Join Slack | Documentation | Blog | Twitter
![]()
![]()



Deepchecks is a Python package for comprehensively validating your machine learning models and data with minimal effort. This includes checks related to various types of issues, such as model performance, data integrity, distribution mismatches, and more.
This README refers to the Tabular version of deepchecks.
Check out the Deepchecks for Computer Vision & Images subpackage for more details about deepchecks for CV, currently in beta release.
pip install deepchecks -U --userNote
To install deepchecks together with the Computer Vision Submodule that is currently in beta release, replace deepchecks with "deepchecks[vision]" as follows.
pip install "deepchecks[vision]" -U --userconda install -c conda-forge deepchecksHead over to the Quickstart Notebook and see deepchecks output on a built-in dataset, or run it yourself to apply it on your own data and models.
A Suite runs a collection of Checks with optional Conditions added to them.
Example for running a suite on given datasets and with a supported model:
from deepchecks.tabular.suites import full_suite
suite = full_suite()
suite.run(train_dataset=train_dataset, test_dataset=test_dataset, model=model)Which will result in a report that looks like this:

See the full example here.
Note that some other suites (e.g. single_dataset_integrity) don't require a model as part of the input.
In the following section you can see an example of how the output of a single check without a condition may look.
To run a specific single check, all you need to do is import it and then to run it with the required (check-dependent) input parameters. More details about the existing checks and the parameters they can receive can be found in our API Reference.
from deepchecks.tabular.checks import TrainTestFeatureDrift
import pandas as pd
train_df = pd.read_csv('train_data.csv')
test_df = pd.read_csv('test_data.csv')
# Initialize and run desired check
TrainTestFeatureDrift().run(train_df, test_df)Will produce output of the type:
The Drift score is a measure for the difference between two distributions, in this check - the test and train distributions.
The check shows the drift score and distributions for the features, sorted by feature importance and showing only the top 5 features, according to feature importance. If available, the plot titles also show the feature importance (FI) rank.
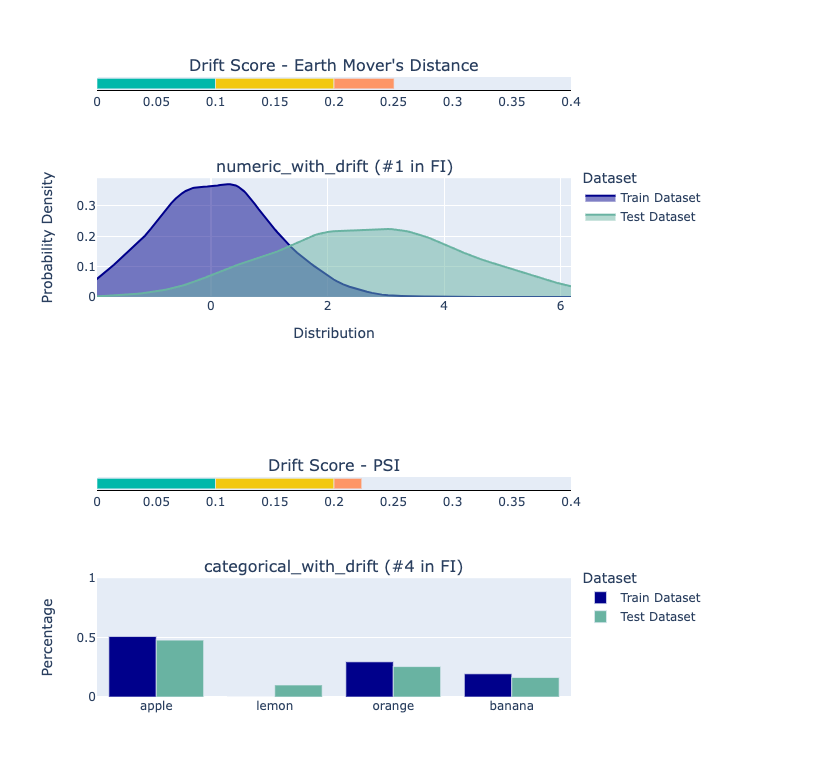

Each check enables you to inspect a specific aspect of your data and models. They are the basic building block of the deepchecks package, covering all kinds of common issues, such as:
- Model Error Analysis
- Label Ambiguity
- Data Sample Leakage
and many more checks.
Each check can have two types of results:
- A visual result meant for display (e.g. a figure or a table).
- A return value that can be used for validating the expected check results (validations are typically done by adding a "condition" to the check, as explained below).
A condition is a function that can be added to a Check, which returns a pass ✓, fail ✖ or warning ! result, intended for validating the Check's return value. An example for adding a condition would be:
from deepchecks.tabular.checks import BoostingOverfit
BoostingOverfit().add_condition_test_score_percent_decline_not_greater_than(threshold=0.05)which will return a check failure when running it if there is a difference of more than 5% between the best score achieved on the test set during the boosting iterations and the score achieved in the last iteration (the model's "original" score on the test set).
An ordered collection of checks, that can have conditions added to them. The Suite enables displaying a concluding report for all of the Checks that ran.
See the list of predefined existing suites for tabular data to learn more about the suites you can work with directly and also to see a code example demonstrating how to build your own custom suite.
The existing suites include default conditions added for most of the checks. You can edit the preconfigured suites or build a suite of your own with a collection of checks and optional conditions.

- The deepchecks package installed
- JupyterLab or Jupyter Notebook
Depending on your phase and what you wish to validate, you'll need a subset of the following:
- Raw data (before pre-processing such as OHE, string processing, etc.), with optional labels
- The model's training data with labels
- Test data (which the model isn't exposed to) with labels
- A supported model (e.g. scikit-learn models, XGBoost, any model implementing the predict method in the required format)
The package currently supports tabular data and is in beta release for the computer vision submodule.
Deepchecks validation accompanies you from the initial phase when you have only raw data, through the data splits, and to the final stage of having a trained model that you wish to evaluate. See more about typical usage scenarios and the built-in suites in the docs.
- https://docs.deepchecks.com/ - HTML documentation (stable release)
- https://docs.deepchecks.com/en/latest - HTML documentation (latest release)
- Join our Slack Community to connect with the maintainers and follow users and interesting discussions
- Post a Github Issue to suggest improvements, open an issue, or share feedback.