Fully functional application that demonstrates semantic search and semantic search + GenAI with a 150K product reference dataset.
The dataset is a CSV file that has the following record format
| id | name | title | ean | short_description | img_high | img_low | img_500x500 | img_thumb | date_released | supplier | price |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 3920564 | 56ABCD | Some Title | ['0095205603217'] | Some Short Description | http://someurl.jpg | http://someurl.jpg | http://someurl.jpg | http://someurl.jpg | 2009-12-10T00:00:00Z | Some Supplier | 19.99 |
The following technologies were used to build this demo
- Pinecone - Python Library
- Pinecone - Node.js Library
- LlamaIndex
- Llama Hub - Paged CSV Loader
- OpenAI - Python Library
- OpenAI - Node.js Library


- Load CSV into LlamaIndex + Generate meta-data for each record
- Generate vector embeddings for each record
- Persist batches of vector embeddings into Pinecone
- User provides search query: "Samgsung"
- Application generates vector embedding from query
- Application queries pinecone for most similar vectors - Semantic
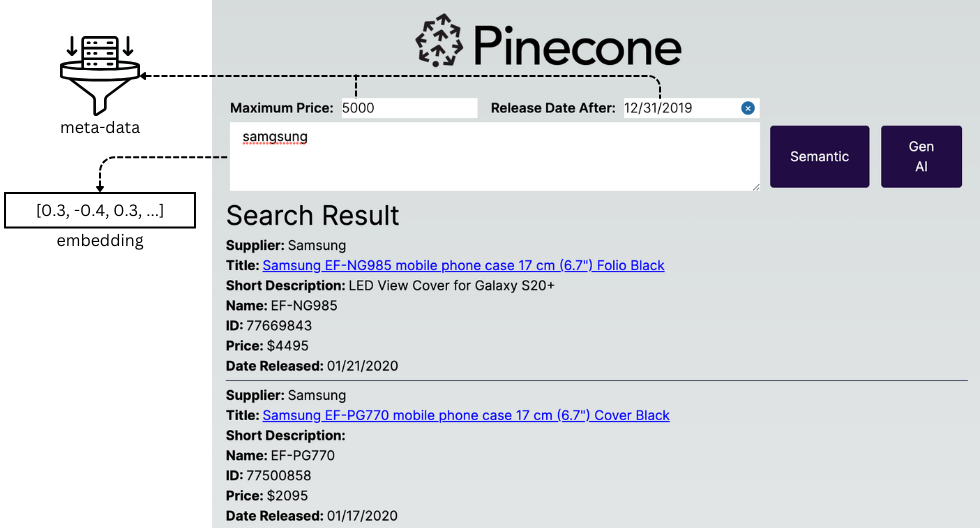
- Application asks LLM to generate a response - GenAI



There are 2 main components 1) Data Pipeline and 2 ) Application. The data pipeline is packaged as a notebook and the Application is a next.js based React application.
- python 3.11+ or later installed on your system.
- Ability to run Jupyter notebook files. VS code is highly recommended.
- A "standard" or "enterprise" plan Pinecone account because this dataset exceeds the free plan limit.
-
[OPTIONAL] Create a
.envfile that has the following entriesPINECONE_API_KEY="YOUR_API_KEY" PINECONE_ENVIRONMENT="YOUR_ENVIRONMENT" PINECONE_INDEX_NAME="YOUR_INDEX_NAME" OPENAI_API_KEY="YOUR_OPEN_API_KEY" -
Run the steps in this data pipeline notebook.
You must have node.js 16.14 or later installed on your system.
- Open a terminal window
- Run:
cd ./application - Run:
npm install - Run:
npm run dev