Pytorch Implementation of PiCANet: Learning Pixel-wise Contextual Attention for Saliency Detection
- Issue#9
- Conv3d version is deleted.


- batchsize 1
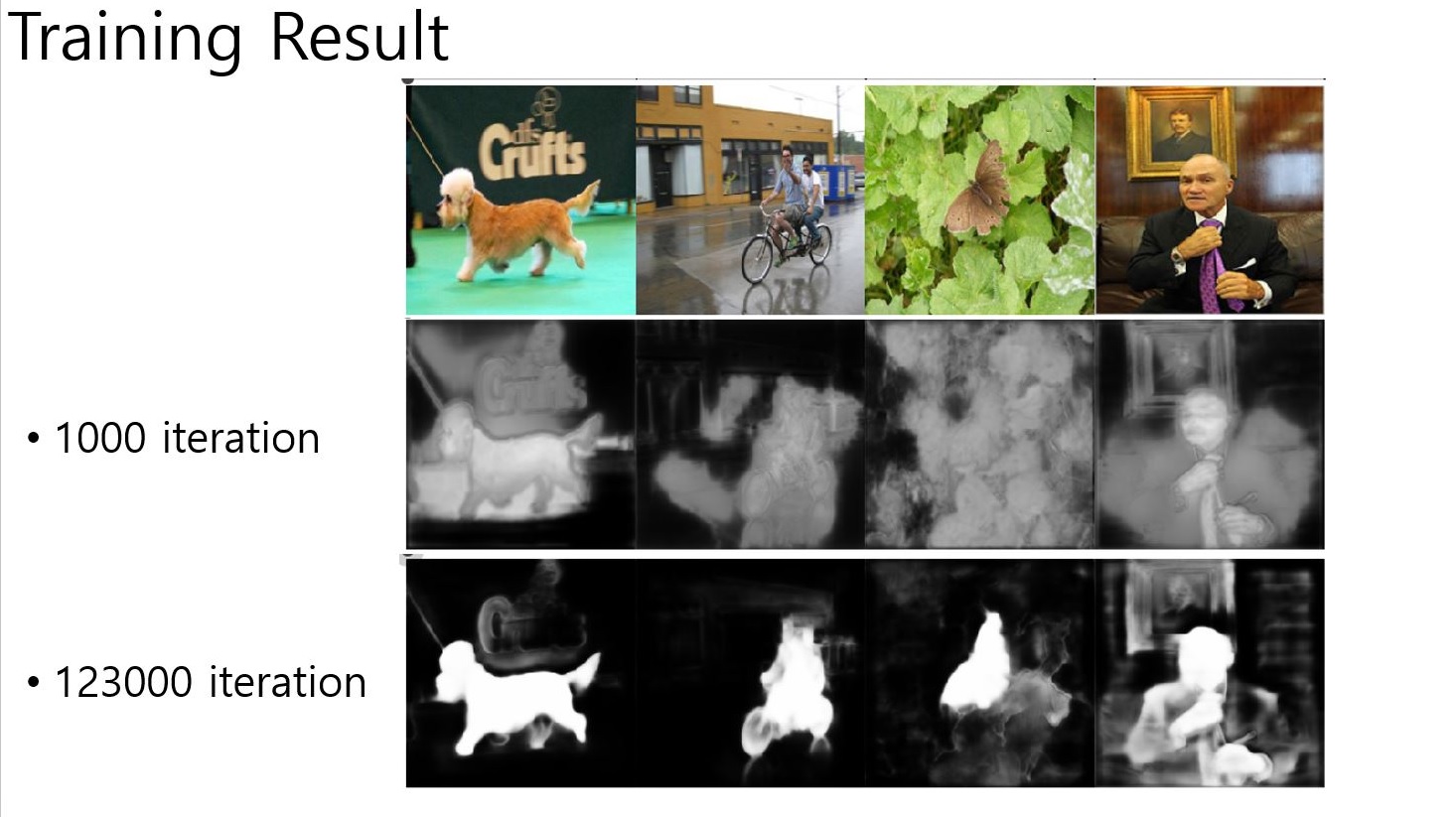
- batchsize 4
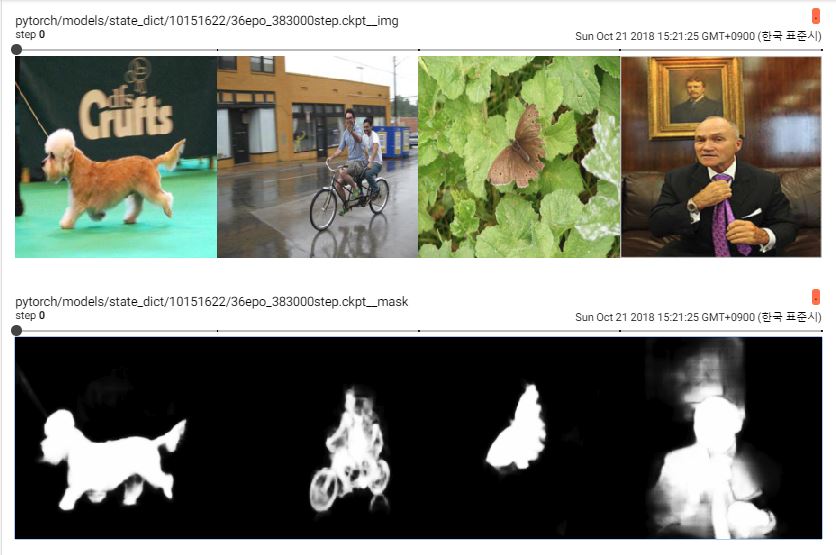


batchsize:4
| Step | Value | Threshold | MAE |
|---|---|---|---|
| 214000 | 0.8520 | 0.6980 | 0.0504 |
| 259000 | 0.8518 | 0.6510 | 0.0512 |
| 275000 | 0.8533 | 0.6627 | 0.0536 |
| 281000 | 0.8540 | 0.7451 | 0.0515 |
| 307000 | 0.8518 | 0.8078 | 0.0523 |
| 383000 | 0.8546 | 0.6627 | 0.0532 |
| 399000 | 0.8561 | 0.7882 | 0.0523 |
| 400000 | 0.8544 | 0.7804 | 0.0512 |
| 408000 | 0.8535 | 0.5922 | 0.0550 |
| 410000 | 0.8518 | 0.7882 | 0.0507 |
Pillow==4.3.0
pytorch==0.4.1
tensorboardX==1.1
torchvision==0.2.1
numpy==1.14.2
S/W
Windows 10
CUDA 9.0
cudnn 7.0
python 3.5
H/W
AMD Ryzen 1700
Nvidia gtx 1080ti
32GB RAM
- For training,
- Please check the Detailed Guideline if you want to know the dataset structure.
usage: train.py [-h] [--load LOAD] --dataset DATASET [--cuda CUDA]
[--batch_size BATCH_SIZE] [--epoch EPOCH] [-lr LEARNING_RATE]
[--lr_decay LR_DECAY] [--decay_step DECAY_STEP]
[--display_freq DISPLAY_FREQ]
optional arguments:
-h, --help show this help message and exit
--load LOAD Directory of pre-trained model, you can download at
https://drive.google.com/file/d/109a0hLftRZ5at5hwpteRfO1A6xLzf8Na/view?usp=sharing
None --> Do not use pre-trained model. Training will start from random initialized model
--dataset DATASET Directory of your Dataset
--cuda CUDA 'cuda' for cuda, 'cpu' for cpu, default = cuda
--batch_size BATCH_SIZE
batchsize, default = 1
--epoch EPOCH # of epochs. default = 20
-lr LEARNING_RATE, --learning_rate LEARNING_RATE
learning_rate. default = 0.001
--lr_decay LR_DECAY Learning rate decrease by lr_decay time per decay_step, default = 0.1
--decay_step DECAY_STEP
Learning rate decrease by lr_decay time per decay_step, default = 7000
--display_freq DISPLAY_FREQ
display_freq to display result image on Tensorboard
- For inference,
- dataset should contain image files only.
- You do not need
masksorimagesfolder. If you want to run with PairDataset structure, use argument like
--dataset [DATAROOT]/images - You should specify either logdir (for TensorBoard output) or save_dir (for Image file output).
- If you use logdir, you can see the whole images by run tensorboard with
--samples_per_plugin images=0option
usage: image_test.py [-h] [--model_dir MODEL_DIR] --dataset DATASET
[--cuda CUDA] [--batch_size BATCH_SIZE] [--logdir LOGDIR]
[--save_dir SAVE_DIR]
optional arguments:
-h, --help show this help message and exit
--model_dir MODEL_DIR
Directory of pre-trained model, you can download at
https://drive.google.com/drive/folders/1s4M-_SnCPMj_2rsMkSy3pLnLQcgRakAe?usp=sharing
--dataset DATASET Directory of your test_image ""folder""
--cuda CUDA cuda for cuda, cpu for cpu, default = cuda
--batch_size BATCH_SIZE
batchsize, default = 4
--logdir LOGDIR logdir, log on tensorboard
--save_dir SAVE_DIR save result images as .jpg file. If None -> Not save
- To report score,
- dataset should contain
masksandimagesfolder. - You should specify logdir to get PR-Curve.
- The Scores will be printed out on your stdout.
- You should have model files below the model_dir.
- Only supports model files named like "[N]epo_[M]step.ckpt" format.
usage: measure_test.py [-h] --model_dir MODEL_DIR --dataset DATASET
[--cuda CUDA] [--batch_size BATCH_SIZE]
[--logdir LOGDIR] [--which_iter WHICH_ITER]
[--cont CONT] [--step STEP]
optional arguments:
-h, --help show this help message and exit
--model_dir MODEL_DIR
Directory of folder which contains pre-trained models, you can download at
https://drive.google.com/drive/folders/1s4M-_SnCPMj_2rsMkSy3pLnLQcgRakAe?usp=sharing
--dataset DATASET Directory of your test_image ""folder""
--cuda CUDA cuda for cuda, cpu for cpu, default = cuda
--batch_size BATCH_SIZE
batchsize, default = 4
--logdir LOGDIR logdir, log on tensorboard
--which_iter WHICH_ITER
Specific Iter to measure
--cont CONT Measure scores from this iter
--step STEP Measure scores per this iter step
You can download pre-trained models from https://drive.google.com/drive/folders/1s4M-_SnCPMj_2rsMkSy3pLnLQcgRakAe?usp=sharing
- You can use CustomDataset.
- Your custom dataset should contain
images,masksfolder.- In each folder, the filenames should be matched.
- eg.
images/a.jpg masks/a.jpg
You can download dataset from http://saliencydetection.net/duts/#outline-container-orgab269ec.
- Caution: You should check the dataset's Image and GT are matched or not. (ex. # of images, name, ...)
- You can match the file names and automatically remove un-matched datas by using
DUTSDataset.arrange(self)method - Please rename the folders to
imagesandmasks.
"models/state_dict//<#epo_#step>.ckpt"
- The step is accumulated step from epoch 0.