Speech synthesis model repo for galgame characters based on Tacotron2 , Hifigan and VITS. The repo is also used to publish precompiled GUI.
**Notice :**This project is only for AI study and hobby, because of the like of the characters to develop this project, no malicious purpose. If there is infringement, please submit issues, we will immediately remove the associated model.
这是一个存放基于Tacotron2,Hifigan,VITS,Diff-SVC的galgame角色语音合成的模型库的仓库。另外也用于发行编译后的推理GUI。
1.2.2-beta:
- 修复可能在部分设备上DLL缺失问题。
- 增加Diff-SVC支持
在开源协议的基础上还请遵守以下几点:
- (重要)不得将本软件、本仓库提供的预训练模型以及语音合成结果用于直接商业目的(例如:带有付费功能的QQ机器人,直接贩售,商业游戏等)对原作(模型数据来源作品)进行二次创作不包含在内。
- 二次创作请遵守原作用户协议,请勿制作会对原作造成不良影响的内容,另外请注明你的作品使用了语音合成,避免造成误会。
-
单模型可以放在任意位置,如果模型带有配置文件,请将它重命名为
config.json(diff-svc请重命名为config.yaml)并与模型放置在同一目录。(例如hifigan,vits模型,它们是带有配置文件的) -
**(TTS模型注意)**1.2.0版本后,你需要将你的模型使用的symbols按以下示例保存为
moetts.json并与模型放置在同一目录。(如果你不知道该如何进行此步骤,可以参考给出的预训练模型中的配置文件)GUI配置文件示例 (atri vits模型使用的配置)(文件名:moetts.json):
{ "symbols":["_", ",", ".", "!", "?", "-", "A", "E", "I", "N", "O", "Q", "U", "a", "b", "d", "e", "f", "g", "h", "i", "j", "k", "m", "n", "o", "p", "r", "s", "t", "u", "v", "w", "y", "z", "\u0283", "\u02a7", "\u2193", "\u2191", " "] }注:此配置不是训练模型使用的config.json,是用于指定您的模型训练时所使用的symbols,例如VITS,您可以在
vits/text/symbols.py中找到使用的symbols,并将它按以上格式保存为json。
文本一般是输入音素(日语在这里应该输入罗马音),但具体要看模型训练者的数据是怎么输入的。比如我的ATRI模型(Tacotron2版本)是输入无空格罗马音,标点符号只支持逗号句号。
注:v1.2.0后弃用了cleaners,Toolbox中提供了日语与中文的文本到发音转换,其他语言请自行clean后输入。

选择您的模型路径与输出目录,最后输入待合成文本,点击合成语音等待一会软件会将音频输出到输出目录/outpus.wav
注意事项:
- 首次合成需要加载模型,耗时较长,相同模型再次合成不会再次加载,直接合成。
- 如果切换模型,再次合成会重新加载。
- 如果修改cleaners与symbols,重新启动软件后才能生效。
- 软件为64位版本,不支持32位系统。
VITS特殊说明

- VITS-Single,VITS-Multi分别为单角色模型与多角色模型
- VITS-Multi中的原角色ID即待合成语音的角色ID,需要填入数字,目标角色ID为语音迁移功能的待迁移目标角色ID。
- 待迁移音频需要22050的采样率,16位,单声道。
-
Toolbox更新
- 加入中文g2p工具
- 内置了pyopenjtalk,g2p速度更快,解决gbk编码错误
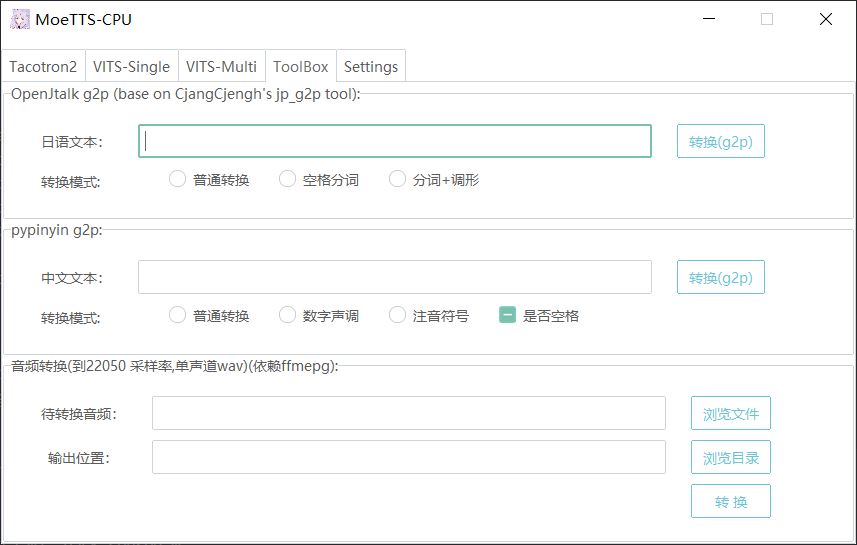
-
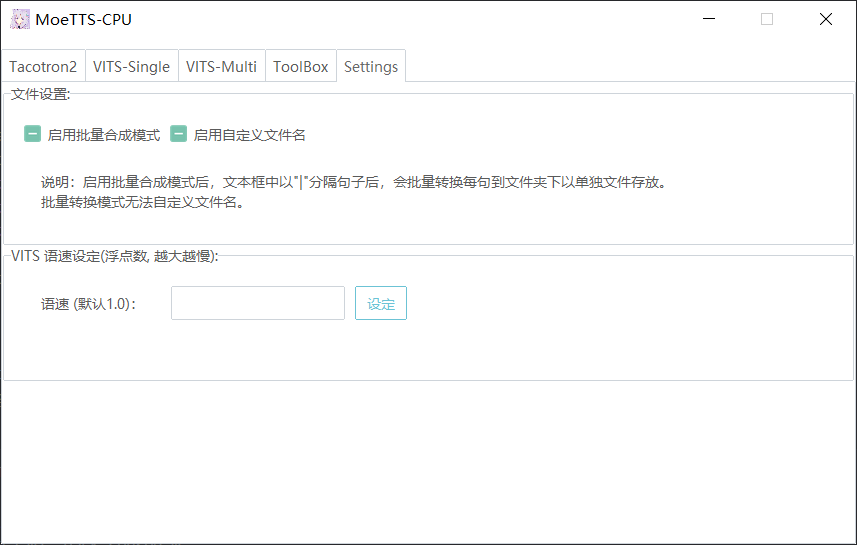
设置更新
- 添加批量合成模式
- 支持自定义文件名输出
- VITS模型支持语速调节
-
主题选择


此版本为测试版,用于测试一些新功能,稳定性仅简单测试(win10系统下测试),代码也可能不规范。

参数说明:
- 升降半音:默认为0,支持正负整数输入,单位为半音
- 启用Crepe:该选项可降噪音频,启用后CPU耗时较高,越为原音频时长8倍,建议合成最终版本再开启,干净的音频无需开启。
- 加速倍率:默认为20,耗时约1:3,预览可使用100,耗时约1:1(该设置会影响音频质量)
- 待转换音频:wav或ogg纯人声音频,转换后为模型角色音色。
Integrated into Huggingface Spaces using Gradio. Try it out
提交格式参考:
x. 模型名
描述:角色xxx的模型
模型输入:
下载地址:
配套Hifigan模型下载:选填
详细信息:选填
模型类型:
-
ATRI
描述:游戏 ATRI- My dear moments 的角色ATRI模型
模型输入:无空格罗马音,标点可保留英文逗号句号。例如:
tozendesu.koseinodesukara.模型下载:链接:https://pan.baidu.com/s/1itDhrhzw6uZYxB2238BzTQ?pwd=0z3u 提取码:0z3u
详细信息:从游戏中选择1300条语音训练,训练约600 Epoch,训练时罗马音使用Bing翻译API
模型类型:Tacotron2+Hifigan
-
ATRI-VITS
描述:游戏 ATRI- My dear moments 的角色ATRI模型
模型输入:带有分词与调形标注的罗马音,标点符号可使用
,.?!。可使用工具箱中的日语g2p(调形标注+ts替换)模型下载:
链接:https://pan.baidu.com/s/1_vhOx50OE5R4bE02ZMe9GA?pwd=9jo4 提取码:9jo4
详细信息:使用VITS训练约 900 Epoch。
模型类型:VITS
-
Galgame 13位角色
描述:来自多个galgame的13位角色的模型
模型输入:带有分词与调形标注的罗马音,标点符号可使用
,.?!。可使用工具箱中的日语g2p(调形标注+ts替换)模型下载(旧版200Epoch):
链接:https://pan.baidu.com/s/1fzpC_2YEISvahUzX1iYboA?pwd=yde8 提取码:yde8
模型下载(新版700Epoch):
https://pan.baidu.com/s/1anZ3eusmG8BVhrQQrvlkug?pwd=0i9r 提取码:0i9r
详细信息:
角色表:0 杏璃 1 杏铃 2 Apeiria 3 明日香 4 ATRI 5 艾拉 6 彩音 7 星奏 8 由依 9 冰织 10 真白 11 美绘瑠 12 二阶堂真红
模型类型:VITS多角色
-
姬野星奏Diff-svc
描述:姬野星奏的语音转换模型。(以下两个类似)
模型下载:链接:https://pan.baidu.com/s/1vc7lLpyAjUDCKI_PO5CR6w?pwd=wad5 提取码:wad5
模型类型:Diff-SVC
贡献者:MoeTTS(luoyily)
-
小鞠由依Diff-svc
模型下载:链接:https://pan.baidu.com/s/1WwluFplMLjVD9ZeF6qdAxQ?pwd=i4yc 提取码:i4yc
模型类型:Diff-SVC
贡献者:MoeTTS(luoyily)
-
ATRI Diff-svc
模型下载:链接:https://pan.baidu.com/s/1-jc9DSQp_fOv-kdc_4bkyQ?pwd=3jm3 提取码:3jm3
模型类型:Diff-SVC
贡献者:RiceCake(https://github.com/gak123)
-
Q:这个GUI能使用非官方Tacotron2或VITS训练的模型吗?
A:如果模型结构与推理方式没改过的话,只是数据处理不同,应该是没问题的。
-
Q:是否有命令行版本或HttpApi?
A:可能只会有Windows版。
-
Q:如何获得完整代码?
A:完整代码请参见dev或其它分支,main分支用于发布模型与GUI。
-
Q:如何训练自己的模型?
A:本仓库不提供自训练支持,请到本项目使用到的各个原项目中查看帮助。
欢迎分享你的预训练模型,由于模型较大,暂时不打算存放在GitHub,可以拉取该项目后将你的模型下载地址以及信息写在Readme的模型下载部分中。提交PR即可。
如果有任何优化建议或者BUG可以提issue。
如您希望为项目追加新功能并合并到dev分支,请先查看Projects页面,避免PR冲突。
- ShiroDoMain:1.0.0 CLI版本开发
- menproject:1.0.0 版本英语自述文件翻译
- CjangCjengh:提供编译的g2p工具以及适用于日语调形标注的符号文件。
- skytnt: 提供了hugging face 在线 demo
hifi-gan: https://github.com/jik876/hifi-gan
Tacotron2: https://github.com/NVIDIA/tacotron2
VITS:https://github.com/jaywalnut310/vits
diff-svc:https://github.com/prophesier/diff-svc
DiffSinger:https://github.com/MoonInTheRiver/DiffSinger
DiffSinger(openvpi):https://github.com/openvpi/DiffSinger
注:beta版本中的diff-svc打包了diff singer原仓库的声码器与pe权重。