
🌐️ English | 中文
TuGraph Analytics (alias: GeaFlow) is the fastest open-source OLAP graph database developed by Ant Group. It supports core capabilities such as trillion-level graph storage, hybrid graph and table processing, real-time graph computation, and interactive graph analysis. Currently, it is widely used in scenarios such as data warehousing acceleration, financial risk control, knowledge graph, and social networks.
For more information about GeaFlow: GeaFlow Introduction
For GeaFlow design paper: GeaFlow: A Graph Extended and Accelerated Dataflow System
- Distributed streaming graph computation
- Hybrid graph and table processing (SQL+GQL)
- Unified stream/batch/graph computation
- Trillion-level graph-native storage
- Interactive graph analytics
- High availability and exactly once semantics
- High-level API operator development
- UDF/graph-algorithms/connector support
- One-stop graph development platform
- Cloud-native deployment
- Prepare Git、JDK8、Maven、Docker environment。
- Download Code:
git clone https://github.com/TuGraph-family/tugraph-analytics - Build Project:
mvn clean install -DskipTests - Test Job:
./bin/gql_submit.sh --gql geaflow/geaflow-examples/gql/loop_detection.sql - Build Image:
./build.sh --all - Start Container:
docker run -d --name geaflow-console -p 8888:8888 geaflow-console:0.1
For more details:Quick Start。
GeaFlow supports two sets of programming interfaces: DSL and API. You can develop streaming graph computing jobs using GeaFlow's SQL extension language SQL+ISO/GQL or use GeaFlow's high-level API programming interface to develop applications in Java.
- DSL application development: DSL Application Development
- API application development: API Application Development
Compared with traditional stream processing engines such as Flink and Storm, which use tables as their data model for real-time processing, GeaFlow's graph-based data model has significant performance advantages when handling join relationship operations, especially complex multi-hops relationship operations like those involving 3 or more hops of join and complex loop searches.
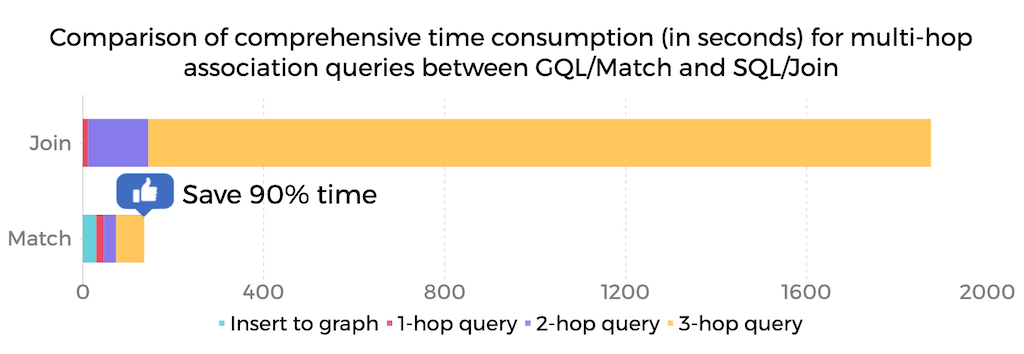
Why using graphs for relational operations is more appealing than table joins?
Association Analysis Demo Based on GQL:
--GQL Style
Match (s:student)-[sc:selectCource]->(c:cource)
Return c.name
;
Association Analysis Demo Based on SQL:
--SQL Style
SELECT c.name
FROM course c JOIN selectCourse sc
ON c.id = sc.targetId
JOIN student s ON sc.srcId = s.id
;
Thank you very much for contributing to GeaFlow, whether bug reporting, documentation improvement, or major feature development, we warmly welcome all contributions.
For more information: Contribution.
 |
 |
 |
 |
 |
 |
You can contact us through the following methods:

If you are interested in GeaFlow, please give our project a ⭐️ .
Thanks to some outstanding open-source projects in the industry, such as Apache Flink, Apache Spark, and Apache Calcite, some modules of GeaFlow were developed with their references. We would like to express our special gratitude for their contributions.