by NeuLab @ CMU LTI, and other contributors

compare-mt (for "compare my text") is a program to compare the output of multiple systems for language generation,
including machine translation, summarization, dialog response generation, etc.
To use it you need to have, in text format, a "correct" reference, and the output of two different systems.
Based on this, compare-mt will run a number of analyses that attempt to pick out salient differences between
the systems, which will make it easier for you to figure out what things one system is doing better than another.
First, you need to install the package:
# Requirements
pip install -r requirements.txt
# Install the package
python setup.py installThen, as an example, you can run this over two included system outputs.
compare-mt --output_directory output/ example/ted.ref.eng example/ted.sys1.eng example/ted.sys2.engThis will output some statistics to the command line, and also write a formatted HTML report to output/.
Here, system 1 and system 2 are the baseline phrase-based and neural Slovak-English systems from our
EMNLP 2018 paper. This will print out a number of statistics including:
- Aggregate Scores: A report on overall BLEU scores and length ratios
- Word Accuracy Analysis: A report on the F-measure of words by frequency bucket
- Sentence Bucket Analysis: Bucket sentences by various statistics (e.g. sentence BLEU, length difference with the reference, overall length), and calculate statistics by bucket (e.g. number of sentences, BLEU score per bucket)
- N-gram Difference Analysis: Calculate which n-grams one system is consistently translating better
- Sentence Examples: Find sentences where one system is doing better than the other according to sentence BLEU
You can see an example of running this analysis (as well as the more advanced analysis below) either through a generated HTML report here, or in the following narrated video:
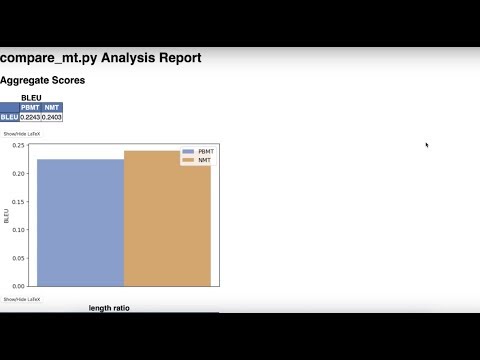
To summarize the results that immediately stick out from the basic analysis:
- From the aggregate scores we can see that the BLEU of neural MT is higher, but its sentences are slightly shorter.
- From the word accuracy analysis we can see that phrase-based MT is better at low-frequency words.
- From the sentence bucket analysis we can see that neural seems to be better at translating shorter sentences.
- From the n-gram difference analysis we can see that there are a few words that neural MT is not good at but phrase based MT gets right (e.g. "phantom"), while there are a few long phrases that neural MT does better with (e.g. "going to show you").
If you run on your own data, you might be able to find more interesting things about your own systems. Try comparing your modified system with your baseline and seeing what you find!
There are many options that can be used to do different types of analysis.
If you want to find all the different types of analysis supported, the most comprehensive way to do so is by
taking a look at compare-mt, which is documented relatively well and should give examples.
We do highlight a few particularly useful and common types of analysis below:
The script allows you to perform statistical significance tests for scores based on bootstrap resampling. You can set the number of samplings manually. Here is an example using the example data:
compare-mt example/ted.ref.eng example/ted.sys1.eng example/ted.sys2.eng --compare_scores score_type=bleu,bootstrap=1000,prob_thresh=0.05One useful piece of analysis is the "word accuracy by frequency" analysis. By default this frequency is the frequency
in the test set, but arguably it is more informative to know accuracy by frequency in the training set as this
demonstrates the models' robustness to words they haven't seen much, or at all, in the training data. To change the
corpus used to calculate word frequency and use the training set (or some other set), you can set the freq_corpus_file
option to the appropriate corpus.
compare-mt example/ted.ref.eng example/ted.sys1.eng example/ted.sys2.eng
--compare_word_accuracies bucket_type=freq,freq_corpus_file=example/ted.train.engIn addition, because training sets may be very big, you can also calculate the counts on the file beforehand,
python scripts/count.py < example/ted.train.eng > example/ted.train.countsand then use these counts directly to improve efficiency.
compare-mt example/ted.ref.eng example/ted.sys1.eng example/ted.sys2.eng
--compare_word_accuracies bucket_type=freq,freq_count_file=example/ted.train.countsIf you're interested in performing aggregate analysis over labels for each word/sentence instead of the words/sentences themselves, it is possible to do so. As an example, we've included POS tags for each of the example outputs. You can use these in aggregate analysis, or n-gram-based analysis. The following gives an example:
compare-mt example/ted.ref.eng example/ted.sys1.eng example/ted.sys2.eng
--compare_word_accuracies bucket_type=label,ref_labels=example/ted.ref.eng.tag,out_labels="example/ted.sys1.eng.tag;example/ted.sys2.eng.tag",label_set=CC+DT+IN+JJ+NN+NNP+NNS+PRP+RB+TO+VB+VBP+VBZ
--compare_ngrams compare_type=match,ref_labels=example/ted.ref.eng.tag,out_labels="example/ted.sys1.eng.tag;example/ted.sys2.eng.tag"This will calculate word accuracies and n-gram matches by POS bucket, and allows you to see things like the fact that the phrase-based MT system is better at translating content words such as nouns and verbs, while neural MT is doing better at translating function words.
We also give an example to perform aggregate analysis when multiple labels per word/sentence, where each group of labels is a string separated by '+'s, are allowed:
compare-mt example/multited.ref.jpn example/multited.sys1.jpn example/multited.sys2.jpn
--compare_word_accuracies bucket_type=multilabel,ref_labels=example/multited.ref.jpn.tag,out_labels="example/multited.sys1.jpn.tag;example/multited.sys2.jpn.tag",label_set=lexical+formality+pronouns+ellipsisIt also is possible to create labels that represent numberical values. For example, scripts/relativepositiontag.py calculates the relative position of words in the sentence, where 0 is the first word in the sentence, 0.5 is the word in the middle, and 1.0 is the word in the end. These numerical values can then be bucketed. Here is an example:
compare-mt example/ted.ref.eng example/ted.sys1.eng example/ted.sys2.eng
--compare_word_accuracies bucket_type=numlabel,ref_labels=example/ted.ref.eng.rptag,out_labels="example/ted.sys1.eng.rptag;example/ted.sys2.eng.rptag"From this particular analysis we can discover that NMT does worse than PBMT at the end of the sentence, and of course other varieties of numerical labels could be used to measure different properties of words.
You can also perform analysis over labels for sentences. Here is an example:
compare-mt example/ted.ref.eng example/ted.sys1.eng example/ted.sys2.eng
--compare_sentence_buckets 'bucket_type=label,out_labels=example/ted.sys1.eng.senttag;example/ted.sys2.eng.senttag,label_set=0+10+20+30+40+50+60+70+80+90+100,statistic_type=score,score_measure=bleu'If you have a source corpus that is aligned to the target, you can also analyze accuracies according to features of the source language words, which would allow you to examine whether, for example, infrequent words on the source side are hard to output properly. Here is an example using the example data:
compare-mt example/ted.ref.eng example/ted.sys1.eng example/ted.sys2.eng --src_file example/ted.orig.slk --compare_src_word_accuracies ref_align_file=example/ted.ref.alignIf you wish to analyze the word log likelihoods by two systems on the target corpus, you can use the following
compare-ll --ref example/ll_test.txt --ll-files example/ll_test.sys1.likelihood example/ll_test.sys2.likelihood --compare-word-likelihoods bucket_type=freq,freq_corpus_file=example/ll_test.txtYou can analyze the word log likelihoods over labels for each word instead of the words themselves:
compare-ll --ref example/ll_test.txt --ll-files example/ll_test.sys1.likelihood example/ll_test.sys2.likelihood --compare-word-likelihoods bucket_type=label,label_corpus=example/ll_test.tag,label_set=CC+DT+IN+JJ+NN+NNP+NNS+PRP+RB+TO+VB+VBP+VBZNOTE: You can also use the above to also analyze the word likelihoods produced by two language models.
You can also analyze other language generation systems using the script. Here is an example of comparing two text summarization systems.
compare-mt example/sum.ref.eng example/sum.sys1.eng example/sum.sys2.eng --compare_scores 'score_type=rouge1' 'score_type=rouge2' 'score_type=rougeL'It is possible to use the COMET as a metric. To do so, you need to install it first by running
pip install unbabel-cometTo then run, pass the source and select the appropriate score type. Here is an example.
compare-mt example/ted.ref.eng example/ted.sys1.eng example/ted.sys2.eng --src_file example/ted.orig.slk \
--compare_scores score_type=comet \
--compare_sentence_buckets bucket_type=score,score_measure=sentcometNote that COMET runs on top of XLM-R, so it's highly recommended you use a GPU with it.
If you use compare-mt, we'd appreciate if you cite the paper about it!
@article{DBLP:journals/corr/abs-1903-07926,
author = {Graham Neubig and Zi{-}Yi Dou and Junjie Hu and Paul Michel and Danish Pruthi and Xinyi Wang and John Wieting},
title = {compare-mt: {A} Tool for Holistic Comparison of Language Generation Systems},
journal = {CoRR},
volume = {abs/1903.07926},
year = {2019},
url = {http://arxiv.org/abs/1903.07926},
}
There is an extensive literature review included in the paper above, but some key papers that it borrows ideas from are below:
- Automatic Error Analysis: Popovic and Ney "Towards Automatic Error Analysis of Machine Translation Output" Computational Linguistics 2011.
- POS-based Analysis: Chiang et al. "The Hiero Machine Translation System" EMNLP 2005.
- n-gram Difference Analysis Akabe et al. "Discriminative Language Models as a Tool for Machine Translation Error Analysis" COLING 2014.
There is also other good software for automatic comparison or error analysis of MT systems:
- MT-ComparEval: Very nice for visualization of individual examples, but
not as focused on aggregate analysis as
compare-mt. Also has more software dependencies and requires using a web browser, whilecompare-mtcan be used as a command-line tool.