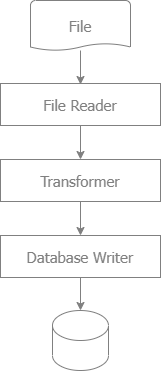
In this demo, we import 1 Million Records into SQL from CSV Fixed-Length Format Files with high performance in GOLANG.
This article outlines strategies for high-performance batch processing in GOLANG, specifically for importing 1 million records into PostgreSQL from a CSV or fixed-length format file.
- RAM: 12 GB
- Disk: SSD KINGSTON SA400S37240G ATA Device
- Exec File Size: 12M
- Database: PosgreSQL 16
- Total of rows: 1,018,584 rows
- Total of columns: 76 columns.
- 20% of columns are datetime, it means to take time to parse string to datetime.
- Power Usage: Moderate
Results to import 1,018,584 rows into PostgreSQL:
| Type | File Size | CPU | RAM | Disk | Without data validation | With data validation |
| Fix Length | 1.15 GB | 6.6% | 33 M | 3.1 M/s | 5 min 16 sec | 6 min 10 sec |
| Delimiter | 0.975 GB | 8% | 34 M | 2.8 M/s | 5 min 9 sec | 5 min 57 sec |
| CSV | 0.975 GB | 5.2% | 26 M | 3 M/s | 5 min 12 sec | 5 min 58 sec |
- For fix length format file, please unzip 'data/fixedlength_big.7z' file (1.15 GB)
- For CSV file, please unzip 'data/delimiter_big.7z' file (0.975 GB)
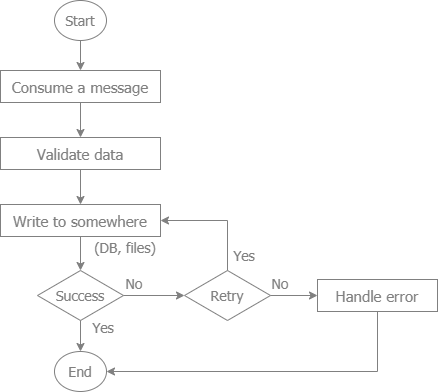
Differ from online processing:
- Long time running, often at night, after working hours.
- Non-interactive, often include logic for handling errors
- Large volumes of data
- Data Size: Large volumes can strain memory and I/O performance.
- Database Constraints: SQL (Postgres, My SQL, MS SQL...) may struggle with handling high transaction loads.
- Instead of loading the entire file into memory, stream the file line by line using Go's buffered I/O. This reduces memory consumption.
- Example: Use bufio.Scanner to read records line by line.
Bulk inserts in SQL are typically faster because they reduce the overhead associated with individual inserts. Here’s why:
- Transaction Handling: In a bulk insert, multiple rows are inserted in a single transaction, reducing the need for multiple commits, which can be expensive in terms of I/O operations.
- Logging: Bulk inserts often minimize logging overhead, especially if the database is configured to use minimal logging for bulk operations (like in SQL Server with the "BULK_LOGGED" recovery model).
- Constraints: When inserting data in bulk, constraints such as foreign keys and unique indexes may be deferred or optimized by the database engine.
- Index Updates: Instead of updating indexes after each row insert, bulk inserts allow the database to update indexes in batches, improving performance.
However, it’s important to note that bulk inserts still need to ensure data integrity. Some databases provide options to temporarily disable constraints or logging to optimize performance further, but this can lead to data consistency issues if not handled properly.
- Insert records into PostgreSQL in batches (e.g., 1000 records per transaction). This reduces transaction overhead and improves performance.
- In this sample, we use Batch Inserts. We still have a very good performance.
- Implement robust error handling and logging. Track failed records to reprocess or fix them later.
By carefully handling file I/O, database interactions, and error management, you can ensure high performance when importing large datasets into SQL.
- Popular for web development
- Suitable for Import Flow
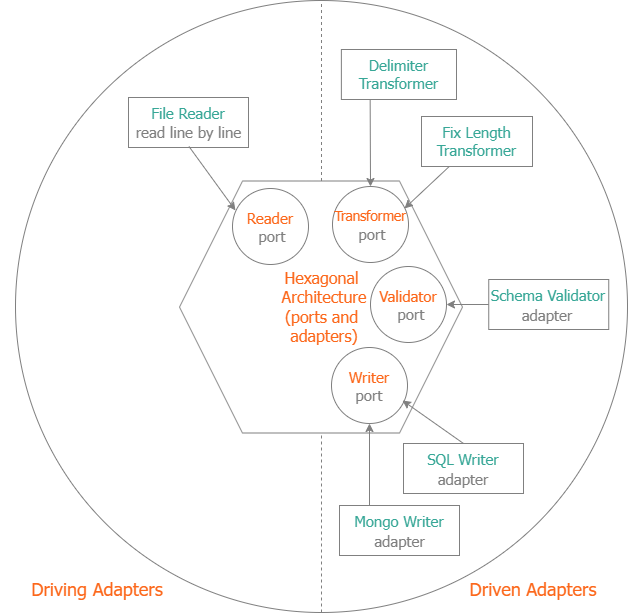
- Reader, Validator, Transformer, Writer
Reader Adapter Sample: File Reader. We provide 2 file reader adapters:
- Delimiter (CSV format) File Reader
- Fix Length File Reader
- Validator Adapter Sample: Schema Validator
- We provide the Schema validator based on GOLANG Tags
We provide 2 transformer adapters
- Delimiter Transformer (CSV)
- Fix Length Transformer
We provide many writer adapters:
-
SQL:
- SQL Writer: to insert or update data
- SQL Inserter: to insert data
- SQL Updater: to update data
- SQL Stream Writer: to insert or update data. When you write data, it keeps the data in the buffer, it does not write data. It just writes data when flush.
- SQL Stream Inserter: to insert data. When you write data, it keeps the data in the buffer, it does not write data. It just writes data when flush. Especially, we build 1 single SQL statement to improve the performance.
- SQL Stream Updater: to update data. When you write data, it keeps the data in the buffer, it does not write data. It just writes data when flush.
-
Mongo:
- Mongo Writer: to insert or update data
- Mongo Inserter: to insert data
- Mongo Updater: to update data
- Mongo Stream Writer: to insert or update data. When you write data, it keeps the data in the buffer, it does not write data. It just writes data when flush.
- Mongo Stream Inserter: to insert data. When you write data, it keeps the data in the buffer, it does not write data. It just writes data when flush.
- Mongo Stream Updater: to update data. When you write data, it keeps the data in the buffer, it does not write data. It just writes data when flush.
-
Elastic Search
- Elastic Search Writer: to insert or update data
- Elastic Search Creator: to create data
- Elastic Search Updater: to update data
- Elastic Search Stream Writer: to insert or update data. When you write data, it keeps the data in the buffer, it does not write data. It just writes data when flush.
- Elastic Search Stream Creator: to create data. When you write data, it keeps the data in the buffer, it does not write data. It just writes data when flush.
- Elastic Search Stream Updater: to update data. When you write data, it keeps the data in the buffer, it does not write data. It just writes data when flush.
-
Firestore
- Firestore Writer: to insert or update data
- Firestore Updater: to update data
-
Cassandra
- Cassandra Writer: to insert or update data
- Cassandra Inserter: to insert data
- Cassandra Updater: to update data
-
Hive
- Hive Writer: to insert or update data
- Hive Inserter: to insert data
- Hive Updater: to update data
- Hive Stream Updater: to update data. When you write data, it keeps the data in the buffer, it does not write data. It just writes data when flush.