数据来源于爬取自https://www.zimuku.cn/网的字幕以及https://github.com/halxp1/chaotbot_corpus_Chinese上的部分语料,样例如下:
Q:有沒有戰神阿瑞斯的八卦?
A:爵士就是阿瑞斯 男主角最後死了
Q:為什麼PTT這麼多人看棒球
A:肥宅才看棒球 系壘一堆胖子
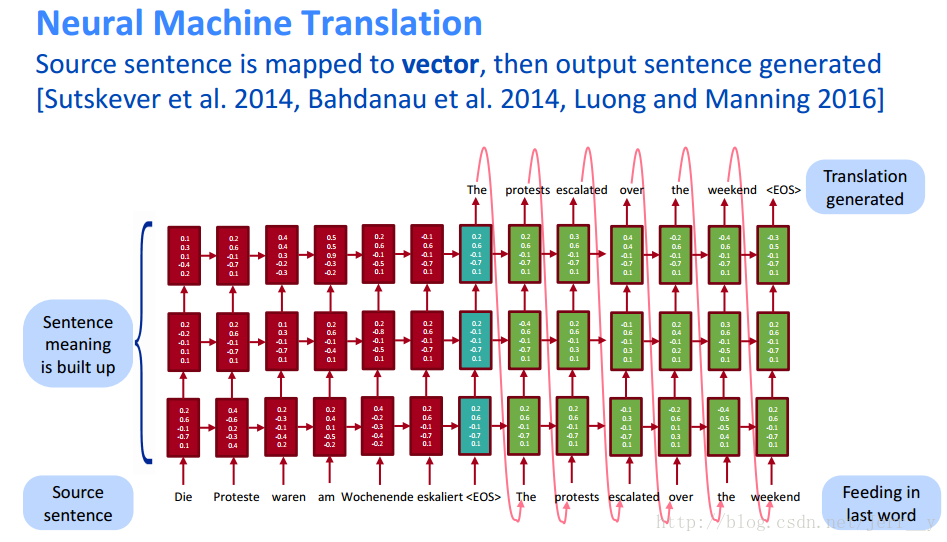
模型来源于经典的神经翻译机(Bahdanau et al., 2014. Neural Machine Translation by Jointly Learning to Align and Translate),如图:
在编码器和解码器上均采用三层的LSTM,并结合Beam Search(约束的宽度取5),所得到的网络结构如下所示:
Layer (type) Output Shape Param Connected to
==================================================================================================
Encoder_Input (InputLayer) (None, 100) 0
__________________________________________________________________________________________________
embedding_11 (Embedding) (None, 100, 300) 399000 Encoder_Input[0][0]
__________________________________________________________________________________________________
Decoder_Input (InputLayer) (10, None, 1330) 0
__________________________________________________________________________________________________
Encoder_LSTM_1 (CuDNNLSTM) [(None, 100, 128), ( 220160 embedding_11[0][0]
__________________________________________________________________________________________________
Decoder_LSTM_1 (CuDNNLSTM) [(10, None, 128), (1 747520 Decoder_Input[0][0]
Encoder_LSTM_1[0][1]
Encoder_LSTM_1[0][2]
__________________________________________________________________________________________________
Encoder_LSTM_2 (CuDNNLSTM) [(None, 100, 128), ( 132096 Encoder_LSTM_1[0][0]
__________________________________________________________________________________________________
Decoder_LSTM_2 (CuDNNLSTM) [(10, None, 128), (1 132096 Decoder_LSTM_1[0][0]
Encoder_LSTM_2[0][1]
Encoder_LSTM_2[0][2]
__________________________________________________________________________________________________
Encoder_LSTM_3 (CuDNNLSTM) [(None, 100, 128), ( 132096 Encoder_LSTM_2[0][0]
__________________________________________________________________________________________________
Decoder_LSTM_3 (CuDNNLSTM) [(10, None, 128), (1 132096 Decoder_LSTM_2[0][0]
Encoder_LSTM_3[0][1]
Encoder_LSTM_3[0][2]
__________________________________________________________________________________________________
Decoder_hidden_1 (Dense) (10, None, 128) 16512 Decoder_LSTM_3[0][0]
__________________________________________________________________________________________________
Decoder_hidden_2 (Dense) (10, None, 64) 8256 Decoder_hidden_1[0][0]
__________________________________________________________________________________________________
dense_5 (Dense) (10, None, 1330) 86450 Decoder_hidden_2[0][0]
==================================================================================================
Total params: 2,006,282
Trainable params: 2,006,282
Non-trainable params: 0
__________________________________________________________________________________________________
Epoch 1/10
450/450 [==============================] - 7s 16ms/step - loss: 2.3624 - val_loss: 0.3561
Epoch 2/10
450/450 [==============================] - 5s 11ms/step - loss: 0.3647 - val_loss: 0.3437
Epoch 3/10
450/450 [==============================] - 5s 11ms/step - loss: 0.3541 - val_loss: 0.3508
Epoch 4/10
450/450 [==============================] - 5s 11ms/step - loss: 0.3476 - val_loss: 0.3599
Epoch 5/10
450/450 [==============================] - 5s 11ms/step - loss: 0.3451 - val_loss: 0.3625
Epoch 6/10
450/450 [==============================] - 5s 11ms/step - loss: 0.3434 - val_loss: 0.3759
Epoch 7/10
450/450 [==============================] - 5s 11ms/step - loss: 0.3287 - val_loss: 0.3655
Epoch 8/10
450/450 [==============================] - 5s 11ms/step - loss: 0.3151 - val_loss: 0.3732
Epoch 9/10
450/450 [==============================] - 5s 11ms/step - loss: 0.3076 - val_loss: 0.3780
Epoch 10/10
450/450 [==============================] - 5s 12ms/step - loss: 0.3006 - val_loss: 0.3887
<tensorflow.python.keras.callbacks.History at 0x5e6fdef0>