CREST is a machine-readable format/schema that is created to help researchers who work on causal/counterfactual relation extraction and commonsense causal reasoning, to use and leverage the scattered data resources around these topics more easily. CREST-formatted data are stored as pandas DataFrame.
- Clone this repository and go to the
/CRESTdirectory. - Install the requirements:
pip install -r requirements.txt - Download spaCy's model:
python -m spacy download en_core_web_sm - Run the
/crest/convert.py:python convert.py -i: printing the full list of currently supported datasetspython convert.py [DATASET_ID_0] ... [DATASET_ID_n] [OUTPUT_FILE_NAME]DATASET_ID_*: id of a dataset.OUTPUT_FILE_NAME: name of the output file that should be in.xlsxformat
- Examples:
- Converting datasets
1and2:python convert.py 1 2 output.xlsx - Converting dataset
5:python convert.py 5 output.xlsx
- Converting datasets
The excel file of all converted datasets:
crest_v2.xlsx
- PDTB is not available in this file due to copyright. However, you can still use CREST to convert this dataset if you have access to PDTB.
Each relation in a CREST-formatted DataFrame has the following fields/values:
original_id: the id of a relation in the original dataset, if such an id exists.span1: a list of strings of the first span/argument of the relation.span2: a list of strings of the second span/argument of the relationsignal: a list of strings of signals/markers of the relation in context, if any.context: a text string of the context in which the relation appears.idx: indices ofspan1,span2, andsignaltokens/spans in context stored in 3 lines, each line in the form ofspan_type start_1:end_1 ... start_n:end_n. For example, ifspan1has multiple tokens/spans withstart:endindices2:5and10:13, respectively,span1's line value inidxisspan1 2:5 10:13. Indices are sorted based on the start indexes of tokens/spans.label: label of the relation,0: non-causal,1: causaldirection: direction between span1 and span2.0: span1 => span2,1: span1 <= span2,-1: not-specifiedsource: id of the source dataset (idsare listed in a table below)split:0: train,1: dev,2: test. This is the split to which the relation belongs in the original dataset. If there is no split specified for a relation in the original dataset, we assign the relation to thetrainsplit by default.
Note: The reason we save a list of strings instead of a single string for span1, span2, and signal is that these text spans may contain multiple non-consecutive sub-spans in context.
List of data resources already converted to CREST format:
| Id | Data resource | Samples | Causal | Non-causal | Document | Year |
|---|---|---|---|---|---|---|
| 1 | SemEval 2007 Task 4 | 1,529 | 114 | 1,415 | Paper | 2007 |
| 2 | SemEval 2010 Task 8 | 10,717 | 1,331 | 9,386 | Paper | 2010 |
| 3 | EventCausality | 583 | 583 | - | Paper | 2011 |
| 4 | Causal-TimeBank | 318 | 318 | - | Paper | 2014 |
| 5 | EventStoryLine v1.5 | 2,608 | 2,608 | - | Paper | 2016 |
| 6 | CaTeRS | 2,502 | 308 | 2,194 | Paper | 2016 |
| 7 | BECauSE v2.1 |
729 | 554 | 175 | Paper | 2017 |
| 8 | Choice of Plausible Alternatives (COPA) | 2,000 | 1,000 | 1,000 | Paper | 2011 |
| 9 | The Penn Discourse Treebank (PDTB) 3.0 |
7,991 | 7,991 | - | Manual | 2019 |
| 10 | BioCause Corpus | 844 | 844 | - | Paper | 2013 |
| 11 | Temporal and Causal Reasoning (TCR) | 172 | 172 | - | Paper | 2018 |
| 12 | Benchmark Corpus for Adverse Drug Effects | 5,671 | 5,671 | - | Paper | 2012 |
| 13 | SemEval 2020 Task 5 |
5,501 | 5,501 | - | Paper | 2020 |
![]() Counterfactual Relations
Counterfactual Relations
We provide helper methods to convert CREST-formatted data to popular formats and annotation schemes, mainly formats that are used across relation extraction/classification tasks. In the following, there is a list of formats for which we have already developed CREST converter methods:
brat: we have provided helper methods for two-way conversion of CREST data frames to brat (see example here). brat is a popular web-based annotation tool that has been used for a variety of relation extraction NLP tasks. We use brat for two main reasons: 1) better visualization of causal and non-causal relations and their arguments, and 2) modifying annotations if needed and adding new annotations to provided context. In the following, there is a sample of a converted version of CREST-formatted relation to brat (example is taken from CaTeRS dataset):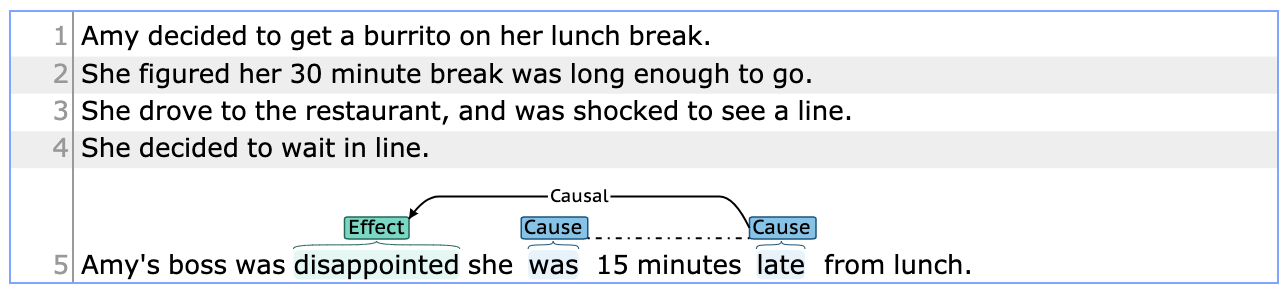
TACRED: TACRED is a large-scale relation extraction dataset. We convert samples from CREST to TACRED since TACRED-formatted data can be easily used as input to many transformers-based language models (e.g. for Relation Classification/Extraction). You can find an example of converting CREST-formatted data to TACRED in this notebook.

- Are there any related datasets you don’t see in the list? Let us know or feel free to submit a
Pull Request (PR), we actively check the PRs and appreciate it☺️ - Is there a well-known or widely-used machine-readable format you think can be added? We can add the helper methods for conversion or we appreciate PRs.
For now, please cite our arXiv paper:
@article{hosseini2021predicting,
title={Predicting Directionality in Causal Relations in Text},
author={Hosseini, Pedram and Broniatowski, David A and Diab, Mona},
journal={arXiv preprint arXiv:2103.13606},
year={2021}
}