K8S中进行自定义指标HPA需要依靠Prometheus,
若要实现自定义指标,必须实现Prometheus接口,便于Prometheus定时采集相应指标,Prometheus定义了几类指标类型,用于自定义用户指标,如下:
| 类型 | 描述 |
|---|---|
| Desc | Desc是每个普罗米修斯度量使用的指标。它本质上是指标的不可变元数据。此包中包含的普通指标实现在后台管理其 Desc。 |
| Counter | 只增计数器(接口类型),可通过Inc() 或Add(float64)进行计数器值的增加,一般可用于统计连接数量、请求个数,计数器通常用于计算服务的请求、完成的任务、发生的错误等 |
| CounterVec | CounterVec 是一个收集器,它捆绑了一组计数器,这些计数器共享相同的Desc,但其变量标签的值不同。例如可统计访问不同API的请求数量,不同状态码的数量 |
| Gauge | gauge表示一个数值,表示可以任意上下移动的单个数值。gauge通常用于测量值,如温度或当前内存使用情况,但也用于可以上升和下降的“计数”,如正在运行的goroutine的数量 |
| GaugeVec | GaugeVec 是一个收集器,它捆绑了一组gauge,这些gauge共享相同的Desc,但其变量标签具有不同的值。可以按不同维度划分的同一事物 |
| Histogram | Histogram 直方图对事件或样本流的单个观测值进行计数。 |
| pHistogramVec | HistogramVec是一个收集器,它捆绑了一组直方图,这些直方图共享相同的Desc,但变量标签具有不同的值。可按不同维度划分的同一事物 |
下面是一个基于golang简单的应用程序,实现了Prometheus采集接口:
package main
import (
"github.com/prometheus/client_golang/prometheus"
"github.com/prometheus/client_golang/prometheus/promhttp"
"log"
"net/http"
)
/*
// 自定义指标
var (
//Desc是每个普罗米修斯度量使用的指标。它本质上是指标的不可变元数据。此包中包含的普通指标实现在后台管理其 Desc。
desc prometheus.Desc
//只增计数器(接口类型),可通过Inc() 或Add(float64)进行计数器值的增加,一般可用于统计连接数量、请求个数,计数器通常用于计算服务的请求、完成的任务、发生的错误等
counter prometheus.Counter
//CounterVec 是一个收集器,它捆绑了一组计数器,这些计数器共享相同的Desc,但其变量标签的值不同。例如可统计访问不同API的请求数量,不同状态码的数量
counterVec prometheus.CounterVec
//gauge表示一个数值,表示可以任意上下移动的单个数值。gauge通常用于测量值,如温度或当前内存使用情况,但也用于可以上升和下降的“计数”,如正在运行的goroutine的数量。
gauge prometheus.Gauge
//GaugeVec 是一个收集器,它捆绑了一组gauge,这些gauge共享相同的Desc,但其变量标签具有不同的值。可以按不同维度划分的同一事物
gaugeVec prometheus.GaugeVec
//Histogram 直方图对事件或样本流的单个观测值进行计数。
histogram prometheus.Histogram
//HistogramVec是一个收集器,它捆绑了一组直方图,这些直方图共享相同的Desc,但变量标签具有不同的值。可按不同维度划分的同一事物
histogramVec prometheus.HistogramVec
)
*/
type Metrics struct {
qps *prometheus.CounterVec //统计api请求数量,用于计算qps
cpuTemp prometheus.Gauge //模拟当前CPU温度
}
func NewCustomMetrics() *Metrics {
m := &Metrics{
qps: prometheus.NewCounterVec(
prometheus.CounterOpts{
Name: "total_req_num",
Help: "Number of total http requests.",
},
[]string{"status", "api"},
),
cpuTemp: prometheus.NewGauge(prometheus.GaugeOpts{
Name: "cpu_temperature_celsius",
Help: "Current temperature of the CPU.",
}),
}
return m
}
func main() {
m := NewCustomMetrics()
//将自定义指标添加到到默认prometheus监控指标上
prometheus.MustRegister(m.qps)
prometheus.MustRegister(m.cpuTemp)
//注册新的prometheus监控指标,只监控注册的自定义指标
/*
reg := prometheus.NewRegistry()
reg.MustRegister(m.qps)
reg.MustRegister(m.cpuTemp)
*/
m.cpuTemp.Set(50.0)
beginTemp := 50.0
reqNum := 0
//http.Handle("/metrics", promhttp.HandlerFor(reg, promhttp.HandlerOpts{Registry: reg}))
http.HandleFunc("/", func(w http.ResponseWriter, r *http.Request) {
path := r.URL.Path
statusCode := 200
m.qps.WithLabelValues("200", "/").Inc()
reqNum++
log.Println("total request num is:", reqNum)
switch path {
case "/cpuTempUp":
m.cpuTemp.Add(10.0)
m.qps.WithLabelValues("200", "cpuTempUp").Inc()
beginTemp += 10
log.Println("cpu temp up,current is:", beginTemp)
case "/cpuTempDown":
m.cpuTemp.Sub(10.0)
beginTemp -= 10
m.qps.WithLabelValues("200", "cpuTempDown").Inc()
log.Println("cpu temp down,current is:", beginTemp)
case "/metrics":
//调用prometheus默认监控器,将默认监控指标发送至请求端
promhttp.Handler().ServeHTTP(w, r)
//可自定义配置注册器,将监控器器所注册的指标发送至请求端
//promhttp.HandlerFor(reg,promhttp.HandlerOpts{Registry: reg}).ServeHTTP(w,r)
default:
w.WriteHeader(statusCode)
_, err := w.Write([]byte("custom metrics"))
if err != nil {
return
}
}
})
http.ListenAndServe(":3000", nil)
}将上述golang程序打包成镜像
FROM golang:1.20-alpine as builder
WORKDIR /workspace
COPY go.mod .
COPY go.sum .
RUN go mod download
COPY . .
RUN go build -ldflags="-w -s" -o /out/custom_metrics_app_linux .
FROM alpine
WORKDIR /build
COPY --from=builder /out/custom_metrics_app_linux .
EXPOSE 3000
ENTRYPOINT ["./custom_metrics_app_linux"] $ docker build -t custom-metrics-app:v1 .启动该镜像,可访问其/metrics路径,可得到Prometheus监控的所有内容,其中就包括注册好的自定义指标。
# HELP cpu_temperature_celsius Current temperature of the CPU.
# TYPE cpu_temperature_celsius gauge
cpu_temperature_celsius 50
# TYPE total_req_num counter
total_req_num{api="/",status="200"} 5
应用程序通过实现Prometheus的metrics接口,可实现Prometheus采集自定义指标,通过prometheus-adapter转化为K8S可以识别的格式,prometheus采集到的metrics并不能直接给k8s用,因为两者数据格式不兼容,这时就需要另外一个组件(prometheus-adapter),将prometheus的metrics 数据格式转换成k8s API接口能识别的格式,因为prometheus-adapter是自定义API Service,所以还需要用Kubernetes aggregator在主API服务器中注册,以便直接通过/apis/来访问。
kubernetes apiserver 提供了三种 API 用于监控指标相关的操作:
- resource metrics API:被设计用来给 k8s 核心组件提供监控指标,例如 kubectl top;
- custom metrics API:被设计用来给 HPA 控制器提供指标。
- external metrics API:被设计用来通过外部指标扩容
prometheus-adapter支持以下三种API,kubectl top node/pod 是 resource metrics 指标。所以我们可以用prometheus-adapter替代metrics-server
- resource metrics API
- custom metrics API
- external metrics AP
将自定义的指标通过Prometheus-adapter相关配置,定义指标转换规则,用作custom.metrics.k8s.io HPA使用,custom-metrics-values-adapter.yaml配置如下:
prometheus:
url: http://mon-kube-prometheus-stack-prometheus.monitoring.svc
port: 9090
metricsRelistInterval: 10s
logLevel: 4
rules: #用于custom.metrics.k8s.io,用于自定义指标的监控,定义指标转换规则,用作custom.metrics.k8s.io HPA使用
default: false
custom:
- seriesQuery: 'total_req_num{status!="", api!=""}' #用于筛选series
resources: #将series中的标签与目标资源类型关联起来
overrides: #将series中的namespace字段与k8s资源中的namespace字段关联起来
namespace:
resource: "namespace" #将series中的namespace字段与k8s资源中的namespace字段关联>起来
pod:
resource: "pod" #将series中的pod字段,与资源中的pods字段关联
name: #用于给指标重命名,比如以_total结尾的指标,去掉后缀
matches: "total_req_num" #匹配源指标名
as: "qps" #目标指标名称
metricsQuery: 'sum(rate(<<.Series>>{<<.LabelMatchers>>}[30s])) by (<<.GroupBy>>)' #转换指标规则
- seriesQuery: 'cpu_temperature_celsius'
resources:
overrides:
namespace:
resource: "namespace" #将series中的namespace字段与k8s资源中的namespace字段关联>起来
pod:
resource: "pod" #将series中的pod字段,与资源中的pods字段关联
name:
matches: "cpu_temperature_celsius"
as: "cpuTemperature"
metricsQuery: 'avg(<<.Series>>) by (<<.GroupBy>>)利用helm包管理器安装prometheus-adapter
$ helm install prometheus-adapter prometheus-community/prometheus-adapter -f custom-metrics-values-adapter.yaml在 Kubernetes 1.7 版本引入了聚合层,允许第三方应用程序通过将自己注册到kube-apiserver上,仍然通过 API Server 的 HTTP URL 对新的 API 进行访问和操作。为了实现这个机制,Kubernetes 在 kube-apiserver 服务中引入了一个 API 聚合层(API Aggregation Layer),用于将扩展 API 的访问请求转发到用户服务的功能。
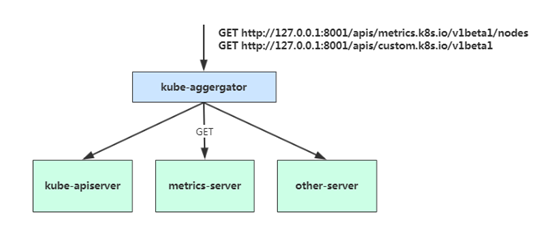
当访问 apis/metrics.k8s.io/v1beta1 的时候,实际上访问到的是一个叫做 kube-aggregator 的代理。而 kube-apiserver,正是这个代理的一个后端;而 Metrics Server,则是另一个后端 。通过这种方式,我们就可以很方便地扩展 Kubernetes 的 API 了。
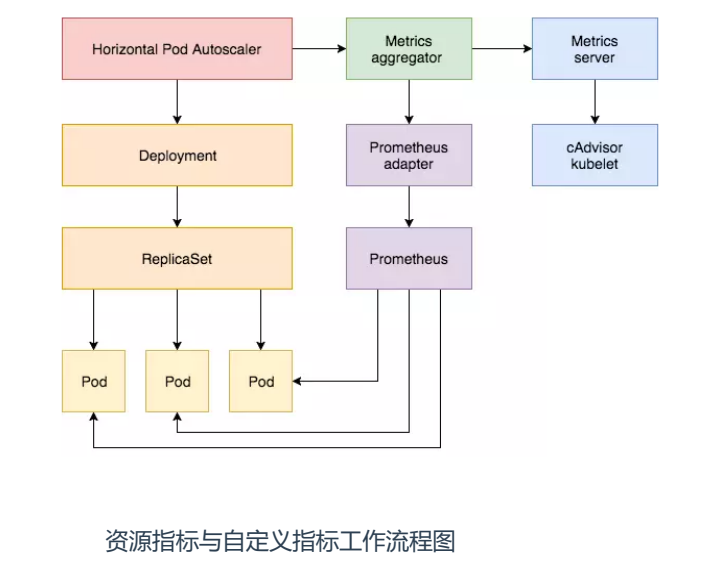
(1) 原生指标工作流程: hpa -> apiserver -> kube aggregation -> metrics-server -> kubelet(cadvisor)
(2) 自定义资源指标工作流程: hpa -> apiserver -> kube aggregation -> prometheus-adapter -> prometheus -> pods
custom-metrics-deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: custom-metrics-app
name: custom-metrics-app
namespace: default
spec:
replicas: 1
selector:
matchLabels:
app: custom-metrics-app
strategy: {}
template:
metadata:
annotations:
prometheus.io/scrape: "true"
prometheus.io/path: "/metrics"
prometheus.io/port: "9090"
labels:
app: custom-metrics-app
spec:
containers:
- image: custom-metrics-app:v1
name: custom-server
imagePullPolicy: Never #镜像从本地拉取
ports:
- containerPort: 3000
resources:
requests:
memory: '300Mi'
custom-metrics-service.yaml
apiVersion: v1
kind: Service
metadata:
name: custom-metrics-service
labels:
app: custom-metrics-app
annotations:
prometheus.io/scrape: "true"
prometheus.io/path: "/metrics"
prometheus.io/port: "http"
spec:
type: ClusterIP
ports:
- name: http
port: 3000
targetPort: 3000
selector:
app: custom-metrics-app
custom-metrics-hpa.yaml使用两个自定义指标用于测试HPA的扩缩容,假如我们设置每个业务 Pod 的平均 QPS 达到 500或CPU温度平均达到80度(仅作为练习,不具备实际意义),就触发扩容,最小副本为 1 个,最大副本数量为10。
kind: HorizontalPodAutoscaler
apiVersion: autoscaling/v2beta1
metadata:
name: sample-httpserver
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: custom-metrics-app
minReplicas: 1
maxReplicas: 10
metrics:
- type: Pods
pods:
metricName: qps
targetAverageValue: 500m
- type: Pods
pods:
metricName: cpuTemperature
targetAverageValue: 80若安装prometheus-operator可使用ServiceMonitor将需要监控的任务注册到prometheus上,下面是ServiceMonitor的相关配置custom-metrics-service-monitor.yaml
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
name: custom-metrics-sm
labels:
release: mon
spec:
jobLabel: custom-metrics
selector:
matchLabels:
app: custom-metrics-app
endpoints:
- port: http
interval: 10s
path: /metrics#创建上述资源
$ kubectl apply -f custom-metrics-config/
deployment.apps/custom-metrics-app created
horizontalpodautoscaler.autoscaling/custom-metrics-hpa created
servicemonitor.monitoring.coreos.com/custom-metrics-sm created
service/custom-metrics-service created
#查看资源状态
$ kubectl get pod,svc,hpa
NAME READY STATUS RESTARTS AGE
pod/custom-metrics-app-6c6df7bcfc-mxsq7 1/1 Running 0 113s
pod/load-generator 1/1 Running 2 3d3h
pod/php-apache-779cd44bdc-pr7z2 1/1 Running 0 4s
pod/prometheus-adapter-56fbf477b6-hxbbl 1/1 Running 0 135m
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/custom-metrics-service ClusterIP 10.103.57.174 <none> 3000/TCP 113s
service/kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 3d3h
service/prometheus-adapter ClusterIP 10.108.231.115 <none> 443/TCP 172m
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
horizontalpodautoscaler.autoscaling/custom-metrics-hpa Deployment/custom-metrics-app 100m/500m, <unknown>/80 1 10 113s看资源状态
在prometheus服务中,可查看到该监控任务和监控指标


可查询自定义指标值
在另一个busybox Pod中shell执行 while true; do wget -q -O- http://custom-metrics-service.default.svc:3000/; done 增大qps值,查看扩容情况。


最大扩容到10个副本。
prometheus 服务页面可以观察到自定义指标实时变化


停止压力测试,整体qps负载下降,观察缩容情况



Pod数量下降

在另一个busybox Pod中shell执行 while true; do wget -q -O- http://custom-metrics-service.default.svc:3000/cpuTempDown; sleep 10s;done 增大温度值,查看扩容情况。

当平均温度大于80度开始扩容



此时QPS依然很低

最终扩容到最大10个pod
