Our Team Need to Image Crawling service for image learning.
So I Designed crawling micro service architecture like this
- user manually run Lambda Function named
trigger triggerfunction trigger multiplecrawl-corewith different arguments(2008 ~ 2018, 11years with same keyword)crawl-corefunction crawl images from google, and then upload images tocrawl-google-devs3 bucket- If
crawl-corefunction ended then PutItem into DynamoDB namedcrawl-google-dev - Every 1 minute, Cloud watch event rule automatically triggered by reservation
- The Cloud watch trigger to run
crawl-slacklambda function notifylambda function check ifcrawl-google-devDynamoDB has same 11 keyword (2008 ~ 2018, 11years)- If
crawl-google-devDynamoDB has 11 same keyword(2008 ~ 2018, 11years) thennotifylambda function remove keyword fromcrawl-google-devDynamoDB and then inform to slack

# Clone Github Repo
$ git clone https://github.com/philographer/crawl-google.git
# Install Serverless Framework
$ npm install -g serverless
# !!!!!!!!!!!!!!!!!Watch the video: https://www.youtube.com/watch?v=HSd9uYj2LJA!!!!!!!!!!!!!!!!!
$ serverless config credentials --provider aws --key [YOUR-ACCESS-KEY] --secret [YOUR-SECRET-KEY]
# Change Working Directory
$ cd crawl-google
# Install dependency
$ npm run dependency
# Deploy your Code
$ npm run deploy

// Test Event name is `TriggerTest` and Insert Text like below. And Click `생성`
{
"body": "text=김치&token=XYNDWH9iaoLCsSmHyigWB6wm"
}
-
Then Select
TriggerTestAnd Click테스트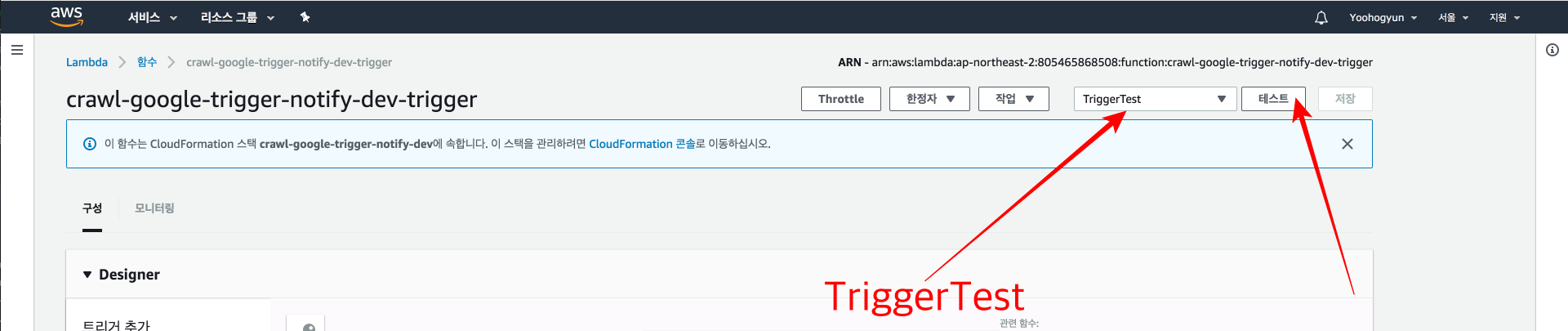
-
Wait a 5minutes Then, Click
S3on AWS Console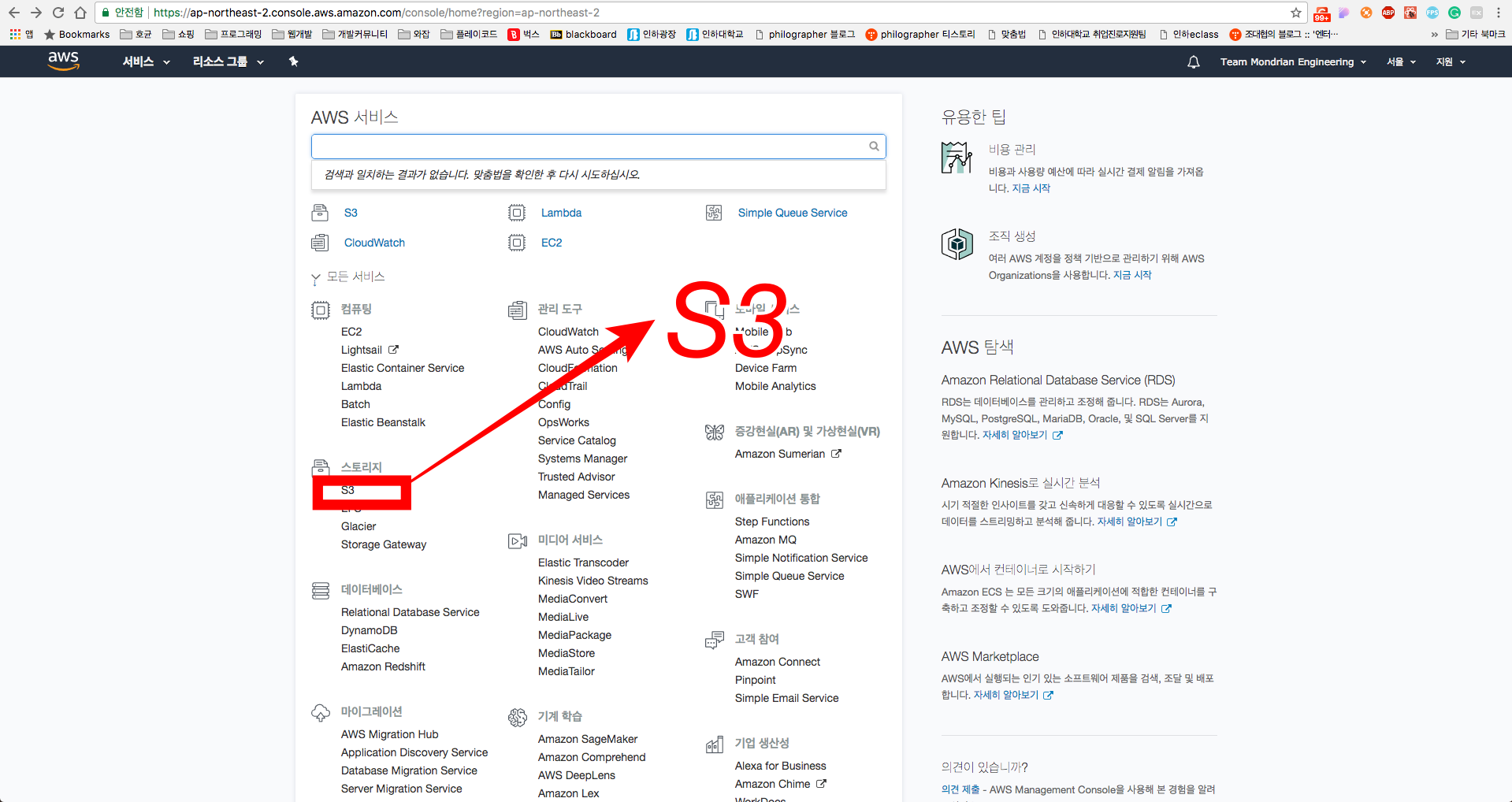
-
Then, Click
crawl-google-devBucket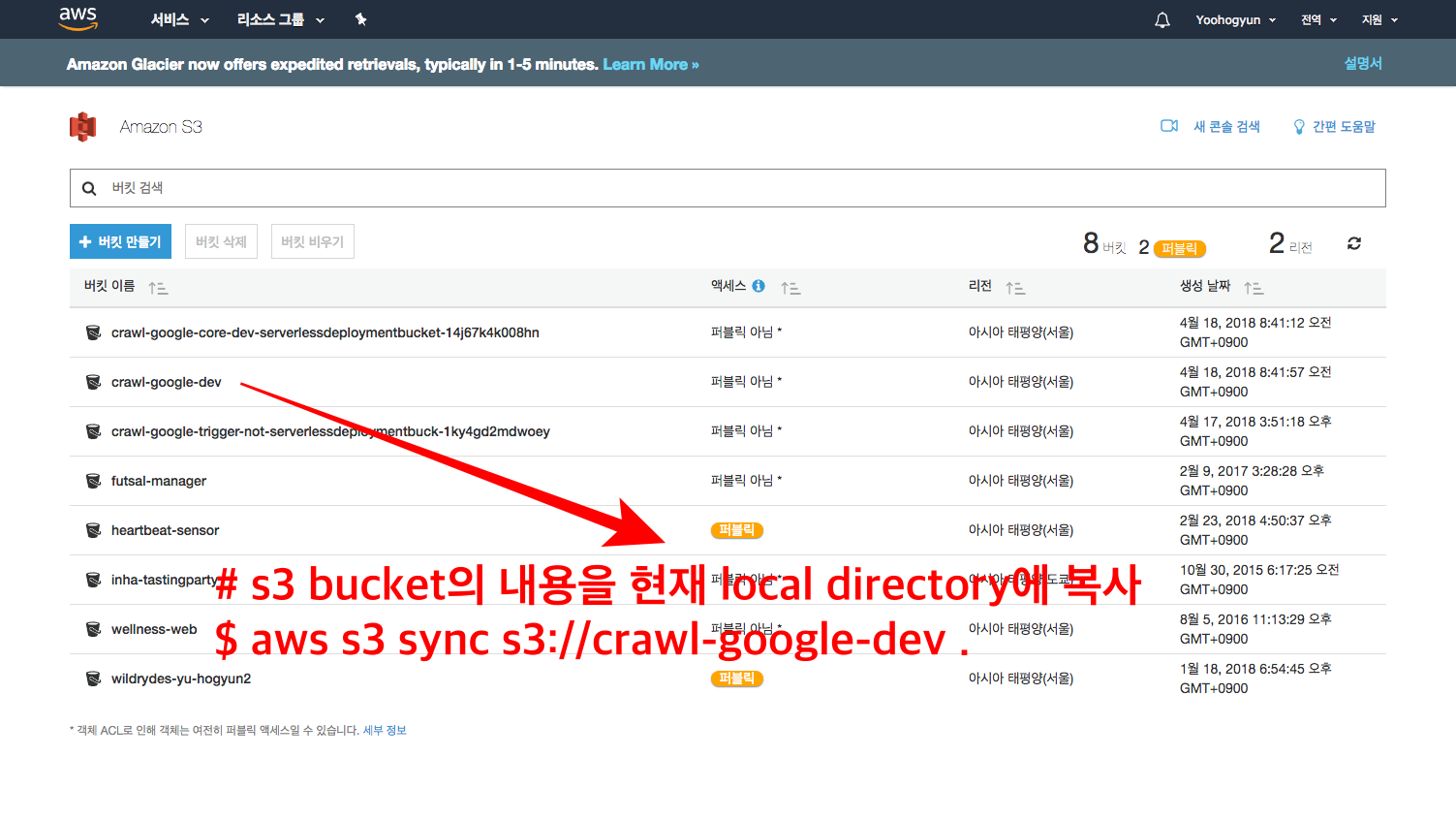
-
You can see crawled image.
-
You can sync Bucket with local directory




## ref1. https://docs.aws.amazon.com/cli/latest/reference/s3/sync.html
## ref2. https://docs.aws.amazon.com/ko_kr/cli/latest/userguide/installing.html
# AWS Cli Install
$ pip install awscli --upgrade --user
# s3의 Bucket을 현재 local directory에 다운로드
$ aws s3 sync s3://crawl-google-dev .
# 현재 local directory의 내용을 Bucket으로 업로드 (없는 내용은 지움, local에서 삭제한 이미지는 Bucket에서도 삭제)
$ aws s3 sync . s3://crawl-google-dev --delete