When compile & run this program, this is dependenciees I've used:
- Hadoop 3.3.0
- Hadoop 3.3.0 Fixes, I've included this in
hadoop-3.3.0-configs.zipin this project - JDK 8 (Java Development Kit 8)
- Windows 10 as operating system
I should say that this is my first hadoop try, and I found that this program a bit buggy for me, and need a loot of manual configuration, so this is my advices for you,
- Run
start-dfsandstart-yarnas ADMIN, when not as ADMIN I found theHDFSan dyarnservice couldn't run properly.
- Word Count, counting every word (separated by whitespace) occurences in a text file.
- Average, counting average transaction value from every ID (each ID could have multiple transactions).
- Top Ten, searching top ten transaction with most value.
-
Navigate to
WordCountfolder for make it easier -
Compile the java file or
WordCount.javafile and link it with needed hadoop library in%HADOOP_HOME%\share\hadoop, for example with this codejavac -classpath "D:\ProgramData\Hadoop\hadoop-3.3.0\share\hadoop\common\*";"D:\ProgramData\Hadoop\hadoop-3.3.0\share\hadoop\mapreduce\*" -d WordCount/ WordCount.java -
Create jar file from the classes, for example with this code
jar -cvf WordCount.jar -C WordCount/ .
As an example, this is compilation step in my test

-
Make sure that
HDFSandyarnservice already started, by running these command (my advice run in the terminal as ADMINISTRATOR)start-dfs start-yarnI've already included
%HADOOP%_HOME\sbinin the PATH, so that should be work. -
Write the text file that want to be counted, for example
wordcount.txtthat I want to create here -
Create a directory in hadoop as the input directory, for example here
/input9by running this commandhadoop fs -mkdir /input9 -
Place your text file into hadoop directory that already created (should be empty), for example by this code
hadoop fs -put wordcount.txt /input9make sure it already created by
lscommand in hadoop, for example by this codehadoop fs -ls /input9it would show something like this,
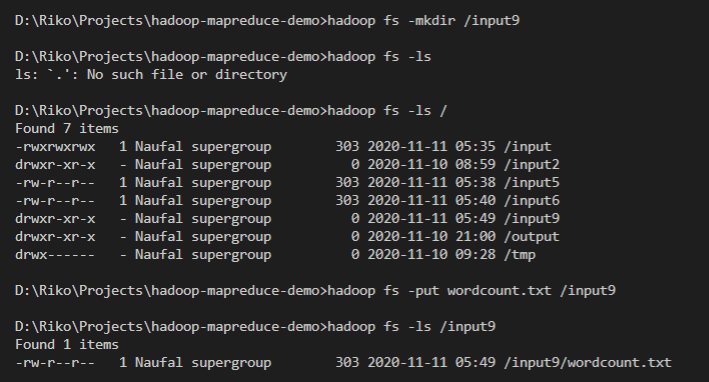
-
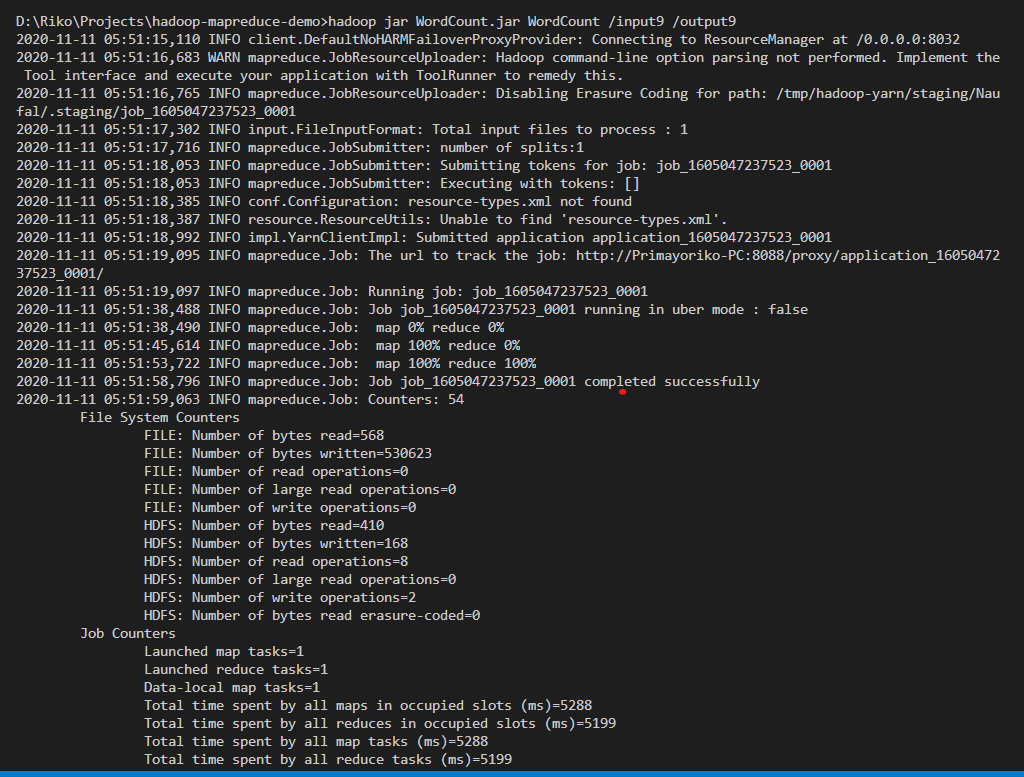
Run hadoop
.jarprogram by input directory is the directory that has just been created, and output directory is a new or non-existent directory, for example by this codehadoop jar WordCount.jar WordCount /input9 /output9just wait first and would show something like this,
-
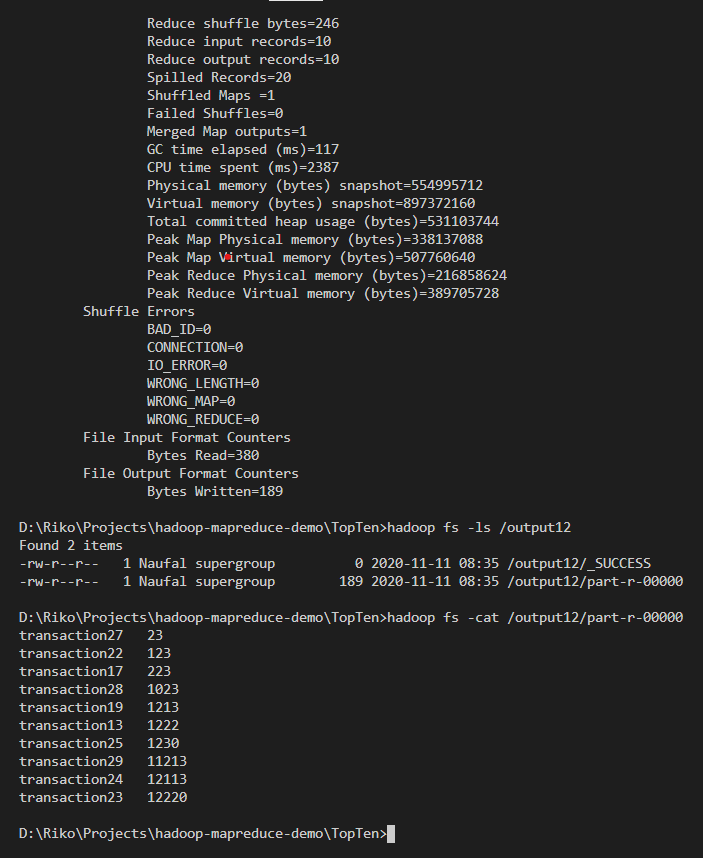
After finish, explore the output directory and try to
catfile there, and you should find the result there, as in this example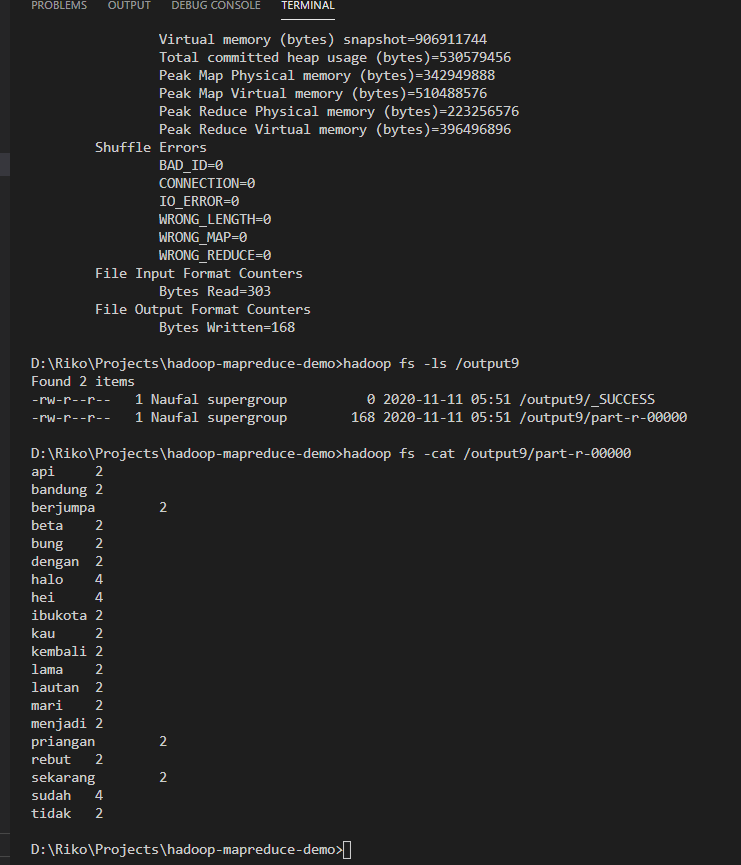



-
Navigate to
Averagefolder for make it easier -
Compile the java file or
Average.javafile and link it with needed hadoop library in%HADOOP_HOME%\share\hadoop, for example with this codejavac -classpath "D:\ProgramData\Hadoop\hadoop-3.3.0\share\hadoop\common\*";"D:\ProgramData\Hadoop\hadoop-3.3.0\share\hadoop\mapreduce\*" -d Average/ Average.java -
Create jar file from the classes, for example with this code
jar -cvf Average.jar -C Average/ .
As an example, this is compilation step in my test

-
Make sure that
HDFSandyarnservice already started, by running these command (my advice run in the terminal as ADMINISTRATOR)start-dfs start-yarnI've already included
%HADOOP%_HOME\sbinin the PATH, so that should be work. -
Write the text file that want to be counted, for example
average.txtthat I want to create here -
Create a directory in hadoop as the input directory, for example here
/input11by running this commandhadoop fs -mkdir /input11 -
Place your text file into hadoop directory that already created (should be empty), for example by this code
hadoop fs -put average.txt /input11make sure it already created by
lscommand in hadoop, for example by this codehadoop fs -ls /input11it would show something like this,
-
Run hadoop
.jarprogram by input directory is the directory that has just been created, and output directory is a new or non-existent directory, for example by this codehadoop jar Average.jar Average /input11 /output11just wait first and would show something like this,
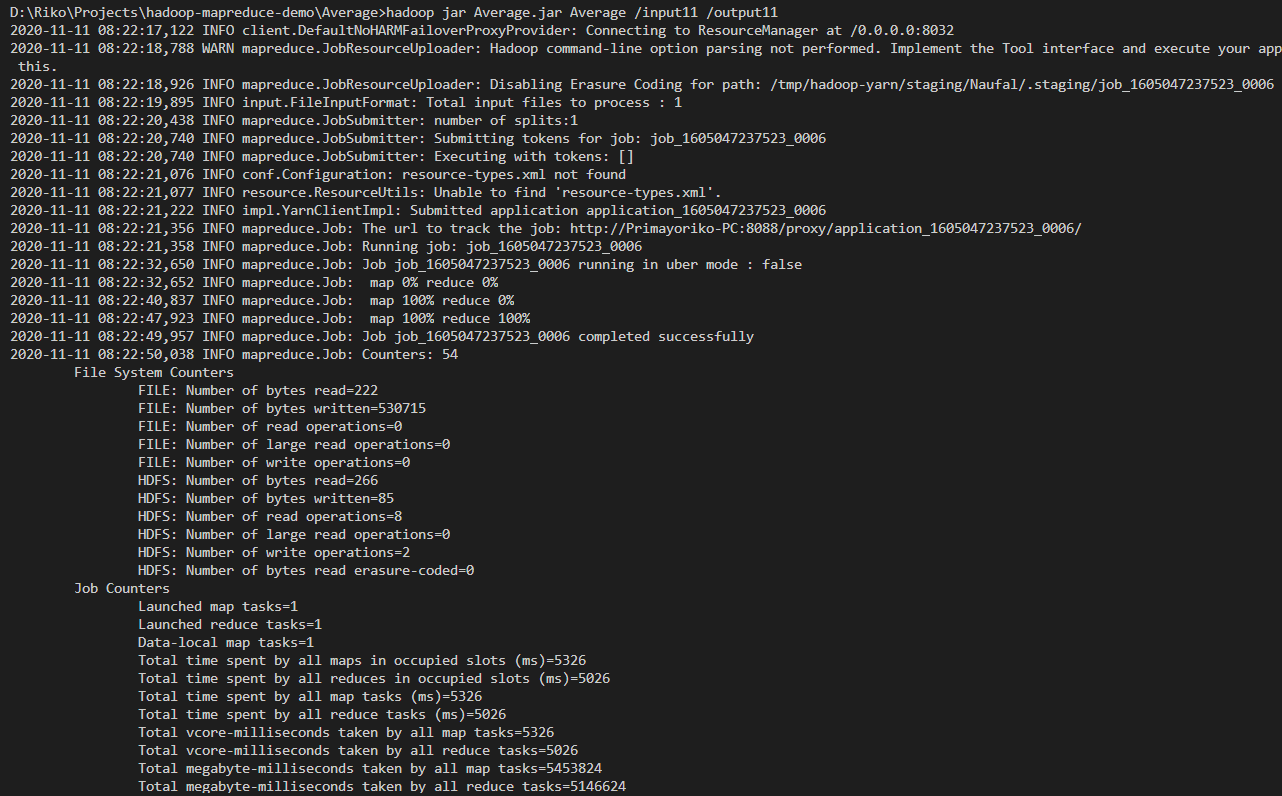
-
After finish, explore the output directory and try to
catfile there, and you should find the result there, as in this example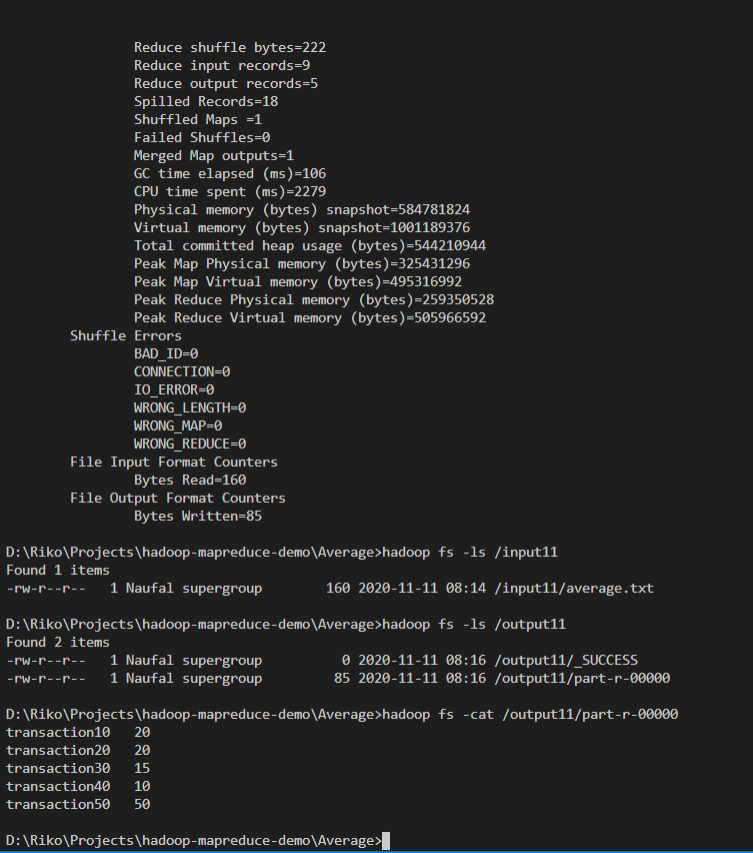



-
Navigate to
TopTenfolder for make it easier -
Compile the java file or
TopTen.javafile and link it with needed hadoop library in%HADOOP_HOME%\share\hadoop, for example with this codejavac -classpath "D:\ProgramData\Hadoop\hadoop-3.3.0\share\hadoop\common\*";"D:\ProgramData\Hadoop\hadoop-3.3.0\share\hadoop\mapreduce\*" -d TopTen/ TopTen.java -
Create jar file from the classes, for example with this code
jar -cvf TopTen.jar -C TopTen/ .
As an example, this is compilation step in my test

-
Make sure that
HDFSandyarnservice already started, by running these command (my advice run in the terminal as ADMINISTRATOR)start-dfs start-yarnI've already included
%HADOOP%_HOME\sbinin the PATH, so that should be work. -
Write the text file that want to be counted, for example
topten.txtthat I want to create here -
Create a directory in hadoop as the input directory, for example here
/input10by running this commandhadoop fs -mkdir /input10 -
Place your text file into hadoop directory that already created (should be empty), for example by this code
hadoop fs -put topten.txt /input10make sure it already created by
lscommand in hadoop, for example by this codehadoop fs -ls /input10it would show something like this,
-
Run hadoop
.jarprogram by input directory is the directory that has just been created, and output directory is a new or non-existent directory, for example by this codehadoop jar TopTen.jar TopTen /input10 /output10just wait first and would show something like this,
-
After finish, explore the output directory and try to
catfile there, and you should find the result there, as in this example