn w bazie, oraz obiekt topicu metrics, na którym będą się pojawiać dane z Prometheusa wysłane przez adapter.
Następnie tworzymy w aplikacji Fausta narzędzia do zarządzania daynmi. Tworzymy funkcję asynchroniczną
systemd_push, którą za pomocą dekoratora zamieniamy w agenta na topiku metrics. W funkcji tworzymy
asynchroniczną pętlę for. W pętli tej możemy zdefiniować działania, które chcemy wykonać na każdym
obiekcie (rekordzie), który spłynie do nas z topica. Każdy rekord najpierw traktujemy funkcją parse_measurement,
która służy do sparsowania rekordu Fausta do typów danych Pythona, dodatkowo uzupełniając niektóre braki danych
(jej kod poniżej). Następnie sparsowany rekord traktujemy funkcją flat_dict_from_record. Jej użycie jest
konieczne, ponieważ w surowych danych mamy zagnieżdżony obiekt typu dict, więc w takim formacie ciężko by było
wysłać rekord do bazy. Następnie wysyłamy rekord do bazy funkcją insert_measurement (o tym w kolejnym podrozdziale).
Poniżej kod pliku record.py:
import faust
from datetime import datetime
from typing import Dict, Optional
class MeasurementRecord(faust.Record, serializer="json"):
timestamp: str
value: str
name: str
labels: Dict[str, str]
class ParsedRecord(faust.Record, serializer="json"):
timestamp: datetime
value: float
name: str
labels: Optional[Dict[str, str]]
Jest to tylko plik z klasami reprezentującymi rekord, który otrzymujemy, oraz sparsowany przez nas rekord. Widzimy w nim pola, które otrzymujemy z Prometheusa: timestamp, value (wartość metryki), name (nazwa metryki), labels (dodatkowe pola).
Kod pliku data_parse_and_clean.py:
import faust
from record import MeasurementRecord, ParsedRecord
from datetime import datetime
from typing import Dict, Union
def parse_measurement(measurement: MeasurementRecord) -> ParsedRecord:
try:
timestamp = datetime.strptime(measurement.timestamp, "%Y-%m-%dT%H:%M:%SZ")
except ValueError:
timestamp = datetime.fromtimestamp(0)
try:
value = float(measurement.value)
except ValueError:
value = None
name = measurement.name
labels = measurement.labels
return ParsedRecord(timestamp=timestamp, value=value, name=name, labels=labels)
def flat_dict_from_record(record: ParsedRecord) -> Dict[str, Union[str, int, datetime]]:
dumped = record.asdict()
dumped_labels = dumped.pop("labels")
try:
dumped_labels.pop("__name__")
except KeyError:
pass
dumped_labels = dict(
zip(
map(lambda x: "label_" + str(x), dumped_labels.keys()),
dumped_labels.values(),
)
)
return {**dumped, **dumped_labels}
Pierwsza funkcja parse_measurement przyjmuje surowy rekord z Prometheusa, gdzie wszystkie
dane zapisane są w formie ciągu znaków. Tworzy rekord z typami danych Pythona. Jeśli
timestamp jest nieprawidłowy, wprowadzana jest domyślna wartość. Jeśli wartość jest
nieprawidłowa, wstawiana jest wartość pusta. Druga funkcja flat_dict_from_record
“spłaszcza” rekord - usuwa zagnieżdżony obiekt z rekordu, przenosząc pola z niego do rekordu.
Za ładowanie danych do bazy danych Cockroach odpowiedzialna jest biblioteka psycopg2 oraz wykorzystująca ją funkcja insert_measurement, zdefiniowana w module data_push.py:
from typing import Any, Dict, Iterable
import faust
import psycopg2
import sys
import faust.types.tables
def create_table(conn):
command = """
CREATE TABLE IF NOT EXISTS measurements (
id UUID NOT NULL DEFAULT gen_random_uuid(),
timestamp TIMESTAMP NOT NULL,
name STRING NULL,
value FLOAT NULL,
CONSTRAINT "primary" PRIMARY KEY (id),
FAMILY "primary" (id, timestamp, name, value)
);
"""
try:
cur = conn.cursor()
cur.execute(command)
cur.close()
except (Exception, psycopg2.DatabaseError) as error:
sys.stderr.write(f"{str(error)}")
def insert_measurement(
conn, record: Dict[str, Any], existing_columns: faust.types.tables.TableT
) -> None:
command = f"""
INSERT INTO measurements ({', '.join(record.keys())})
VALUES ({'%s, ' * (len(record.keys()) - 1) + '%s'});"""
new_columns = list(
filter(lambda x: x not in existing_columns["labels"], record.keys())
)
existing_columns["labels"] += new_columns
if len(new_columns) > 0:
insert_column(conn, new_columns)
try:
cur = conn.cursor()
cur.execute(
command,
list(record.values()),
)
cur.close()
except (Exception, psycopg2.DatabaseError) as error:
sys.stderr.write(f"DB ERROR (insert record) {str(error)}")
def insert_column(conn, colnames: Iterable[str]) -> None:
try:
conn.commit()
cur = conn.cursor()
for i in colnames:
cur.execute(
f"ALTER TABLE IF EXISTS measurements ADD COLUMN IF NOT EXISTS {i} STRING;"
)
cur.close()
except (Exception, psycopg2.DataError) as error:
sys.stderr.write(f"DB ERROR (insert_column) {str(error)}")
conn.commit()
cur = conn.cursor()
for i in colnames:
cur.execute(
f"ALTER TABLE IF EXISTS measurements ADD COLUMN IF NOT EXISTS {i} STRING;"
)
cur.close()
except (Exception, psycopg2.DataError) as error:
sys.stderr.write(f"DB ERROR (insert_column) {str(error)}")
conn.commit()Zanim wprowadzimy dane do bazy, musimy najpierw utworzyć tabelę. Służy do tego funkcja create_table,
gdzie mamy zdefiniowaną kwerendę SQL oraz jej wywołanie. Z kolei poszczególne rekordy wysyłany
do bazy za pomocą funkcji insert_measurement, która wykonuje dwa zadania: dodaje kolumnę, jeśli w
otrzymanym rekordzie jest nowe pole, (za pomocą funkcji insert_column zdefiniowanej poniżej),
oraz wysłanie kwerendy INSERT.
Dane do przetwarzania są przesyłane do modeli w osobnych topicach, które pozwalają na stworzenie osobnych workerów przetwarzających informacje. W tym celu zostały stworzone osobne topici na Kafce, dodatkowy router wiadomości oraz workery nasłuchujące. W łatwy sposób można przesłać dane dalej i granularyzować je dowolnie.
W Grafanie przygotowaliśmy kilka dashboardów, które są zbiorami wizualizacji danych, które zbieramy. Grafana pozwala na zapisywanie dashboardów i organizowanie ich w katalogi.
Wartością metryki jest wartość kolumny value, kolumna name zawiera nazwę metryki. Pole timestamp zawiera znacznik czasowy próbki. Oprócz tego różne próbki mają różne dodatkowe pola (pochodzące z obiektu labels), zawierające dodatkowe atrybuty. W części wizualizacji dokonujemy agregacji po czasie - zwykle 1-minutowej bądź 5 - minutowej. Funkcja agregacji jest różna - suma, średnia bądź zliczenie, w zależności od kontekstu.
Poniżej listujemy nazwy dashboardów i przedstawiamy należące do nich wizualizacje.
- Machine
Na tym dashboardzie prezentujemy kilka ogólnych informacji na temat monitorowanej maszyny, w sposób tekstowy i wizualny.

Widzimy, że po prawej stronie u góry możemy dostosować okno czasowe, które chcemy oglądać, dla całego dashboardu. Na tym dashboardzie mamy dwa panele, gdzie panel po lewej stronie zawiera tekstową prezentację danych, a panel po prawej stronie zawiera wykres szeregu czasowego. Panel tekstowy przedstawia podstawowe parametry maszyny, które udało się uzyskać z danych: liczba rdzeni CPU, liczba rdzeni fizycznych CPU, czy liczba bajtów pamięci. Po prawej stronie mamy wykres zużycia pamięci przez procesy, w rozbiciu na resident memory (faktyczną fizyczną porcję pamięci w użyciu) oraz virtual memory (porcję pamięci, którą widzą procesy). Jest to liczba bajtów zagregowana po czasie (kubełki minutowe). Widzimy, że zużycie pamięci wirtualnej jest znacznie wyższe, czego należało się spodziewać.
- Container
Dashboard ten przedstawia podsumowania statystyk dotyczących pracy kontenerów.






 Na początku ogólne informacje, jak czas startu czy zużycie procesora. Następnie informacje (niezbyt ciekawe)
na temat systemu plików kontenera. Następnie wizualizacje zużycia pamięci (widzimy na przykład na panelu Memory failures,
że najwięcej problemów związanych z pamięcia było w okresie 15:57-16:04 - wcale nie w okresie, gdzie zużycie
pamięci było najwyższe, co pokazuje panel Memory usage). Na końcu mamy jeszcze garść informacji dotyczących
sieci kontenerowej. Widzimy znaczny wzrost otrzymanych pakietów pod koniec działania systemu.
Na początku ogólne informacje, jak czas startu czy zużycie procesora. Następnie informacje (niezbyt ciekawe)
na temat systemu plików kontenera. Następnie wizualizacje zużycia pamięci (widzimy na przykład na panelu Memory failures,
że najwięcej problemów związanych z pamięcia było w okresie 15:57-16:04 - wcale nie w okresie, gdzie zużycie
pamięci było najwyższe, co pokazuje panel Memory usage). Na końcu mamy jeszcze garść informacji dotyczących
sieci kontenerowej. Widzimy znaczny wzrost otrzymanych pakietów pod koniec działania systemu.
- Traefik - reverse proxy
Tutaj przygotowaliśmy wizualizacje danych dotyczących działania reverse proxy.


 Możemy zauważyć, że ostatnia próbka, która zawierała informację na ten temat, mówiła o 1 otwartym połączeniu entrypoint
oraz braku otwartych połączeń service. Następnie wykresy metryk Request duration - sum oraz count (tutaj
nie agregowaliśmy danych, wyświetliliśmy je w czystej postaci.) Możemy zobaczyć całkowite liczby zapytań.
Możemy zauważyć, że ostatnia próbka, która zawierała informację na ten temat, mówiła o 1 otwartym połączeniu entrypoint
oraz braku otwartych połączeń service. Następnie wykresy metryk Request duration - sum oraz count (tutaj
nie agregowaliśmy danych, wyświetliliśmy je w czystej postaci.) Możemy zobaczyć całkowite liczby zapytań.
- Miscellaneous
Na tym dashboardzie dokonaliśmy kilku podsumowań dotyczących dodatkowych atrybutów, jakie system przydzielał niektórym próbkom.
 Tutaj jedyną możliwą agregacją było zliczanie COUNT, ponieważ wartości value mogły dotyczyć różnych metryk.
Zależało nam jedynie na zliczeniu i porównaniu ilości rekordów, które miały dane wartości danego atrybutu.
Interpretacja tych wizualizacji nie jest łatwa.
Tutaj jedyną możliwą agregacją było zliczanie COUNT, ponieważ wartości value mogły dotyczyć różnych metryk.
Zależało nam jedynie na zliczeniu i porównaniu ilości rekordów, które miały dane wartości danego atrybutu.
Interpretacja tych wizualizacji nie jest łatwa.
- Ustawiamy nazwę, typ oraz folder alertu
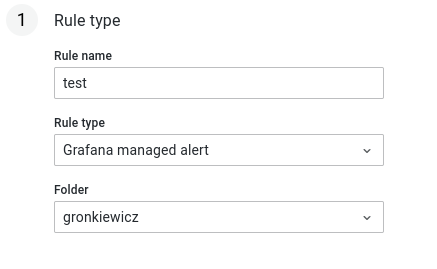
- Ustawiamy query na podstawie którego chcemy alertować
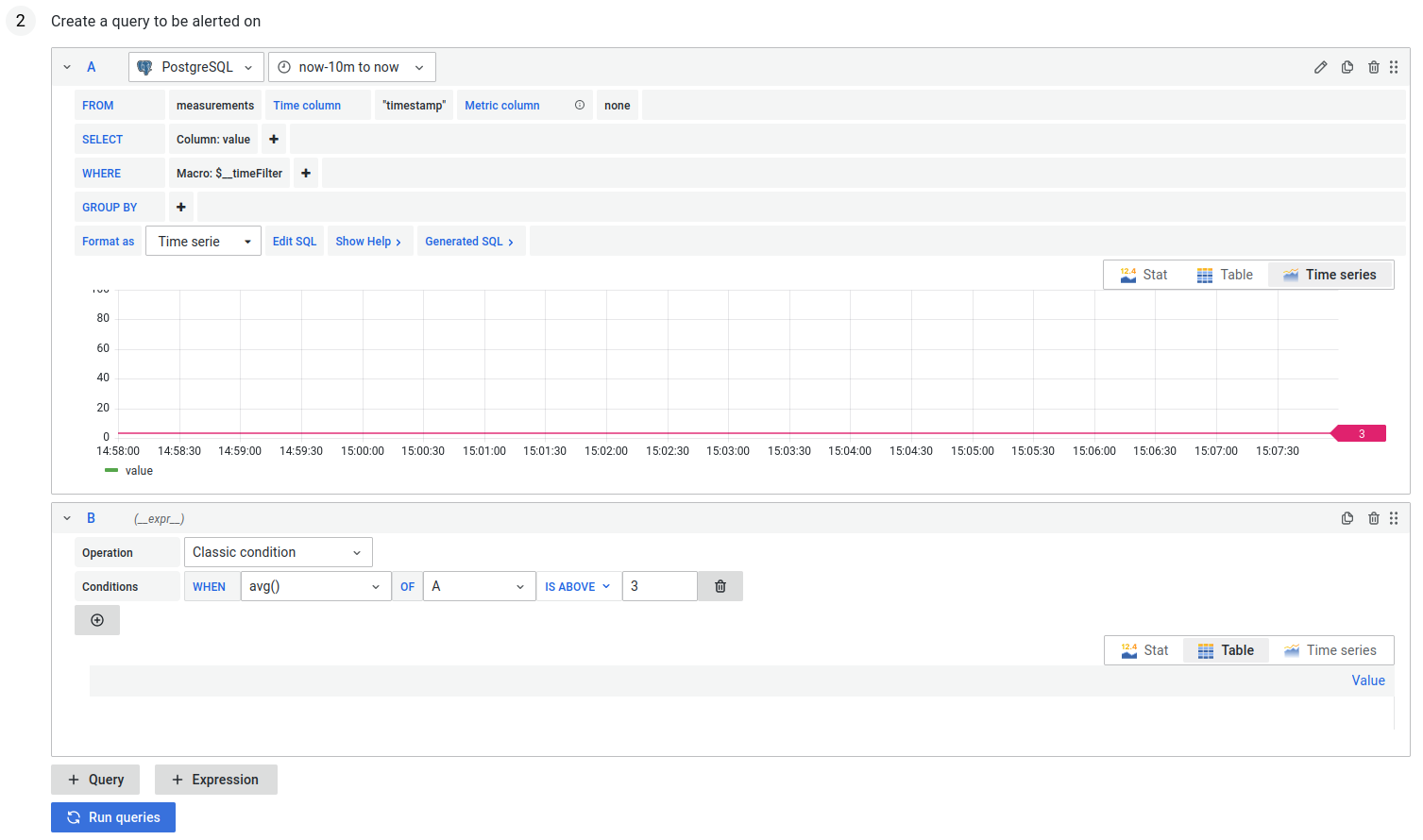
- Ustawiamy warunki przy jakich wysyłamy alert
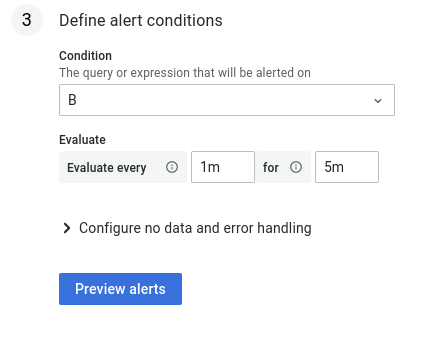
- Opisujemy treść alertu
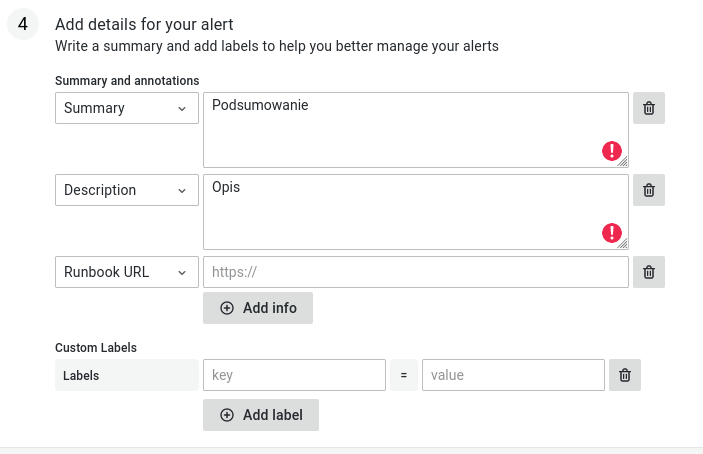




W celu krótkoterminowego przewidywania temperatury urządzeń użyto metryk bezpośrednio dotyczących samego urządzenia, tzn. zawierających prefiks node. Przewidywania prowadzone były metodą OLS (Ordinary Least Squares), która daje zadowalające wyniki.
W tym wypadku przewidujemy dane, które mają bardzo silny trend (nigdy nie spadają, zawsze są wzrostowe). Podobnie jak poprzednio użyta została metoda OLS, która pozwoliła na przewidzenie użytego czasu procesora w następnych kilku minutach (a co za tym idzie — procenta użycia CPU).