A scalable admin ui for spider service
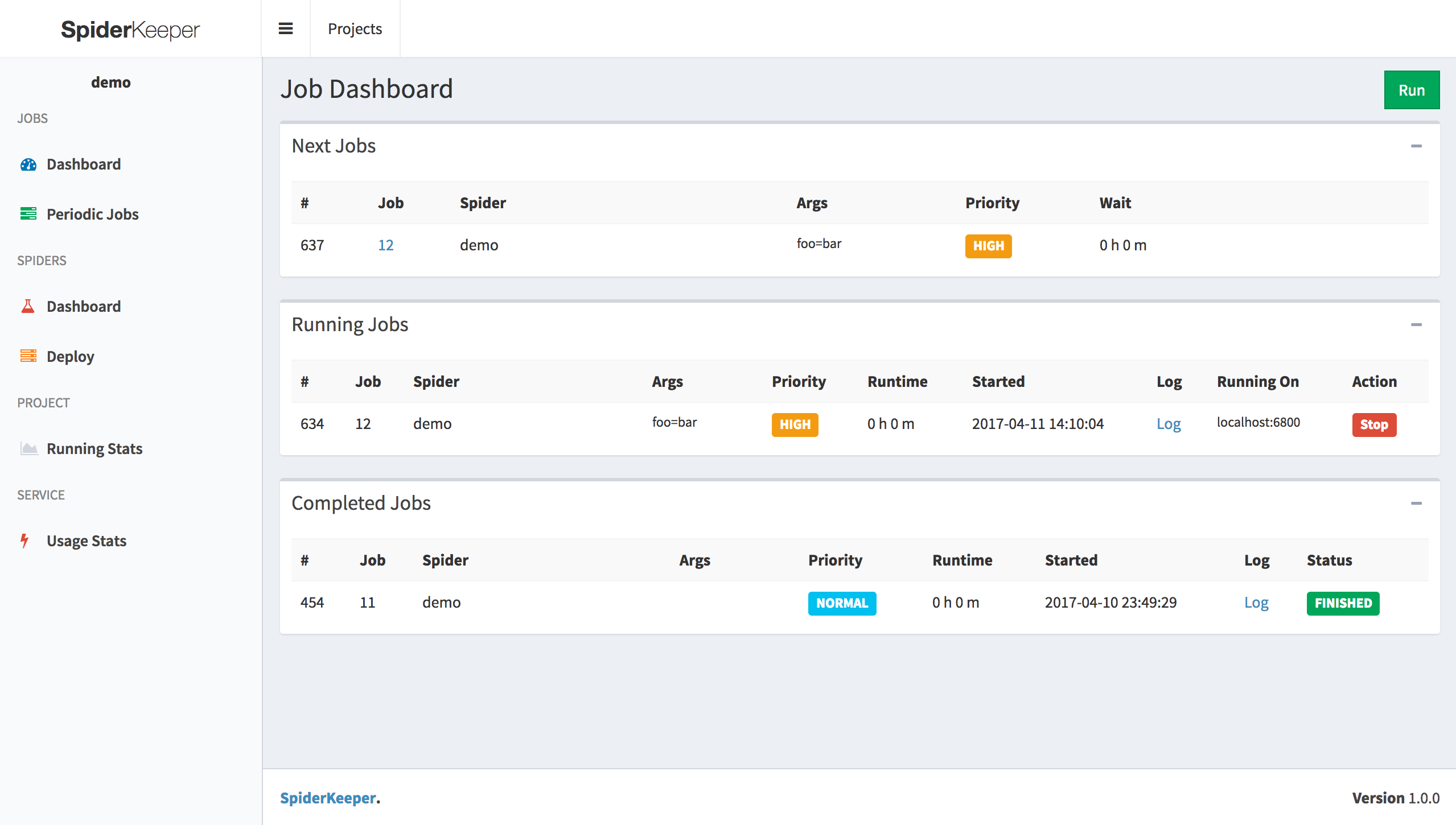
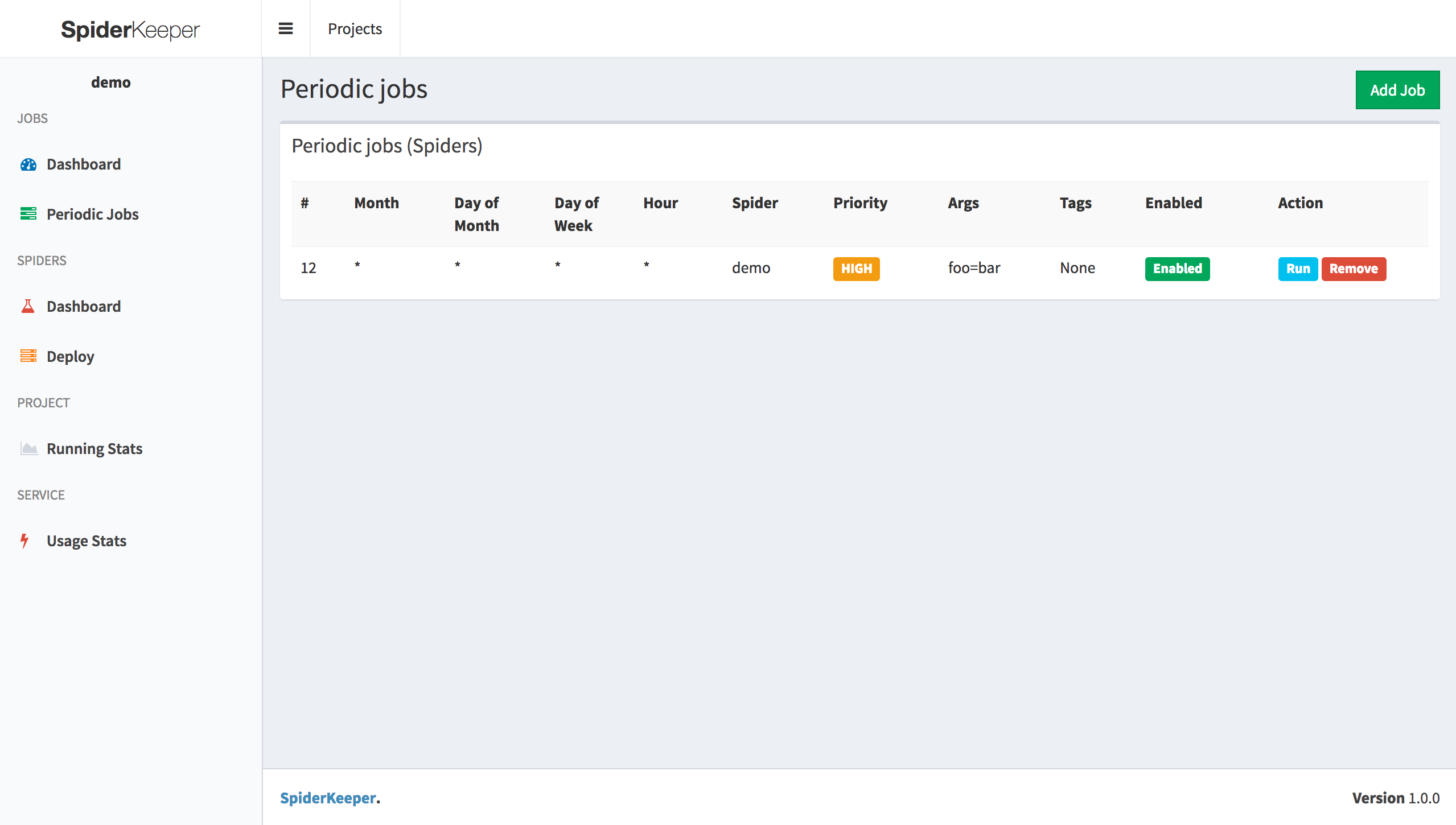
- Manage your spiders from a dashboard. Schedule them to run automatically
- With a single click deploy the scrapy project
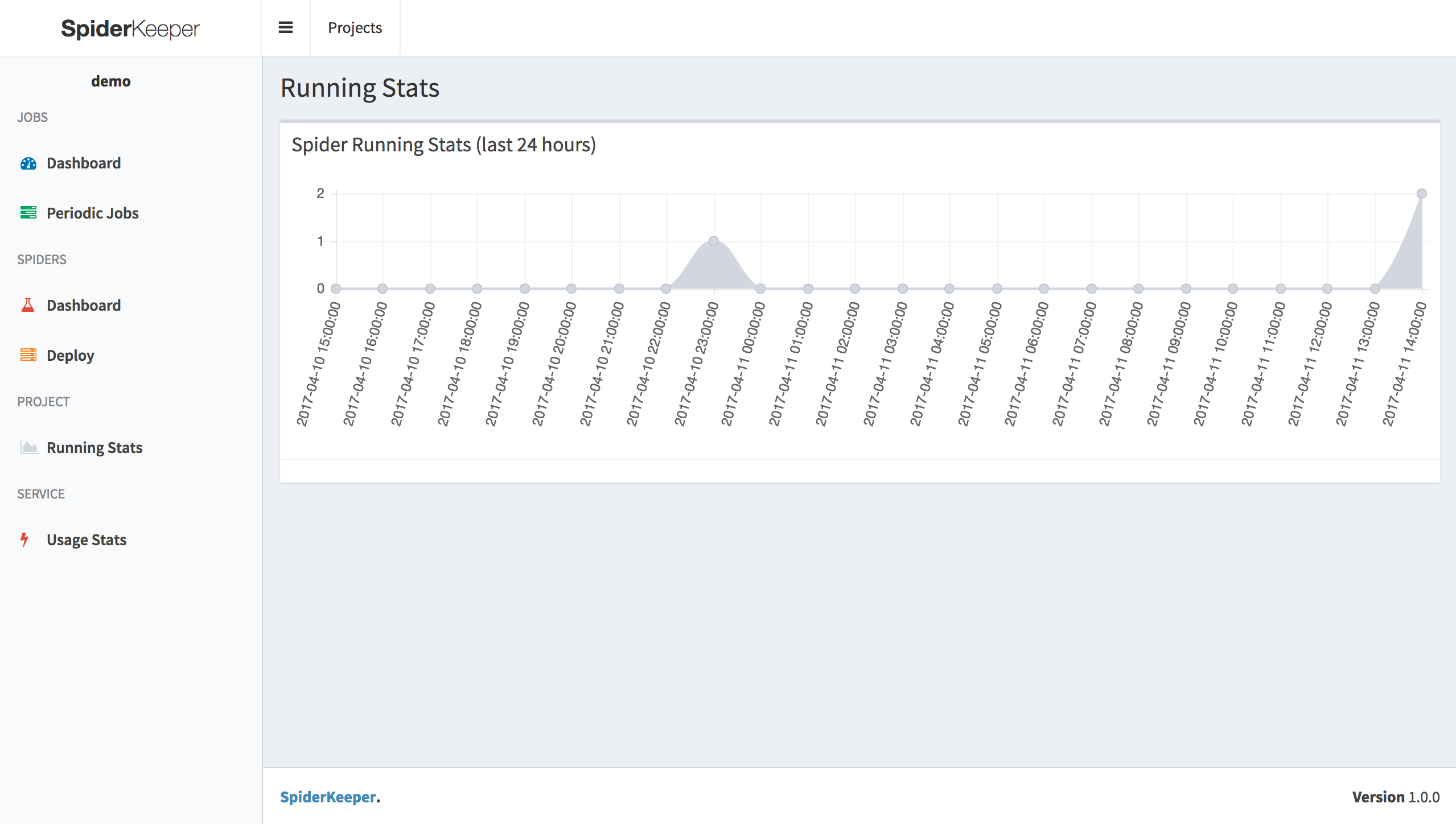
- Show spider running stats
- Provide api
Current Support spider service
pip install spiderkeeper
spiderkeeper [options]
Options:
-h, --help show this help message and exit
--host=HOST host, default:0.0.0.0
--port=PORT port, default:5000
--username=USERNAME basic auth username ,default: admin
--password=PASSWORD basic auth password ,default: admin
--type=SERVER_TYPE access spider server type, default: scrapyd
--server=SERVERS servers, default: ['http://localhost:6800']
--database-url=DATABASE_URL
SpiderKeeper metadata database default: sqlite:////home/souche/SpiderKeeper.db
--no-auth disable basic auth
-v, --verbose log level
example:
spiderkeeper --server=http://localhost:6800
Visit:
- web ui : http://localhost:5000
1. Create Project
2. Use [scrapyd-client](https://github.com/scrapy/scrapyd-client) to generate egg file
scrapyd-deploy --build-egg output.egg
2. upload egg file (make sure you started scrapyd server)
3. Done & Enjoy it
- api swagger: http://localhost:5000/api.html
- Job dashboard support filter
- User Authentication
- Collect & Show scrapy crawl stats
- Optimize load balancing
We use SemVer for versioning. For the versions available, see the tags on this repository.
- Initial work - DormyMo
See also the list of contributors who participated in this project.
This project is licensed under the MIT License - see the LICENSE.md file for details
Contributions are welcomed!