基于Scrapy-redis实现分布式爬虫
Scrapy是一个通用的爬虫框架,但其框架本身不支持分布式,为了提高爬取效率
① 充分利用多台机器的带宽速度爬取数据
② 充分利用多台机器的IP爬取
Python包要求:pymysql、redis、scrapy、re、urllib、json
Github地址:Lianjia_spider
Scrapy-Redis原理图
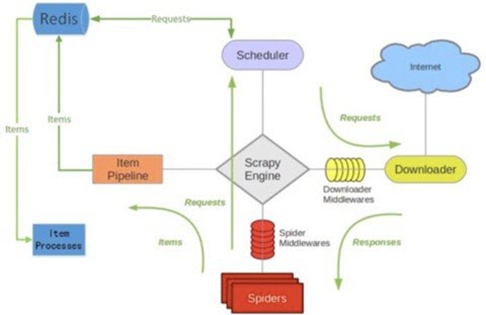
整体框架及逻辑
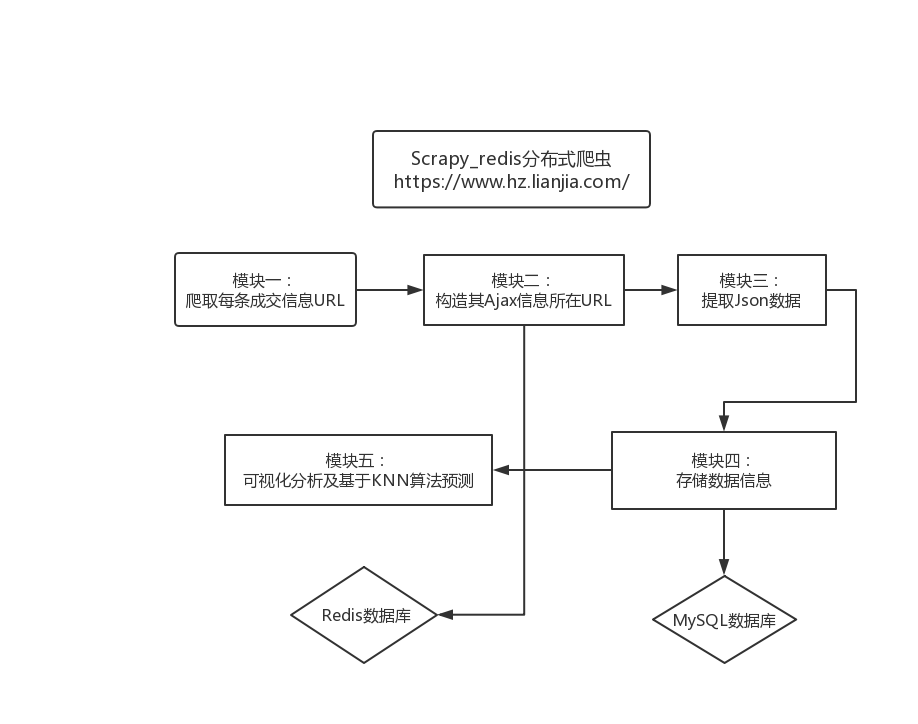
爬虫及数据可视化分析及预测
1.Lianjia_spider文件夹
- Lianjia_spider:scrapy-redis爬虫
- spiders文件夹:爬虫主体
- Lianjia.py:
- 遍历链家的搜索页中所有选项分类及筛选条件的所有页数URL
- 获取详情页URL
- 写入redis数据库中
- get_ajax_url.py
- 通过redis数据库得到Lianjia.py爬取的详情页URL
- 从详情页中获取ajax_url中的关键组成参数
- 存入redis数据库
- get_info.py
- 获取redis数据库中的ajax_url
- 解析ajax并从中获取小区、售卖中、已售卖的数据
- 创建item并传入管道文件
- 将ajax中的小区售卖中、已售卖详情页URL写入redis
- sell.py
- 从中读取售卖详情页URL
- 获得ajaxURL并写入redis
- sell_ajax.py
- 从redis获取售卖信息的URL
- 创建item对象并传入管道文件
- Lianjia.py:
- items.py:分别对小区数据、已售出数据、售卖中数据、新楼盘数据创建Item类
- pipelines.py:连接MySQL数据库,对数据进行去重,并根据传入Item对象进行不同写入MySQL数据库
- settings.py:连接Redis数据库,端口及地址,指定使用scrapy-redis的去重及(scrapy_redis.dupefilter.RFPDupeFilter)、不清理redis queues、指定使用scrapy_redis的scheduler
- spiders文件夹:爬虫主体
- launch_....py:运行单个爬虫
- launch_All.py:运行所有爬虫
- baidu_map.py:调用百度地图API demo得到经纬度数据
- _loc.py结尾:调用API实现经纬度获取demo,并去重和传入MySQL数据库
2.housing data analysis文件夹
-
forecast.ipynb:利用KNN算法进行预测并保存模型
-
housing_anaylse.ipynb:绘图
-
knn.model:保存的KNN模型
-
housing_heatmap.ipynb:处理得到热力图所需数据格式demo
-
predict.py:通过用户输入的数据利用保存的模型进行预测
-
housing_dataset.rar:打包数据集
-
.txt:数据集
-
heatmap_data.csv:绘制热力图数据集
-
baidu_map.py:调用百度地图API demo