![]()
LangChain-Chatchat (原 Langchain-ChatGLM): 基于 Langchain 与 ChatGLM 等大语言模型的本地知识库问答应用实现。
🤖️ 一种利用 langchain **实现的基于本地知识库的问答应用,目标期望建立一套对中文场景与开源模型支持友好、可离线运行的知识库问答解决方案。
💡 受 GanymedeNil 的项目 document.ai 和 AlexZhangji 创建的 ChatGLM-6B Pull Request 启发,建立了全流程可使用开源模型实现的本地知识库问答应用。本项目的最新版本中通过使用 FastChat 接入 Vicuna, Alpaca, LLaMA, Koala, RWKV 等模型,依托于 langchain 框架支持通过基于 FastAPI 提供的 API 调用服务,或使用基于 Streamlit 的 WebUI 进行操作。
✅ 依托于本项目支持的开源 LLM 与 Embedding 模型,本项目可实现全部使用开源模型离线私有部署。与此同时,本项目也支持 OpenAI GPT API 的调用,并将在后续持续扩充对各类模型及模型 API 的接入。
⛓️ 本项目实现原理如下图所示,过程包括加载文件 -> 读取文本 -> 文本分割 -> 文本向量化 -> 问句向量化 -> 在文本向量中匹配出与问句向量最相似的 top k个 -> 匹配出的文本作为上下文和问题一起添加到 prompt中 -> 提交给 LLM生成回答。
📺 原理介绍视频

从文档处理角度来看,实现流程如下:

🚩 本项目未涉及微调、训练过程,但可利用微调或训练对本项目效果进行优化。
🌐 AutoDL 镜像 中 v5 版本所使用代码已更新至本项目 0.2.0 版本。
💻 一行命令运行 Docker:
docker run -d --gpus all -p 80:8501 registry.cn-beijing.aliyuncs.com/chatchat/chatchat:0.2.0参见 版本更新日志。
从 0.1.x 升级过来的用户请注意,需要按照开发部署过程操作,将现有知识库迁移到新格式,具体见知识库初始化与迁移。
- 使用 FastChat 提供开源 LLM 模型的 API,以 OpenAI API 接口形式接入,提升 LLM 模型加载效果;
- 使用 langchain 中已有 Chain 的实现,便于后续接入不同类型 Chain,并将对 Agent 接入开展测试;
- 使用 FastAPI 提供 API 服务,全部接口可在 FastAPI 自动生成的 docs 中开展测试,且所有对话接口支持通过参数设置流式或非流式输出;
- 使用 Streamlit 提供 WebUI 服务,可选是否基于 API 服务启动 WebUI,增加会话管理,可以自定义会话主题并切换,且后续可支持不同形式输出内容的显示;
- 项目中默认 LLM 模型改为 THUDM/chatglm2-6b,默认 Embedding 模型改为 moka-ai/m3e-base,文件加载方式与文段划分方式也有调整,后续将重新实现上下文扩充,并增加可选设置;
- 项目中扩充了对不同类型向量库的支持,除支持 FAISS 向量库外,还提供 Milvus, PGVector 向量库的接入;
- 项目中搜索引擎对话,除 Bing 搜索外,增加 DuckDuckGo 搜索选项,DuckDuckGo 搜索无需配置 API Key,在可访问国外服务环境下可直接使用。
本项目中默认使用的 LLM 模型为 THUDM/chatglm2-6b,默认使用的 Embedding 模型为 moka-ai/m3e-base 为例。
本项目最新版本中基于 FastChat 进行本地 LLM 模型接入,支持模型如下:
- meta-llama/Llama-2-7b-chat-hf
- Vicuna, Alpaca, LLaMA, Koala
- BlinkDL/RWKV-4-Raven
- camel-ai/CAMEL-13B-Combined-Data
- databricks/dolly-v2-12b
- FreedomIntelligence/phoenix-inst-chat-7b
- h2oai/h2ogpt-gm-oasst1-en-2048-open-llama-7b
- lcw99/polyglot-ko-12.8b-chang-instruct-chat
- lmsys/fastchat-t5-3b-v1.0
- mosaicml/mpt-7b-chat
- Neutralzz/BiLLa-7B-SFT
- nomic-ai/gpt4all-13b-snoozy
- NousResearch/Nous-Hermes-13b
- openaccess-ai-collective/manticore-13b-chat-pyg
- OpenAssistant/oasst-sft-4-pythia-12b-epoch-3.5
- project-baize/baize-v2-7b
- Salesforce/codet5p-6b
- StabilityAI/stablelm-tuned-alpha-7b
- THUDM/chatglm-6b
- THUDM/chatglm2-6b
- tiiuae/falcon-40b
- timdettmers/guanaco-33b-merged
- togethercomputer/RedPajama-INCITE-7B-Chat
- WizardLM/WizardLM-13B-V1.0
- WizardLM/WizardCoder-15B-V1.0
- baichuan-inc/baichuan-7B
- internlm/internlm-chat-7b
- Qwen/Qwen-7B-Chat
- HuggingFaceH4/starchat-beta
- 任何 EleutherAI 的 pythia 模型,如 pythia-6.9b
- 在以上模型基础上训练的任何 Peft 适配器。为了激活,模型路径中必须有
peft。注意:如果加载多个peft模型,你可以通过在任何模型工作器中设置环境变量PEFT_SHARE_BASE_WEIGHTS=true来使它们共享基础模型的权重。
以上模型支持列表可能随 FastChat 更新而持续更新,可参考 FastChat 已支持模型列表。
除本地模型外,本项目也支持直接接入 OpenAI API,具体设置可参考 configs/model_configs.py.example 中的 llm_model_dict 的 openai-chatgpt-3.5 配置信息。
本项目支持调用 HuggingFace 中的 Embedding 模型,已支持的 Embedding 模型如下:
- moka-ai/m3e-small
- moka-ai/m3e-base
- moka-ai/m3e-large
- BAAI/bge-small-zh
- BAAI/bge-base-zh
- BAAI/bge-large-zh
- text2vec-base-chinese-sentence
- text2vec-base-chinese-paraphrase
- text2vec-base-multilingual
- shibing624/text2vec-base-chinese
- GanymedeNil/text2vec-large-chinese
- nghuyong/ernie-3.0-nano-zh
- nghuyong/ernie-3.0-base-zh
🐳 Docker 镜像地址: registry.cn-beijing.aliyuncs.com/chatchat/chatchat:0.2.0)
docker run -d --gpus all -p 80:8501 registry.cn-beijing.aliyuncs.com/chatchat/chatchat:0.2.0- 该版本镜像大小
33.9GB,使用v0.2.0,以nvidia/cuda:12.1.1-cudnn8-devel-ubuntu22.04为基础镜像 - 该版本内置一个
embedding模型:m3e-large,内置chatglm2-6b-32k - 该版本目标为方便一键部署使用,请确保您已经在Linux发行版上安装了NVIDIA驱动程序
- 请注意,您不需要在主机系统上安装CUDA工具包,但需要安装
NVIDIA Driver以及NVIDIA Container Toolkit,请参考安装指南 - 首次拉取和启动均需要一定时间,首次启动时请参照下图使用
docker logs -f <container id>查看日志 - 如遇到启动过程卡在
Waiting..步骤,建议使用docker exec -it <container id> bash进入/logs/目录查看对应阶段日志
本项目已在 Python 3.8.1 - 3.10,CUDA 11.7 环境下完成测试。已在 Windows、ARM 架构的 macOS、Linux 系统中完成测试。
参见 开发环境准备。
请注意: 0.2.0 及更新版本的依赖包与 0.1.x 版本依赖包可能发生冲突,强烈建议新建环境后重新安装依赖包。
如需在本地或离线环境下运行本项目,需要首先将项目所需的模型下载至本地,通常开源 LLM 与 Embedding 模型可以从 HuggingFace 下载。
以本项目中默认使用的 LLM 模型 THUDM/chatglm2-6b 与 Embedding 模型 moka-ai/m3e-base 为例:
下载模型需要先安装Git LFS,然后运行
$ git clone https://huggingface.co/THUDM/chatglm2-6b
$ git clone https://huggingface.co/moka-ai/m3e-base复制模型相关参数配置模板文件 configs/model_config.py.example 存储至项目路径下 ./configs 路径下,并重命名为 model_config.py。
复制服务相关参数配置模板文件 configs/server_config.py.example 存储至项目路径下 ./configs 路径下,并重命名为 server_config.py。
在开始执行 Web UI 或命令行交互前,请先检查 configs/model_config.py 和 configs/server_config.py 中的各项模型参数设计是否符合需求:
- 请确认已下载至本地的 LLM 模型本地存储路径写在
llm_model_dict对应模型的local_model_path属性中,如:
llm_model_dict={
"chatglm2-6b": {
"local_model_path": "/Users/xxx/Downloads/chatglm2-6b",
"api_base_url": "http://localhost:8888/v1", # "name"修改为 FastChat 服务中的"api_base_url"
"api_key": "EMPTY"
},
}- 请确认已下载至本地的 Embedding 模型本地存储路径写在
embedding_model_dict对应模型位置,如:
embedding_model_dict = {
"m3e-base": "/Users/xxx/Downloads/m3e-base",
}当前项目的知识库信息存储在数据库中,在正式运行项目之前请先初始化数据库(我们强烈建议您在执行操作前备份您的知识文件)。
-
如果您是从
0.1.x版本升级过来的用户,针对已建立的知识库,请确认知识库的向量库类型、Embedding 模型configs/model_config.py中默认设置一致,如无变化只需以下命令将现有知识库信息添加到数据库即可:$ python init_database.py
-
如果您是第一次运行本项目,知识库尚未建立,或者配置文件中的知识库类型、嵌入模型发生变化,需要以下命令初始化或重建知识库:
$ python init_database.py --recreate-vs
如需使用开源模型进行本地部署,需首先启动 LLM 服务,启动方式分为三种:
三种方式只需选择一个即可,具体操作方式详见 5.1.1 - 5.1.3。
如果启动在线的API服务(如 OPENAI 的 API 接口),则无需启动 LLM 服务,即 5.1 小节的任何命令均无需启动。
在项目根目录下,执行 server/llm_api.py 脚本启动 LLM 模型服务:
$ python server/llm_api.py项目支持多卡加载,需在 llm_api.py 中修改 create_model_worker_app 函数中,修改如下三个参数:
gpus=None,
num_gpus=1,
max_gpu_memory="20GiB"其中,gpus 控制使用的显卡的ID,如果 "0,1";
num_gpus 控制使用的卡数;
max_gpu_memory 控制每个卡使用的显存容量。
1.llm_api_stale.py脚本原生仅适用于linux,mac设备需要安装对应的linux命令,win平台请使用wls;
2.加载非默认模型需要用命令行参数--model-path-address指定模型,不会读取model_config.py配置;
在项目根目录下,执行 server/llm_api_stale.py 脚本启动 LLM 模型服务:
$ python server/llm_api_stale.py该方式支持启动多个worker,示例启动方式:
$ python server/llm_api_stale.py --model-path-address model1@host1@port1 model2@host2@port2如果出现server端口占用情况,需手动指定server端口,并同步修改model_config.py下对应模型的base_api_url为指定端口:
$ python server/llm_api_stale.py --server-port 8887如果要启动多卡加载,示例命令如下:
$ python server/llm_api_stale.py --gpus 0,1 --num-gpus 2 --max-gpu-memory 10GiB注:以如上方式启动LLM服务会以nohup命令在后台运行 FastChat 服务,如需停止服务,可以运行如下命令:
$ python server/llm_api_shutdown.py --serve all 亦可单独停止一个 FastChat 服务模块,可选 [all, controller, model_worker, openai_api_server]
本项目基于 FastChat 加载 LLM 服务,故需以 FastChat 加载 PEFT 路径,即保证路径名称里必须有 peft 这个词,配置文件的名字为 adapter_config.json,peft 路径下包含 model.bin 格式的 PEFT 权重。
示例代码如下:
PEFT_SHARE_BASE_WEIGHTS=true python3 -m fastchat.serve.multi_model_worker \
--model-path /data/chris/peft-llama-dummy-1 \
--model-names peft-dummy-1 \
--model-path /data/chris/peft-llama-dummy-2 \
--model-names peft-dummy-2 \
--model-path /data/chris/peft-llama-dummy-3 \
--model-names peft-dummy-3 \
--num-gpus 2本地部署情况下,按照 5.1 节启动 LLM 服务后,再执行 server/api.py 脚本启动 API 服务;
在线调用API服务的情况下,直接执执行 server/api.py 脚本启动 API 服务;
调用命令示例:
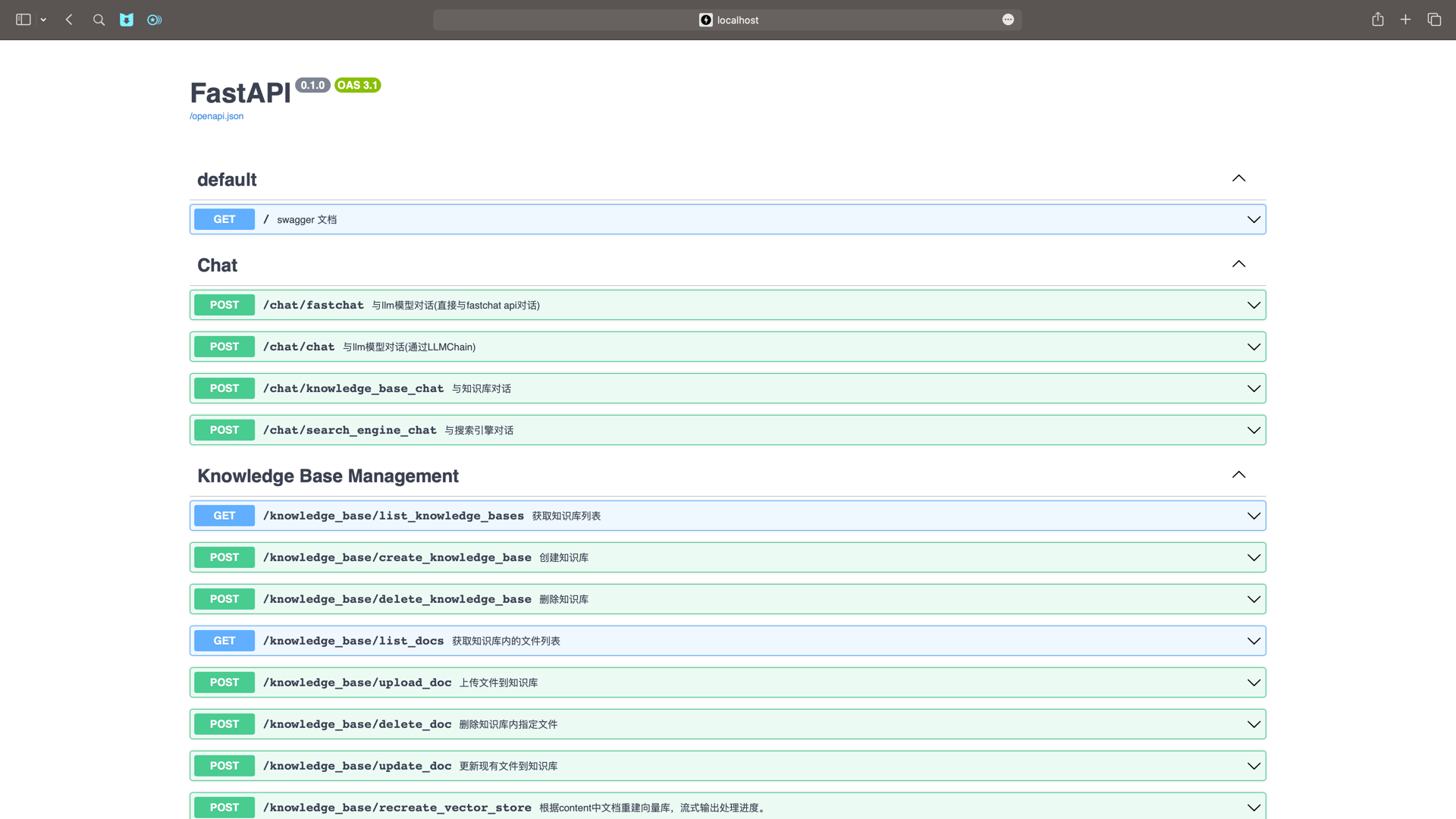
$ python server/api.py启动 API 服务后,可访问 localhost:7861 或 {API 所在服务器 IP}:7861 FastAPI 自动生成的 docs 进行接口查看与测试。
-
FastAPI docs 界面

按照 5.2 节启动 API 服务后,执行 webui.py 启动 Web UI 服务(默认使用端口 8501)
$ streamlit run webui.py使用 Langchain-Chatchat 主题色启动 Web UI 服务(默认使用端口 8501)
$ streamlit run webui.py --theme.base "light" --theme.primaryColor "#165dff" --theme.secondaryBackgroundColor "#f5f5f5" --theme.textColor "#000000"或使用以下命令指定启动 Web UI 服务并指定端口号
$ streamlit run webui.py --server.port 666-
Web UI 对话界面:

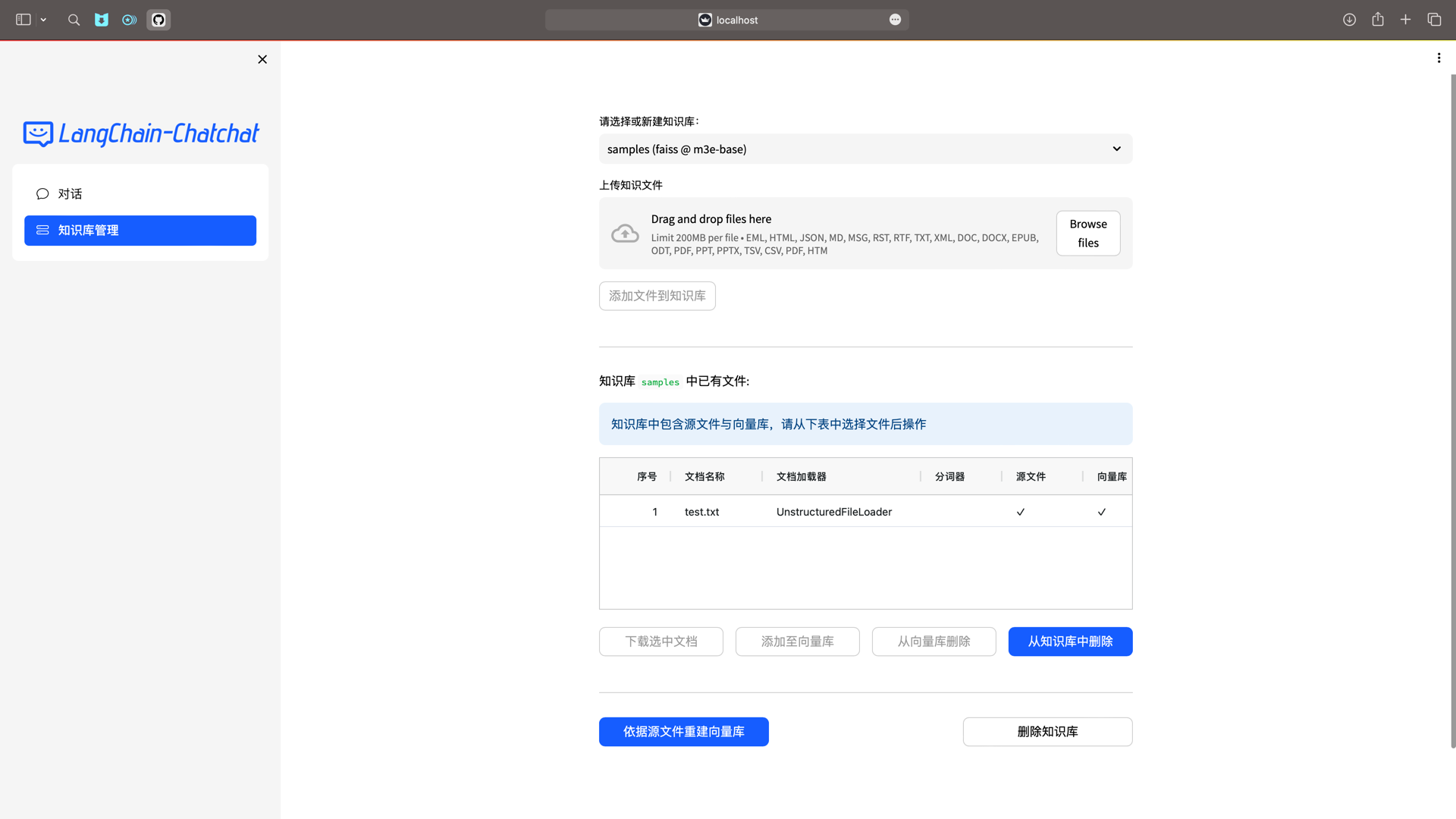
-
Web UI 知识库管理页面:


更新一键启动脚本 startup.py,一键启动所有 Fastchat 服务、API 服务、WebUI 服务,示例代码:
$ python startup.py --all-webui并可使用 Ctrl + C 直接关闭所有运行服务。
可选参数包括 --all-webui, --all-api, --llm-api, --controller, --openai-api,
--model-worker, --api, --webui,其中:
-
--all-webui为一键启动 WebUI 所有依赖服务; -
--all-api为一键启动 API 所有依赖服务; -
--llm-api为一键启动 Fastchat 所有依赖的 LLM 服务; -
--openai-api为仅启动 FastChat 的 controller 和 openai-api-server 服务; -
其他为单独服务启动选项。
若想指定非默认模型,需要用 --model-name 选项,示例:
$ python startup.py --all-webui --model-name Qwen-7B-Chat注意:
1. startup 脚本用多进程方式启动各模块的服务,可能会导致打印顺序问题,请等待全部服务发起后再调用,并根据默认或指定端口调用服务(默认 LLM API 服务端口:127.0.0.1:8888,默认 API 服务端口:127.0.0.1:7861,默认 WebUI 服务端口:本机IP:8501)
2.服务启动时间示设备不同而不同,约 3-10 分钟,如长时间没有启动请前往 ./logs目录下监控日志,定位问题。
参见 常见问题。
- Langchain 应用
- 本地数据接入
- 接入非结构化文档
- .md
- .txt
- .docx
- 结构化数据接入
- .csv
- .xlsx
- 分词及召回
- 接入不同类型 TextSplitter
- 优化依据中文标点符号设计的 ChineseTextSplitter
- 重新实现上下文拼接召回
- 本地网页接入
- SQL 接入
- 知识图谱/图数据库接入
- 接入非结构化文档
- 搜索引擎接入
- Bing 搜索
- DuckDuckGo 搜索
- Agent 实现
- 本地数据接入
- LLM 模型接入
- 支持通过调用 FastChat api 调用 llm
- 支持 ChatGLM API 等 LLM API 的接入
- Embedding 模型接入
- 支持调用 HuggingFace 中各开源 Emebdding 模型
- 支持 OpenAI Embedding API 等 Embedding API 的接入
- 基于 FastAPI 的 API 方式调用
- Web UI
- 基于 Streamlit 的 Web UI

🎉 langchain-ChatGLM 项目微信交流群,如果你也对本项目感兴趣,欢迎加入群聊参与讨论交流。