Transformer
This is a pytorch implementation of the transformer model. If you'd like to understand the model, or any of the code better, please refer to my tutorial.
Using the Europarl dataset plus the dataset in the data folder, I was able to achieve a BLEU score of 0.39 on the test set (current SOTA is around 0.42), after 4/5 days of training on a single 8gb GPU. For more results see the tutorial again.
Train the model immediately on FloydHub

Launch a FloydHub Workspace to start training this model with 1 click. Workspace is a GPU-enabled cloud IDE for machine learning. It provides a fully configured environment so you can start hacking right away, without worrying about dependencies, data sets, etc.
Once you've started the workspace, run the 'start_here' notebook or type 'floyd run' into the workspace terminal. This will begin to train the model on the sample dataset.
Usage
Two text files containing parallel sentences (seperated by '\n' characters) in two languages are required to train the model. See an example of this in the data/ folder (french.txt and english.txt).
To begin training, run this code:
python train.py -src_data path/lang1.txt -trg_data path/lang2.txt -src_lang lang1 -trg_lang lang2
The spacy tokenizer is used to tokenize the text, hence only languages supported by spacy are supported by this program. The languages supported by Spacy and their codes are:
English : 'en'
French : 'fr'
Portugese : 'pt'
Italian : 'it'
Dutch : 'nl'
Spanish : 'es'
German : 'de'
For example, to train tan English->French translator on the datasets provided in the data folder, you would run the following:
python train.py -src_data data/english.txt -trg_data data/french.txt -src_lang en -trg_lang fr
Additional parameters:
-epochs : how many epochs to train data for (default=2)
-batch_size : measured as number of tokens fed to model in each iteration (default=1500)
-n_layers : how many layers to have in Transformer model (default=6)
-heads : how many heads to split into for multi-headed attention (default=8)
-no_cuda : adding this will disable cuda, and run model on cpu
-SGDR : adding this will implement stochastic gradient descent with restarts, using cosine annealing
-d_model : dimension of embedding vector and layers (default=512)
-dropout' : decide how big dropout will be (default=0.1)
-printevery : how many iterations run before printing (default=100)
-lr : learning rate (default=0.0001)
-load_weights : if loading pretrained weights, put path to folder where previous weights and pickles were saved
-max_strlen : sentenced with more words will not be included in dataset (default=80)
-checkpoint : enter a number of minutes. Model's weights will then be saved every this many minutes to folder 'weights/'
Training and Translating
python train.py -src_data data/english.txt -trg_data data/french.txt -src_lang en -trg_lang fr -epochs 10
This code gave the following results on a K100 GPU with 8bg RAM:

After saving the results to folder 'weights', the model can then be tested:
python translate.py -load_weights weights
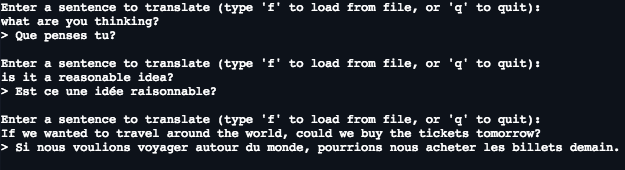
So with a small dataset of 150,000 sentences and 1 hour of training, already some quite good results...
Features still to add
- create validation set and get validation scores each epoch
- function to show translations of sentences from training and validation sets