Syntax Speaker Prediction
This repository contains notebooks used to train a model to predict the speaker (Scott or Wes) in one second cilps of their podcast, syntax.fm. There are accompanying files for using Prodigy to label the data required to build the model. There is a brief description of the purpose of each notebook as the first cell.
The Results
Total Podcast Time: 3 days, 15 hours, 56 minutes, 39 seconds
Wes: 2 days, 1 hours, 51 minutes, 11 seconds
Scott: 1 days, 11 hours, 51 minutes, 45 seconds
Non-speaking time (crosstalk, laughing, intros): 0 days, 2 hours, 13 minutes, 43 seconds
Cumulative Speaking Time
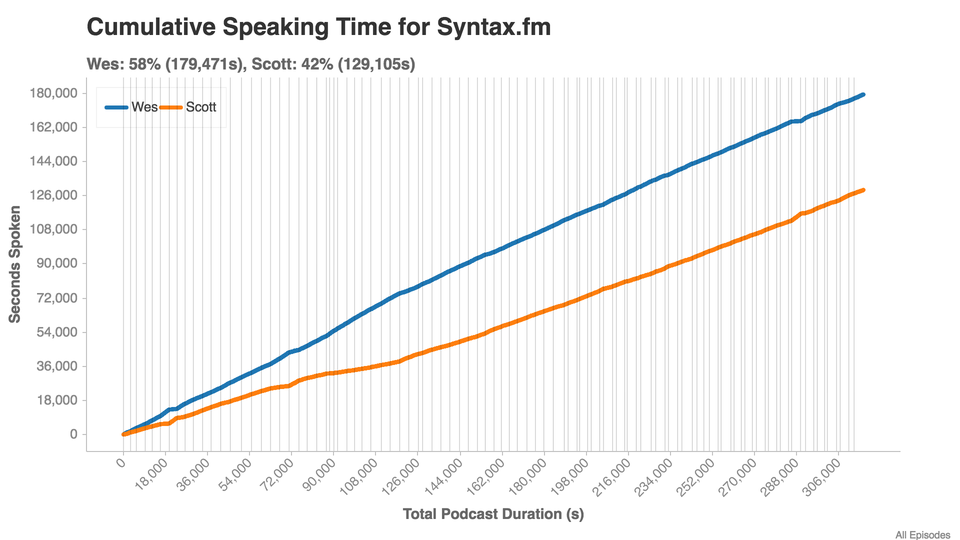
Each vertical line is the start of a new episode.
Helpful tools: