DESIGN AND IMPLEMENTATION OF A MACHINE LEARNING PLATFORM
2019-minicourse-submarine slide, doc
![]()
Apache Submarine is a unified AI platform which allows engineers and data scientists to run Machine Learning and Deep Learning workload in distributed cluster.
Goals of Submarine:
- It allows jobs easy access data/models in HDFS and other storages.
- Can launch services to serve TensorFlow/PyTorch models.
- Support run distributed TensorFlow jobs with simple configs.
- Support run user-specified Docker images.
- Support specify GPU and other resources.
- Support launch TensorBoard for training jobs if user specified.
- Support customized DNS name for roles (like TensorBoard.$user.$domain:6006)
- Maven 3.3 or later ( 3.6.2 is known to fail, see SUBMARINE-273 )
- JDK 1.8
git clone https://github.com/apache/submarine.git
cd submarine
mvn clean install package -DskipTests
cd dev-support/mini-submarine
./build_mini-submarine.sh
docker pull hadoopsubmarine/mini-submarine:0.3.0-SNAPSHOT
docker run -it -h submarine-dev --net=bridge --privileged -P local/mini-submarine:0.3.0-SNAPSHOT /bin/bash
# In the container, use root user to bootstrap hdfs and yarn
/tmp/hadoop-config/bootstrap.sh
su yarn
# Run distributed training on hadoop
cd && cd submarine && ./run_submarine_mnist_tony.sh


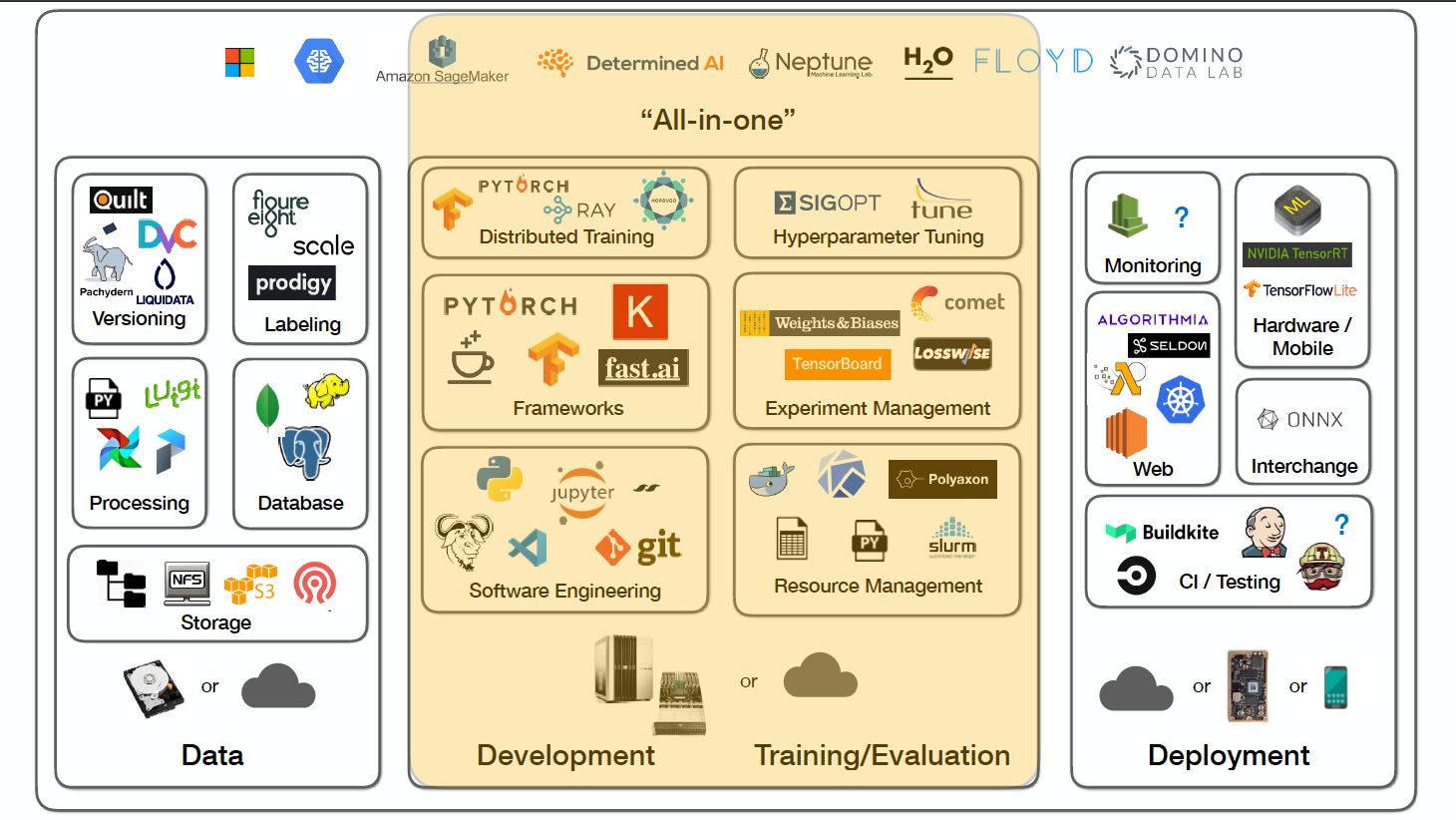
After this tutorial, you will know :
Apache Submarine - is Cloud Native Machine Learning Platform
Apache airflow - a platform to programmatically author, schedule, and monitor workflows.
kaggle - an online community of data scientists and machine learners. Kaggle allows users to find and publish data sets, explore and build models in a web-based data-science environment, work with other data scientists and machine learning engineers, and enter competitions to solve data science challenges.
jupyter notebook - an open-source web application that allows you to create and share documents that contain live code, equations, visualizations and narrative text
mlflow - An open source platform for the machine learning lifecycle
- Ubuntu >= 16.04
- Docker
- Docker-compose
- memory >= 5G
sudo apt install docker-compose # install docker-compose
sudo apt-get install docker.io # install docker
service docker statusHouse Prices: Advanced Regression Techniques
cd airflow
vim kaggle.json
# {"username":"<Kaggle account username>", "key":"<API key>"}sudo docker-compose buildsudo docker-compose -f docker-compose.yml up- mlflow : localhost:5000
- jupyter notebook : localhost:7000
- airflow : localhost:8080





# open ./dags/src/training.py and tune parameters
params = {
"colsample_bytree": 0.4603,
"gamma": 0.0468,
"learning_rate": 0.05,
"max_depth": 20,
"min_child_weight": 2,
"n_estimators": 2200,
"reg_alpha": 0.4640,
"reg_lambda": 0.8571,
"subsample": 0.5213,
"random_state": 7,
"nthread": -1
}