
Atrocious_Mirror_Bot is a multipurpose Telegram Bot writen in Python for mirroring files on the Internet to our beloved Google Drive.
Click Here For More Details
Click here for more details
- qBittorrent
- Size limiting for Torrent/Direct, Tar/Unzip, Mega and clone
- Stop duplicates for all tasks except for qBittorrent and youtube-dl tasks
- Tar/Unzip G-Drive link
- Select files from Torrent before downloading using qbittorrent
- Sudo with or without Database
- Multiple Trackers support
- Extracting tar.xz support
- Counting files/folders from Google Drive link
- View Link button instead of direct download link
- Shell and Executor
- Speedtest
- Status Pages for unlimited tasks
- Clone status
- Search in multiple Drive folder/TD
- Many bugs has been fixed
- Torrent search Supported:
nyaa.si, sukebei, 1337x, piratebay,
tgx, yts, eztv, torlock, rarbg
- Direct links Supported:
letsupload.io, hxfile.co, anonfiles.com, bayfiles.com, antfiles,
fembed.com, fembed.net, femax20.com, layarkacaxxi.icu, fcdn.stream,
sbplay.org, naniplay.com, naniplay.nanime.in, naniplay.nanime.biz, sbembed.com,
streamtape.com, streamsb.net, feurl.com, pixeldrain.com, racaty.net,
1fichier.com, 1drv.ms (Only works for file not folder or business account),
uptobox.com (Uptobox account must be premium), solidfiles.com
Click here for more details
- Mirroring direct download links, Torrent, and Telegram files to Google Drive
- Mirroring Mega.nz links to Google Drive (If you have non-premium Mega account, it will limit download to 5GB per 6 hours)
- Copy files from someone's Drive to your Drive (Using Autorclone)
- Download/Upload progress, Speeds and ETAs
- Mirror all Youtube-dl supported links
- Docker support
- Uploading to Team Drive
- Index Link support
- Service Account support
- Delete files from Drive
- Shortener support
- Custom Filename (Only for direct links, Telegram files and Youtube-dl. Not for Mega links and Torrents)
- Extracting and downloading password protected index links. See these examples:
- Extract these filetypes and uploads to Google Drive
ZIP, RAR, TAR, 7z, ISO, WIM, CAB, GZIP, BZIP2,
APM, ARJ, CHM, CPIO, CramFS, DEB, DMG, FAT,
HFS, LZH, LZMA, LZMA2, MBR, MSI, MSLZ, NSIS,
NTFS, RPM, SquashFS, UDF, VHD, XAR, Z.
Deploying is pretty much straight forward and is divided into several steps as follows:
Click here for more details
- Clone this repo:
git clone https://github.com/Atrocious-Mirror-Bot/Atrocious_Mirror_Bot/
cd mirrorbot
- Install requirements For Debian based distros
sudo apt install python3
Install Docker by following the official Docker docs
OR
sudo snap install docker
- For Arch and it's derivatives:
sudo pacman -S docker python
- Install dependencies for running setup scripts:
pip3 install -r requirements-cli.txt
Click here for more details
cp config_sample.env config.env
- Remove the first line saying:
_____REMOVE_THIS_LINE_____=True
Fill up rest of the fields. Meaning of each fields are discussed below:
BOT_TOKEN: The Telegram bot token that you get from@BotFatherTELEGRAM_API: This is to authenticate to your Telegram account for downloading Telegram files. You can get this fromtelegram.orgDO NOT put this in quotes.TELEGRAM_HASH: This is to authenticate to your Telegram account for downloading Telegram files. You can get this fromtelegram.orgOWNER_ID: The Telegram user ID (not username) of the Owner of the botGDRIVE_FOLDER_ID: This is the folder ID of the Google Drive Folder to which you want to upload all the mirrors.DOWNLOAD_DIR: The path to the local folder where the downloads should be downloaded toDOWNLOAD_STATUS_UPDATE_INTERVAL: A short interval of time in seconds after which the Mirror progress message is updated. (I recommend to keep it5seconds at least)AUTO_DELETE_MESSAGE_DURATION: Interval of time (in seconds), after which the bot deletes it's message (and command message) which is expected to be viewed instantly. (Note: Set to-1to never automatically delete messages)
ACCOUNTS_ZIP_URL: Only if you want to load your Service Account externally from an Index Link. Archive your Service Account json files to a zip file directly (don't archive the accounts folder. Select all the jsons inside and zip them only instead. Name the zip file with whatever you want, it doesn't matter). Fill this with the direct link of that file.TOKEN_PICKLE_URL: Only if you want to load your token.pickle externally from an Index Link. Fill this with the direct link of that file.MULTI_SEARCH_URL: To use search/list in multiple TD/folder. Rundriveid.pyin your terminal and follow it. It will generate a filedrive_folderwhen you finish. Upload that fileherewith the same file name. Open the raw file of that gist, it's URL will be your required config. Check wiki for gist related help.DATABASE_URL: Your Database URL. SeeGenerate Databaseto generate database (NOTE: If you use database you can save your sudo id permanent using/addsudocommand).AUTHORIZED_CHATS: Fill user_id and chat_id (not username) of you want to authorize, Seprate them with space, Examples:-0123456789 -1122334455 6915401739.SUDO_USERS: Fill user_id (not username) of you want to sudoers, Seprate them with space, Examples:0123456789 1122334455 6915401739(NOTE: If you want save sudo id permanent without database, you must fill your sudo id there).IS_TEAM_DRIVE: Set toTrueifGDRIVE_FOLDER_IDis from a Team Drive elseFalseor Leave it empty.USE_SERVICE_ACCOUNTS: (Leave empty if unsure) Whether to use Service Accounts or not. For this to work seeUsing Service Accountssection below.INDEX_URL:Generate IndexMEGA_API_KEY: Mega.nz api key to mirror mega.nz links. Get it fromMega SDK PageMEGA_EMAIL_ID: Your email id you used to sign up on mega.nz for using premium accounts (Leave th)MEGA_PASSWORD: Your password for your mega.nz accountBLOCK_MEGA_FOLDER: If you want to remove mega.nz folder support, set it toTrue.BLOCK_MEGA_LINKS: If you want to remove mega.nz mirror support, set it toTrue.STOP_DUPLICATE: (Leave empty if unsure) if this field is set toTrue, bot will check file in Drive, if it is present in Drive, downloading or cloning will be stopped. (Note: File will be checked using filename, not using filehash, so this feature is not perfect yet)CLONE_LIMIT: To limit cloning Google Drive (leave space between number and unit, Available units is (gb or GB, tb or TB), Examples:100 gb, 100 GB, 10 tb, 10 TBMEGA_LIMIT: To limit downloading Mega (leave space between number and unit, Available units is (gb or GB, tb or TB), Examples:100 gb, 100 GB, 10 tb, 10 TBTORRENT_DIRECT_LIMIT: To limit the Torrent/Direct mirror size, Leave space between number and unit. Available units is (gb or GB, tb or TB), Examples:100 gb, 100 GB, 10 tb, 10 TBTAR_UNZIP_LIMIT: To limit mirroring as Tar or unzipmirror. Available units is (gb or GB, tb or TB), Examples:100 gb, 100 GB, 10 tb, 10 TBVIEW_LINK: View Link button to open file Index Link in browser instead of direct download link, you can figure out if it's compatible with your Index code or not, open any video from you Index and check if the END of link from browser link bar is?a=view, if yes make itTrueit will work (Compatible withBhadoo IndexCode)UPTOBOX_TOKEN: Uptobox token to mirror uptobox links. Get it fromUptobox Premium Account.IGNORE_PENDING_REQUESTS: If you want the bot to ignore pending requests after it restarts, set this toTrue.STATUS_LIMIT: Status limit with buttons (NOTE: Recommend limit status to4tasks max).IS_VPS: (Only for VPS) Don't set this toTrueeven if you are using vps, unless facing error with web server. Also go to start.sh and replace$PORTby80or any port you want to use.SERVER_PORT: (Only if IS_VPS isTrue) Base URL PortBASE_URL_OF_BOT: (Required for Heroku) Valid BASE URL of where the bot is deploy. Ip/domain of your bot likehttp://myipor if you have chosen other port then80thenhttp://myip:port, for Heroku fillhttps://yourappname.herokuapp.com(NOTE: No slash at the end)SHORTENER_API: Fill your Shortener api key if you are using Shortener.SHORTENER: if you want to use Shortener in Gdrive and index link, fill Shortener url here. Examples:
exe.io, gplinks.in, shrinkme.io, urlshortx.com, shortzon.com, bit.ly, shorte.st, linkvertise.com , ouo.io
Above are the supported url Shorteners. Except these only some url Shorteners are supported.
Three buttons are already added of Drive Link, Index Link, and View Link, you can add extra buttons, these are optional, if you don't know what are below entries, simply leave them, don't fill anything in them.
BUTTON_FOUR_NAME:BUTTON_FOUR_URL:BUTTON_FIVE_NAME:BUTTON_FIVE_URL:BUTTON_SIX_NAME:BUTTON_SIX_URL:
Bot commands to be set in @BotFather
Click here for more details
help - Get Detailed Help
mirror - Start Mirroring into googe drive
tgmirror - Start Mirroring into telegram
tar - Start mirroring and upload as .tar
zip - Start mirroring and upload as .zip
unpack - Extract files
qb - Start Mirroring using qBittorrent
qbtar - Start mirroring and upload as .tar using qb
qbzip - Start mirroring and upload as .zip using qb
qbunpack - Extract files using qBittorrent
clone - Copy file/folder to Drive
list - [query] Searches files in Drive
count - Count file/folder of Drive link
watch - Mirror Youtube-dl supported link
tarwatch - Mirror Youtube playlist link and upload as .tar
zipwatch - Mirror Youtube playlist link and upload as .zip
status - Get Mirror Status message
tshelp - Get mirror search
cancel - Cancel a task
stats - Bot Usage Stats
ping - Ping the Bot
Click here for more details
IMPORTANT NOTE: In start.sh you must replace $PORT with 80 or any other port you want to use
- Start Docker daemon (skip if already running):
sudo dockerd
- Build Docker image:
sudo docker build . -t mirror-bot
- Run the image:
sudo docker run -p 80:80 mirror-bot
OR
NOTE: If you want to use port other than 80, so change it in docker-compose.yml
- Using Docker-compose so you can edit and build your image in seconds:
sudo apt install docker-compose
- Build and run Docker image:
sudo docker-compose up
- After edit files with nano for example (nano start.sh):
sudo docker-compose build
sudo docker-compose up
or
sudo docker-compose up --build
- To stop docker run
sudo docker ps
sudo docker stop id
- To clear the container (this will not effect on image):
sudo docker container prune
- To delete the image:
sudo docker image prune -a
- Video from Tortoolkit repo
Click here for more details
token.pickleHerokuaccounts- Recommended to use 1 App in 1 Heroku account
- Don't use bin/fake credits card, because your Heroku account will get banned.
-
Give a star and Fork this repo then upload token.pickle to your forks, or you can upload your token.pickle to your Index and put your token.pickle link to
TOKEN_PICKLE_URL(NOTE: If you don't upload token.pickle uploading will not work). -
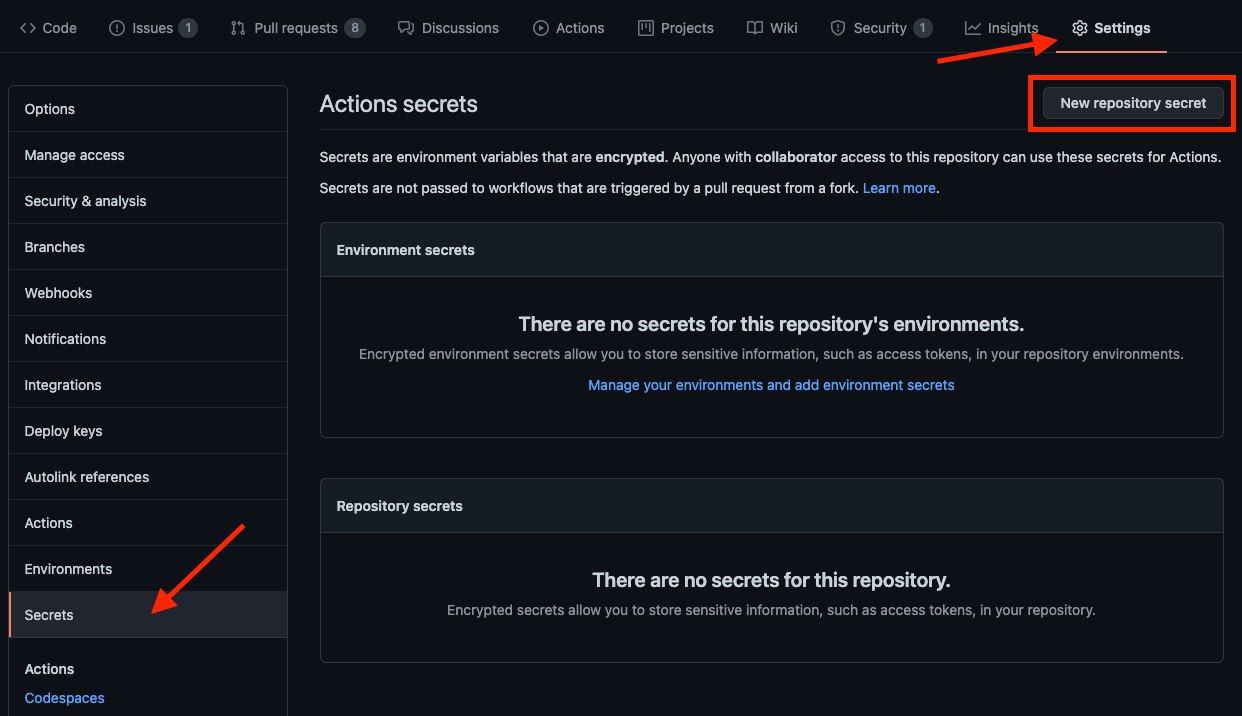
Go to Repository
Settings->Secrets -
Add the below Required Variables one by one by clicking
New Repository Secreteverytime.HEROKU_API_KEYYour Heroku API key, get it fromDasboard HerokuHEROKU_APP_NAMEYour Heroku app name, Name Must be uniqueCONFIG_FILE_URLFillThisin any text editor. Remove the_____REMOVE_THIS_LINE_____=Trueline and fill the variables. Go toGistand paste your config data. Rename the file toconfig.envthen create secret gist. Click on Raw, copy the link. This will be yourCONFIG_FILE_URL. Refer to below images for clarity.

- NOTE: Remove commit id from raw link to be able to change variables without updating the
CONFIG_FILE_URLin secrets. should be in this form:https://gist.githubusercontent.com/username/gist-id/raw/config.env- Before:
https://gist.githubusercontent.com/vincreator/ab5b0cb5d73f8992590ac732f0780f5c/raw/fe8162eddaec32d2408024efdf9ea8fc70028ed9/config.env - After:
https://gist.githubusercontent.com/vincreator/ab5b0cb5d73f8992590ac732f0780f5c/raw/config.env - You only need to restart your bot after editing
config.envgist secret.
- Before:
-
After adding all the above Required Variables go to Github Actions tab in your repo
-
Select
Containerworkflow as shown below: -
Then click on Run workflow
-
Done! your bot will be deployed now.


- Don't change/edit variables from Heroku if you want to change/edit do it from
config.env - If got suspend apps after deploy just delete your apps and make it new with same name, then do
Containeragain
Click here for more details
- Install
Heroku cli - Login into your heroku account with command:
heroku login
- Create a new heroku app:
heroku create appname
- Select This App in your Heroku-cli:
heroku git:remote -a appname
- Change Dyno Stack to a Docker Container:
heroku stack:set container -a appname
- Clone this repo:
git clone https://github.com/Atrocious-Mirror-Bot/Atrocious_Mirror_Bot
ls
cd eunha
git init
- Add all stuff:
git add .
git add * -f
git add .gitignore
- Commit new changes:
git commit -m "EunhaMirror Updates"
- Push Code to Heroku:
git push heroku master
- Restart Worker by these commands or you can Do it manually too in heroku.
- For Turning off the Bot:
heroku ps:scale web=0 -a appname
- For Turning on the Bot:
heroku ps:scale web=1 -a appname
- Note:
- Deploy 2 Times to unsuspend (Delete your apps and make it new with same name)
- Don't add config on heroku, Use
config.env
Click here for more details
- Visit the
Google Cloud Console - Go to the OAuth Consent tab, fill it, and save.
- Go to the Credentials tab and click Create Credentials -> OAuth Client ID
- Choose Desktop and Create.
- Use the download button to download your credentials.
- Move that file to the root of Eunhabot, and rename it to credentials.json
- Visit
Google API page - Search for Drive and enable it if it is disabled
- Finally, run the script to generate token.pickle file for Google Drive:
pip install google-api-python-client google-auth-httplib2 google-auth-oauthlib
python3 generate_drive_token.py
Click here for more details
1. Using ElephantSQL
- Go to
ElephantSqland create account (skip this if you already have ElephantSQL account) - Hit
Create New Instance - Follow the further instructions in the screen
- Hit
Select Region - Hit
Review - Hit
Create instance - Select your database name
- Copy your database url, and fill to
DATABASE_URLinconfig.env
2. Using Clever
- Go to
Cleverand create account by sign-up (skip this if you already have) - Directly go to your
console(Make sure use Desktop Version on your browser) - Click on
Personal spaceand click button+ Createthen choosean add-on - Select
PostgresSQL(With logo elephant) - Choose
PLAN NAME DEVjust click on it and scroll down then clickNext - Select on
Paris Franceand put the name of your database (what ever you want) then clickNext - On Addon dashboard go to
CONNECTION URIcopy and fill toDATABASE_URLinconfig.env
Click here for more details
For Service Account to work, you must set USE_SERVICE_ACCOUNTS="True" in config file or environment variables,
Many thanks to AutoRClone for the scripts.
NOTE: Using Service Accounts is only recommended while uploading to a Team Drive.
Click here for more details
Let us create only the Service Accounts that we need. Warning: abuse of this feature is not the aim of this project and we do NOT recommend that you make a lot of projects, just one project and 100 SAs allow you plenty of use, its also possible that over abuse might get your projects banned by Google.
NOTE: 1 Service Account can copy around 750gb a day, 1 project can make 100 Service Accounts so that's 75tb a day, for most users this should easily suffice.
python3 gen_sa_accounts.py --quick-setup 1 --new-only
A folder named accounts will be created which will contain keys for the Service Accounts.
Or you can create Service Accounts to current project, no need to create new one
- List your projects ids
python3 gen_sa_accounts.py --list-projects
- Enable services automatically by this command
python3 gen_sa_accounts.py --enable-services $PROJECTID
- Create Sevice Accounts to current project
python3 gen_sa_accounts.py --create-sas $PROJECTID
- Download Sevice Accounts as accounts folder
python3 gen_sa_accounts.py --download-keys $PROJECTID
If you want to add Service Accounts to Google Group, follow these steps
- Mount accounts folder
cd accounts
- Grab emails form all accounts to emails.txt file that would be created in accounts folder
grep -oPh '"client_email": "\K[^"]+' *.json > emails.txt
- Unmount acounts folder
cd -
Then add emails from emails.txt to Google Group, after that add Google Group to your Shared Drive and promote it to manager.
NOTE: If you have created SAs in past from this script, you can also just re download the keys by running:
python3 gen_sa_accounts.py --download-keys project_id
Click here for more details
- Run:
python3 add_to_team_drive.py -d SharedTeamDriveSrcID
Click here for more details
For using your premium accounts in Youtube-dl or for protected Index Links, edit the netrc file according to following format:
machine host login username password my_youtube_password
For Index Link with only password without username, even http auth will not work, so this is the solution.
machine example.workers.dev password index_password
Where host is the name of extractor (eg. Youtube, Twitch). Multiple accounts of different hosts can be added each separated by a new line.
this function is to turn on your bot so it doesn't fall asleep.
Click here for more details
choose one of these:
Cron JobJust put your app linkUptime RobotJust put your app linkKaffeineJust put your app linkPingDomJust put your app link
Recommended Index repo for Atrocious Mirror Bot
Click here for more details
Bhadoo Indexby ParveenGDIndexby maple3142goindexby alx-xlxgoIndex-theme-nexmoeby 5MayRain
NOTE: If you any problem with your Index, report the problem to dev Index repo which you use it.
Thanks to:
Click here for more details
out386heavily inspired from Telegram Bot which is written in JSIzzy12for original repojaskaranSMfor build up this bot from scratchDank-delfor base repomagneto261290for some featuresSVR666for some features & fixesanasty17for some features & helpbreakdownsfor slam-aria-mirror-botzevtyardtfor some direct linksyash-dkfor implementation qBittorrent on Python
And many more people who aren't mentioned here, but may be found in Contributors.