Introducing a Data Pipeline Project that integrates Airflow for Data Orchestration
- Apache Airflow: Apache Airflow is an open-source platform for authoring, scheduling and monitoring data and computing workflows. For this project it was used to manage data extraction and transformation process
- Snowflake: This is a cloud-based data warehousing platform for data storage and analytics purpose. For this project it was used to query datasets loaded automatically from S3
- Snowpipe: Snowpipe is a serverless data ingestion service offered by Snowflake, designed to simplify the process of loading data into Snowflake data warehouses. For this project it was used to automatically load data into snowflake table from stage environment.
- AWS EC2 : This is a cloud-based computing service that allows users to quickly launch virtual servers and manage cookies, security, and networking from an easy-to-use dashboard. It was used to host Airflow server for this project.
- AWS S3: This is a highly scalable object storage service that stores data as objects within buckets. It is commonly used to store and distribute large media files, data backups and static website files. For this project it is used to store data scraped from target website.
- AWS SQS: This is a message queuing service. It exchanges and stores messages between software components. The service adds the messages in a queue. Users or services pick up the messages from the queue. Once processed the messages gets deleted from the queue. In this project it was used to receive notifications from S3 to an SQS queue to be read by the Snowflake server.

- Python
Data was scraped from this website using Scrapy.
The website does not provide a public API, hence it was reverse engineered to get the endpoint. Postman was then used to analyze endpoint
-
Create EC2 Instance (AWS Ubuntu Server) with at least 4gb RAM as requested by airflow installation requirements - preferable t3.medium
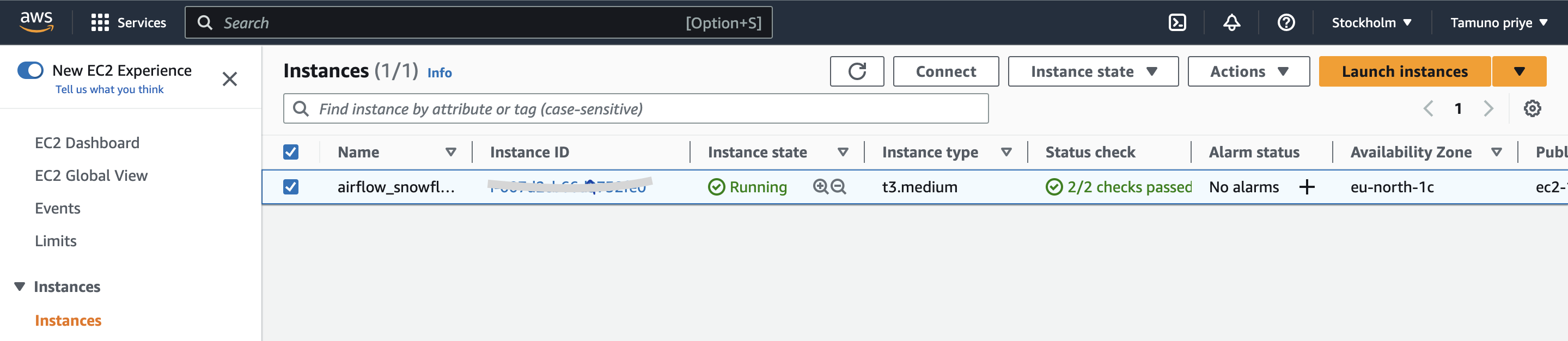
-
Install Airflow and other libraries on ec2 Instance. Use commands here to install dependencies and start airflow server. Clone dags from this repository into your ubuntu directory using git. This will allow you to access the scraper and dag code on your server. Airflow UI can then be accessed using this url format -
http://<public dns address>:8080
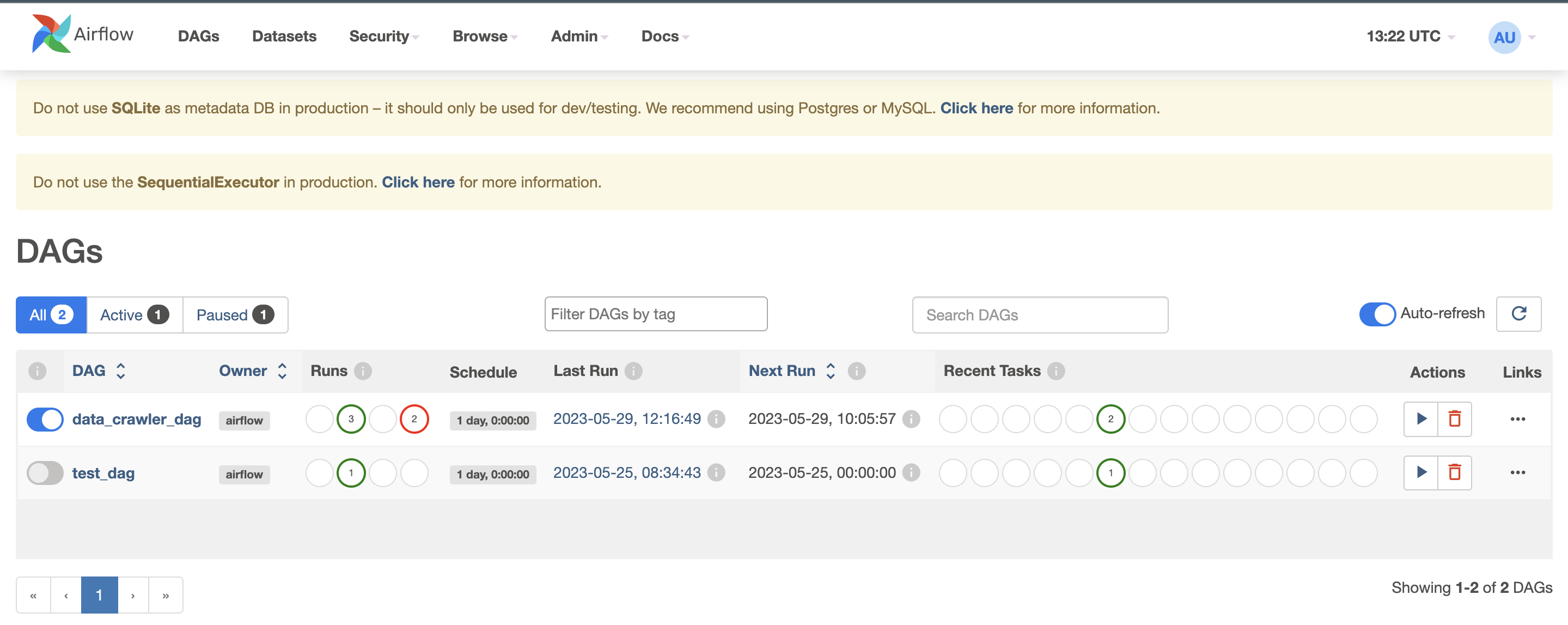
-
Create a snowflake account here , also create database, staging environment for incoming files on snowflake, table and pipe to copy data from stage to snowflakes table. Data pipelines can leverage Snowpipe to continously load micro-batches of data into tables for automated tasks. Follow commands here to create database, tables, etc.
-
Create S3 Bucket and IAM role to enable access to s3 from any instance, take note of the AWS key and secret key
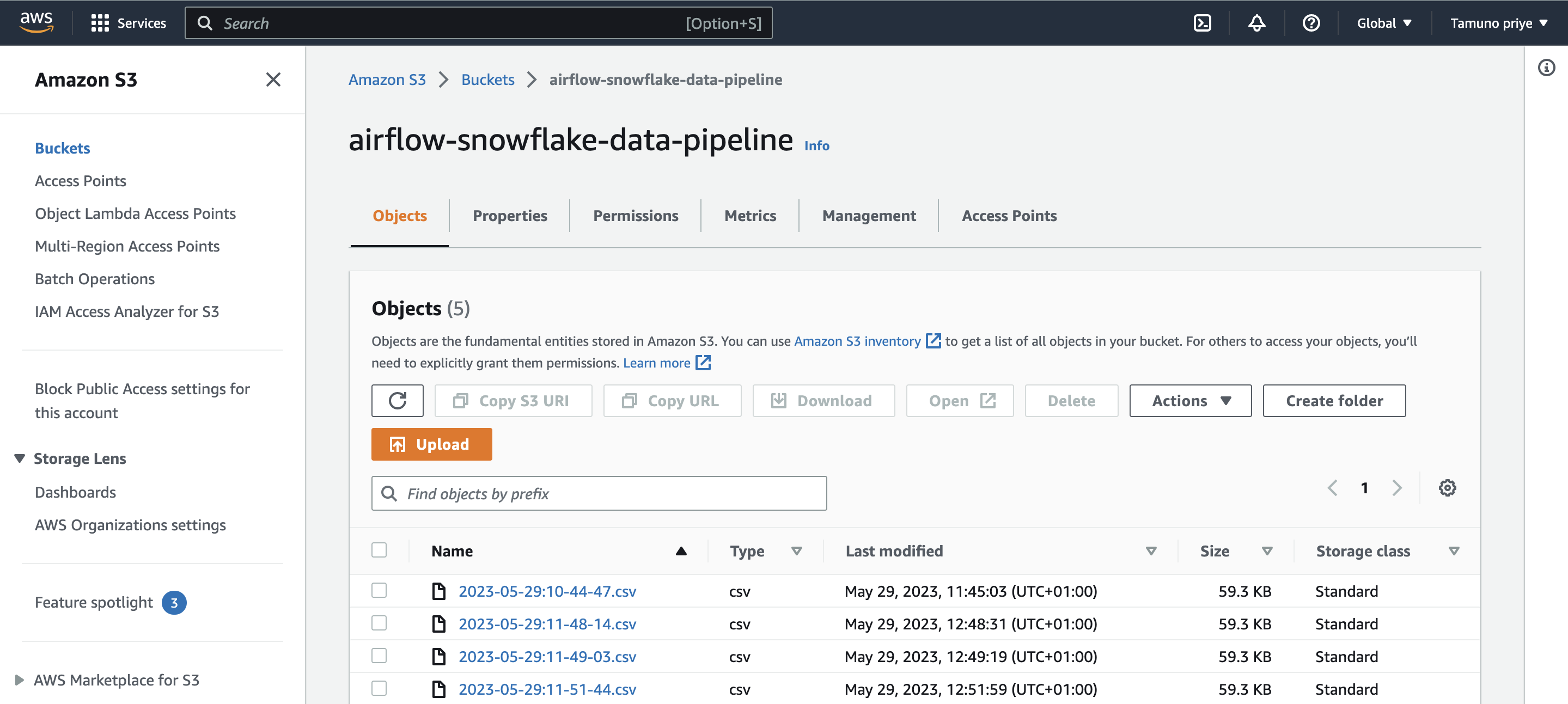
-
Set up AWS SQS for all bucket create operations
To enable the bucket to notify Snowpipe when new data arrives. This can be done by executing the query “show pipes;” in snowflakes worksheet, copying the notification_channel(ARN) value from the newly created pipe, and pasting it into the AWS SQS.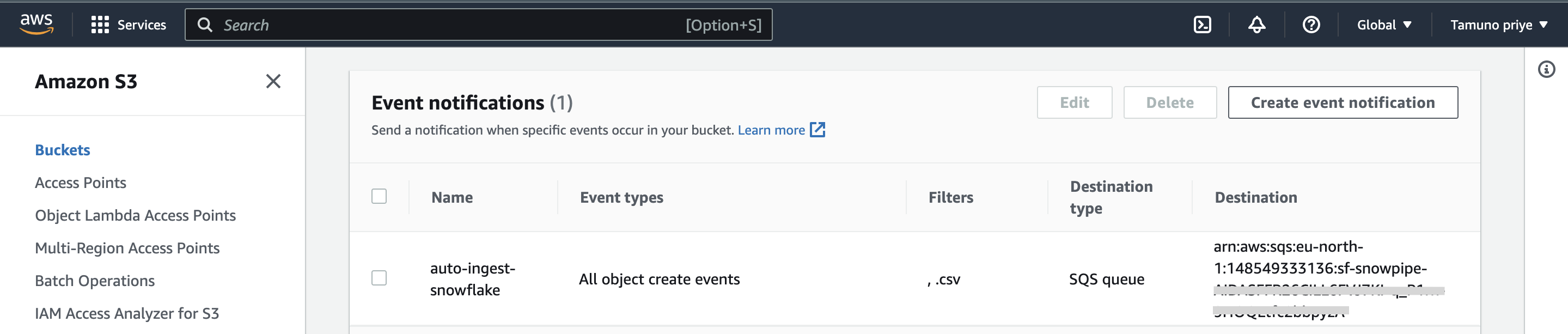
-
Trigger dag manually from the UI and access Snowflake worksheet to preview data, with time the number of rows increases if airflow task is set to run on a schedule.






start Airflow server-> Trigger data crawler Dag -> Crawler starts -> loads data into s3 -> snowpipe loads data into table from s3
- Ubuntu commands for Airflow setup can be found here
- Airflow and scrapy code can be found here This should run in your environment if set up correctly
- Snowflake queries can be found here