Nesse repositório, você encontrará um exercício para a formação em infraestrutura. O objetivo, nesse caso, não é necessariamente terminar o desafio e entregar um resultado perfeito, mas sim aprender a buscar recursos na internet e aplicar os conhecimentos adquiridos. Esse exercício também será importante para entendermos as facilidades e dificuldades de cada um, para podermos endereçá-las melhor durante a formação.
Sem mais delongas, vamos ao exercício! 🤓
Esse exercício será separado em etapas curtas, com a finalidade de obter um entregável ao final de cada uma. Ele foi estruturado para se assemelhar, de maneira simplificada, a problemas que você poderá trabalhar no futuro, ao final da formação.
Assim, o objetivo é escrever um código que se assemelharia a uma pipeline de dados, envolvendo etapas de ingestão, processamento e saída.
Ao final, cada participante deverá submeter um arquivo com o código em Python referente à sua implementação (pode ser um script, um notebook ou semelhantes), dizendo, em comentários no código, quais etapas julga que conseguiu cumprir e onde teve dificuldades, se for o caso.
Nota: Tente sempre comentar seu código e mantê-lo organizado, isso ajuda você e outros leitores a compreendê-lo no futuro.
Aqui serão descritas as etapas do desafio que, idealmente, devem ser seguidas de forma sequencial. Para o caso de dificuldade em alguma etapa, você poderá seguir para a próxima, se assim desejar.
- Objetivo: nessa etapa, você deve somente ingerir dados da API do
randomuser.mee observar o formato dos dados, tentando imaginar como eles poderiam ser usados para construir uma tabela. - Descrição da solução: a solução dessa etapa consiste em uma função para consumir a API na URL
https://randomuser.me/api/e retornar um dicionário com os dados. - Links úteis:
- Documentação da API: https://randomuser.me/documentation
- Introdução a ingestão de dados via API: https://www.dataquest.io/blog/python-api-tutorial/
- Objetivo: nessa etapa, você deve coletar dados da API e armazená-los em um arquivo CSV.
- Descrição da solução: a solução dessa etapa consiste em uma função para coletar uma quantidade
nde dados da API (sendonum valor fornecido via parâmetro da função), manipulá-los para montar umpandas.DataFramee salvar o resultado em um arquivo CSV. - Links úteis:
- Documentação da API: https://randomuser.me/documentation
- Documentação do Pandas: https://pandas.pydata.org/docs/
- Dicas:
- Para tornar os dados mais fáceis de manipular no futuro, faça com que o
DataFrameseja "plano", ou seja, cada coluna seja um único atributo do objeto. - Para ter dados suficientes para uma análise razoável nas próximas etapas, recomendamos
n>=500.
- Para tornar os dados mais fáceis de manipular no futuro, faça com que o
- Objetivo: agora, você pode observar que, na base de dados obtida, devido às diferentes nacionalidades dos usuários, os números de telefone e celular têm formatos diferentes. Você deve transformá-los para um formato único, escolhido arbitrariamente.
- Descrição da solução: uma função que recebe, como parâmetro, um
pandas.DataFramee retorna umpandas.DataFramecom as mesmas colunas, mas com os números de telefone e celular formatados de forma única. - Links úteis:
- Documentação do Pandas: https://pandas.pydata.org/docs/
- Objetivo: com seus dados devidamente tratados, você deve gerar os seguintes itens:
- Um relatório em texto (não precisa de formatação) contendo:
- A porcentagem dos usuários por gênero
- A porcentagem dos usuários por país
- Uma imagem contendo um gráfico de distribuição da idade dos usuários (a biblioteca utilizada para o
plotpode ser qualquer uma).
- Um relatório em texto (não precisa de formatação) contendo:
- Descrição da solução: uma função que recebe, como parâmetro, um
pandas.DataFramee gera dois arquivos: um relatório em texto e outro contendo um gráfico de distribuição da idade dos usuários. - Links úteis:
- Documentação do Pandas: https://pandas.pydata.org/docs/
- Documentação do Matplotlib: https://matplotlib.org/
- Documentação do Seaborn: https://seaborn.pydata.org/
- Objetivo: utilizar técnicas de agrupamento para descobrir usuários que moram no mesmo país e estado.
- Descrição da solução: uma função que recebe, como parâmetro, um
pandas.DataFramee retorna umpandas.DataFramecom as mesmas colunas, mas com os dados agrupados por país e estado. - Links úteis:
- Documentação do Pandas: https://pandas.pydata.org/docs/
-
Objetivo: realizar o particionamento dos dados em formato Hive utilizando as informações de país e estado de cada usuário.
-
Descrição da solução: uma função que recebe, como parâmetro, um
pandas.DataFramee salva todos os dados em arquivos CSV particionados por país e estado. -
Links úteis:
- Documentação do Pandas: https://pandas.pydata.org/docs/
- Documentação do Hive: https://hive.apache.org/
- Documentação do BigQuery para dados particionados em Hive: https://cloud.google.com/bigquery/docs/hive-partitioned-queries-gcs
-
Exemplo para esclarecimento: supondo que haja um
DataFrameconforme o seguinte:ano mes sigla_uf dado 0 2020 1 SP a 1 2021 2 SP b 2 2020 3 RJ c 3 2021 4 RJ d 4 2020 5 PR e 5 2021 6 PR f 6 2021 6 PR g 7 2025 9 PR h
Caso quiséssemos particionar o
DataFrameutilizando as colunasano,mesesigla_uf, o resultado obtido seria a seguinte estrutura de diretórios: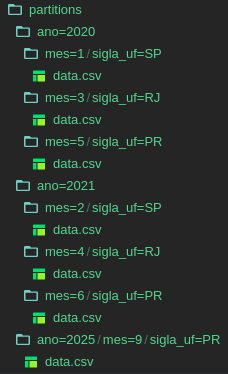
Cada arquivo gerado, então, teria o seguinte formato (esse em questão seria o
ano=2025/mes=9/sigla_uf=PR/data.csv):dado 0 h
Note que, no arquivo CSV gerado, as colunas referentes às informações utilizadas para particionamento são removidas.

- Objetivo: nessa etapa, você deve parametrizar seu código para que ele seja executado com valores diversos fornecidos pelo usuário.
- Descrição da solução: a solução dessa etapa consiste em uma função principal que recebe diversos parâmetros e executa as diversas etapas descritas anteriormente em função dos parâmetros fornecidos. Note que essa etapa é crucial para que seu código se torne reutilizável.
- Dicas:
- Tente pensar no maior número de parâmetros que sejam relevantes para sua pipeline de dados, sem afetar sua funcionalidade.
- Colocar valores padrão para alguns desses parâmetros reduz o ônus do usuário de preenchê-los por conta própria.