Video: https://www.youtube.com/watch?v=5lsmGWtxnKA
Slides: https://docs.google.com/presentation/d/1_vlBepZ4kMWqv9J0_4SYMSYcOaoxCSGW1HLvo_UlBZQ/edit?usp=sharing
Paper: https://arxiv.org/abs/2002.05709
Annoting data is tedious and costly. Meanwhile, unlabeled data is widely available or can be collected with little effort. Self-supervised learning aims to automate the labeling process and leverage the abundance of unlabeled data.
One approach among these is contrastive learning. Constrastive learning attempts to teach a model to distinguish similar and different categories. The main idea is: if 2 images are similar, then their visual representations in the feature space should be close to each other. Enforcing the similarity between these representations should help the model learn high-level distinctive features of each category.
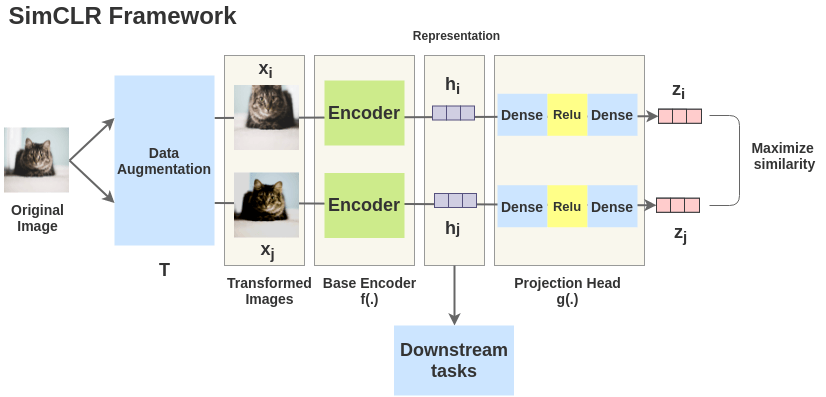
SimCLR is a simple framework for contrastive learning of visual representation.
2 random transformations from a pool are applied on the same image. This gives a pair of 2 augmented versions, or the positive pair.
The positive pair is mixed with other negative samples.
The goal is to encourage the representations of the positive pair to be similar, while mamimizing the difference with the other negative samples.