Source code for the AAAI 2021 paper: Movie Summarization via Sparse Graph Construction
In this work, we aim at identifying the most important scenes in a movie in order to create video summaries. Since we do not have summary labels for the movies, we instead address the task of turning point (TP) identification in order to find scenes that represent each TP and then assemble them into a summary (see [1] for more details on the task). Moreover, for addressing TP identification, we propose a graph-based approach: We learn end-to-end a latent sparse graph, where the nodes are the scenes in the screenplay and the edges denote the relationships between scenes. The relationships between the scenes in the graph are computed based on multimodal features from both the screenplay and the movie video. The graph provides better scene contextualization for the task and interpretability, where we can investigate the movie graphs and measure the degree of connectivity between nodes. Here is a high-level overview of our model, GraphTP:
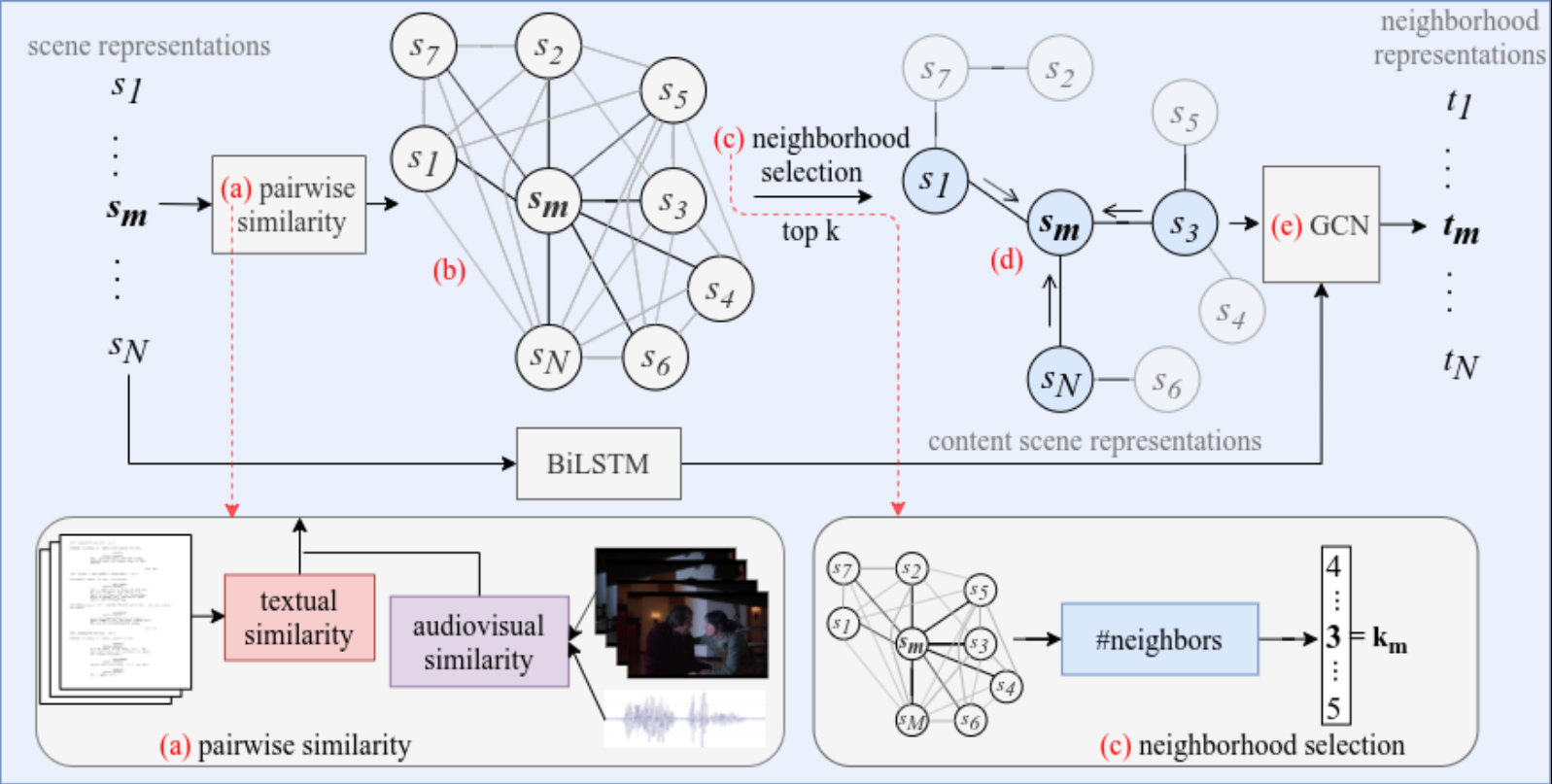
We overall have 122 movies (84 for training and 38 for testing), which include approximately 17,000 scenes and 1,500 TP events (note that TP identification is a scene-level binary classification problem). For each movie, we encode the sentences contained in each scene in the screenplay using the Universal Sentence Encoder (USE). If you want to access the raw screenplays of the movies, you can find them in the Scriptbase corpus. We also collected the corresponding videos and extracted visual and audio features for the frames and segments of each scene, respectively. Due to copyright issues, we cannot publicly upload the raw movie videos (we can only provide them if you first purchase the DVDs and then email us at p.papalampidi@sms.ed.ac.uk). You can download the processed multimodal representations for the screenplays here. This is a folder that contains one pickle file per movie. Each pickle contains the natural language sentences contained in a screenplay scene, the characters participating in the scene, the corresponding sentence-level USE representations and sequences of audio and visual features per scene.
Moreover, in folder dataset/ we include three more files:
gold_labels_test.pkl: contains the gold scene-level labels for the TPs of the movies of the test setsilver_distributions_train.pickle: contains the silver-standard probability distributions per TP over the screenplay scenes for the movies of the training set as computed by the teacher model (see [1] for details and you can find the code for the teacher model here).splits.csv: contains the names of the movies that belong to the train and test sets.
In order to train the model (5-fold cross-validation), first select your desired configuration in model_configs/GraphTP.yaml. You can select where you data folder (downloaded multimodal features) is, where you want to save the results per fold, where the tensorboard outputs will be saved (for visualization purposes), which model you want to run (TAM or GraphTP) and whether you want the text only or the multimodal version of the respective model.
After the configuration, you can run the model:
cd models
python main.py
If you want to evaluate the model (given that you have first trained it and produced the outputs) you can do the following:
cd modules
python evaluation --folder 'path_to_output_folder'
After training, you can also examine and visualize the graphs for the movies of the test set. You can see the connectivity per TP and genre by running the following:
cd graph_analysis
python movie_analysis.py --folder 'path_to_output_folder'
You can visualize the learnt graph for a movie by running:
python visualize_movie_graph.py --folder 'path_to_output_folder' --movie 'name_of_the_movie'
-
Pytorch version >= 1.5.0
-
Python >= 3.7.7
-
Install the rest of the requirements by running:
pip install -r requirements.txt
@article{papalampidi2020movie,
title={Movie Summarization via Sparse Graph Construction},
author={Papalampidi, Pinelopi and Keller, Frank and Lapata, Mirella},
journal={arXiv preprint arXiv:2012.07536},
year={2020} }
[1] Papalampidi, Pinelopi, Frank Keller, and Mirella Lapata. "Movie Plot Analysis via Turning Point Identification." Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP). 2019.