AWS S3 Glue Presto Spark SparkSQL Alluxio Parquet TPC-H
A comparative analysis of Distibuted SQL Engines SparkSQL and Presto
-
Dataset: TPC-H
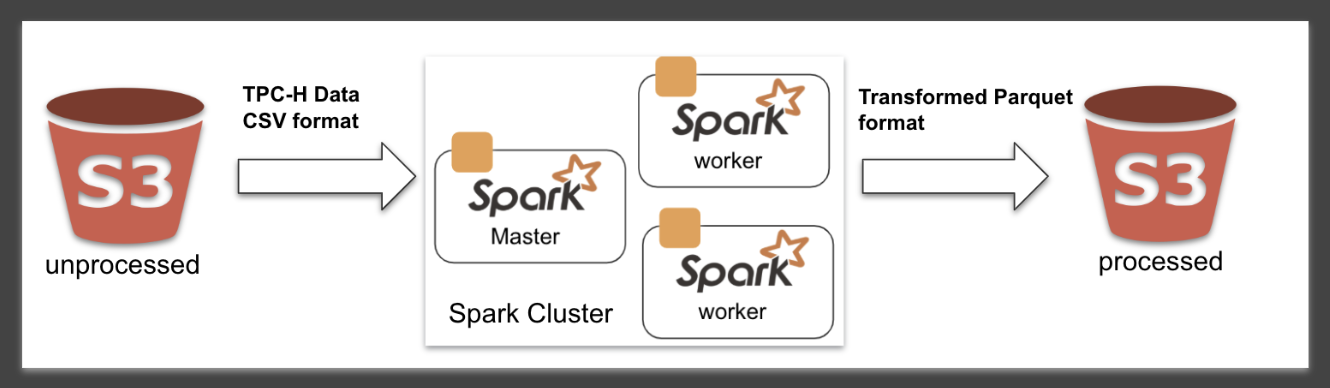
ETL Stats
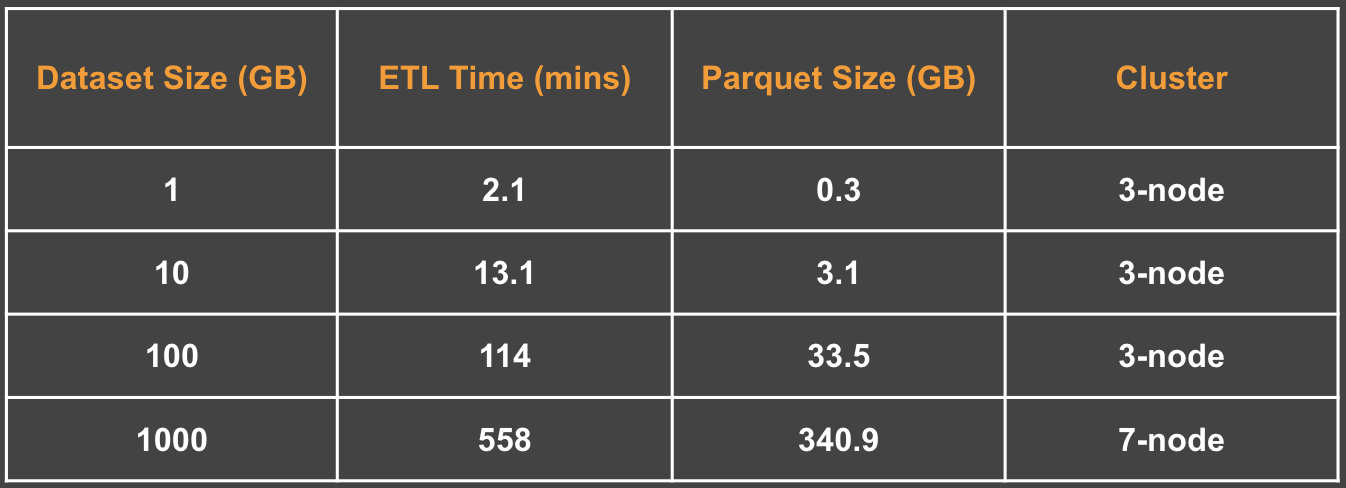
7 node: 1 x m4.xlarge(master), 6 x m4.large(worker nodes)
3 node: 1 x m4.xlarge(master), 2 x m4.large(worker nodes)



-
Presto, Spark, Glue, S3
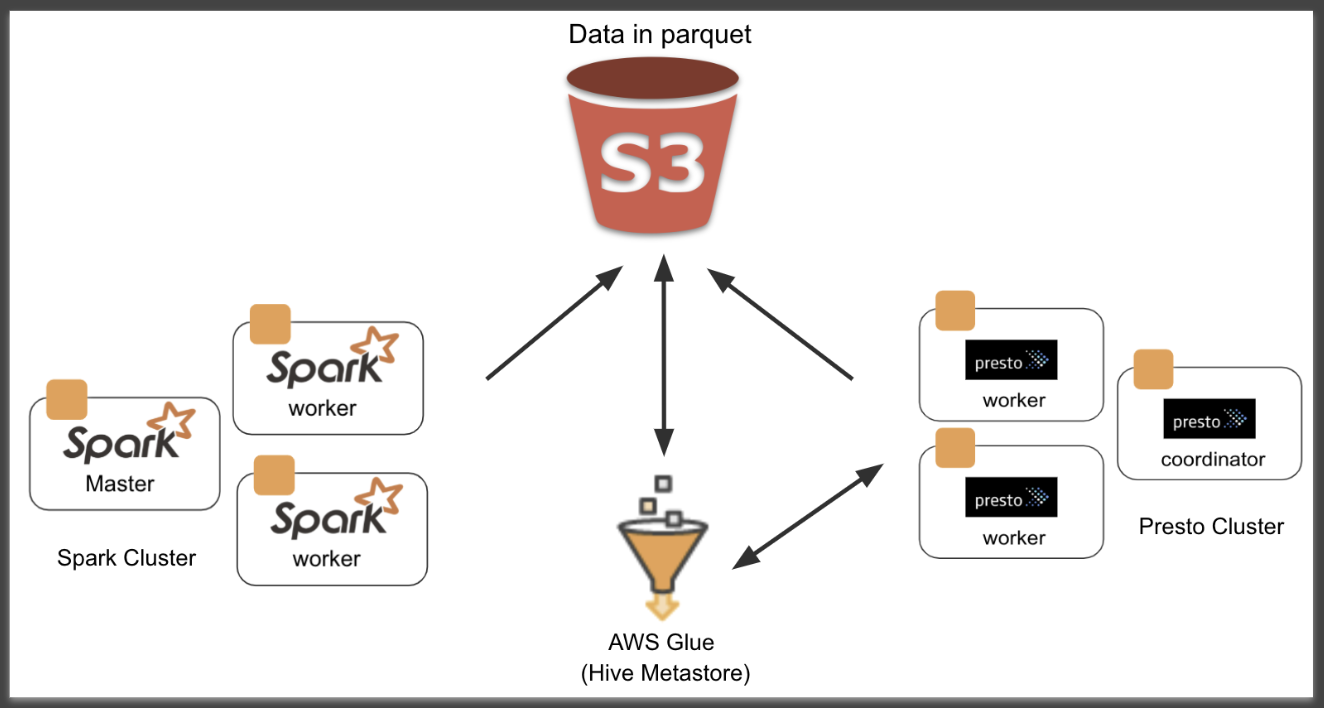

-
Query Stats
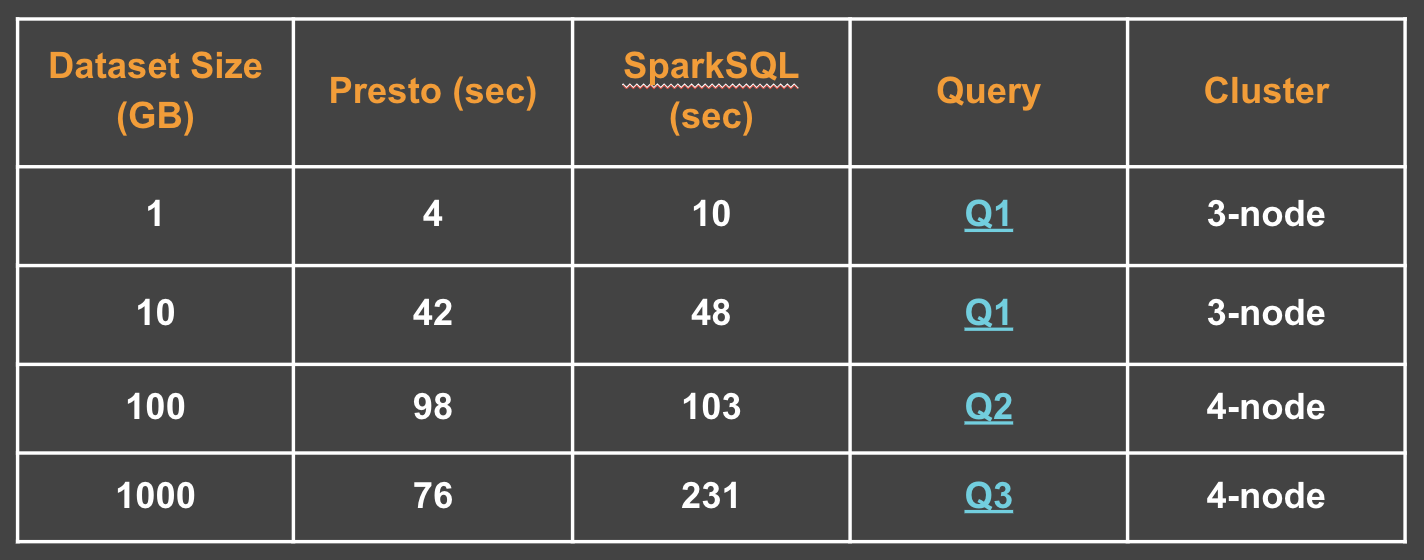
-
Queries
Q1

Q2

Q3





-
Automate the cluster provisioning
-
Automate experiments and stats collection
- Config driven framework
-
Run federated queries