- Computer Vision Datasets
- Autonomous Driving/ADAS
- Argoverse 2
- The Cityscapes Dataset
- All-In-One Drive, A Large-Scale Comprehensive Perception Dataset with High-Density Long-Range Point Clouds
- DAIR-V2X, The world's first vehicle-road collaboration dataset release
- Dense Depth for Autonomous Driving - DDAD dataset
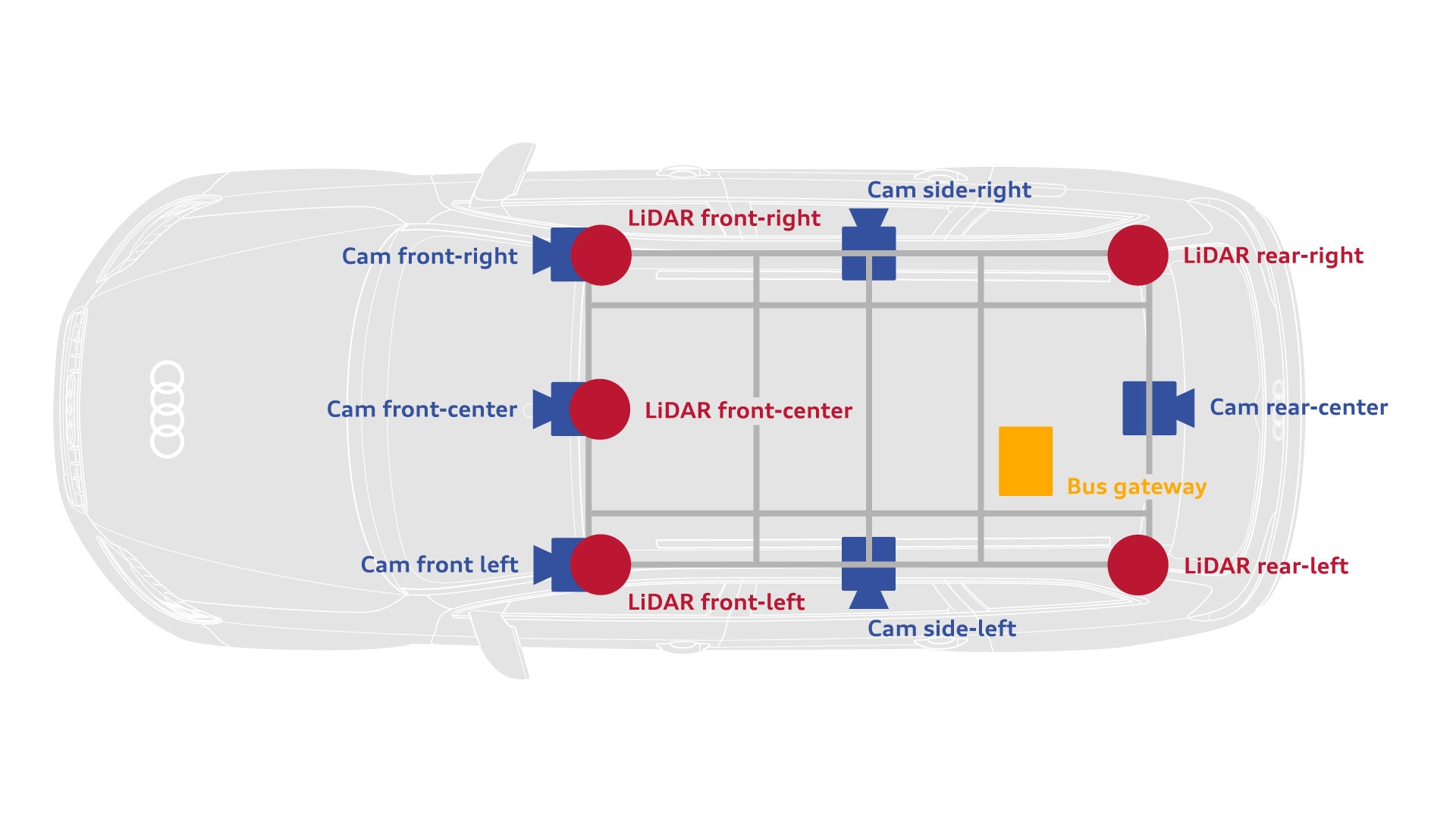
- Audi Autonomous Driving Dataset (A2D2)
- Thermal Imaging
- Motion Planning
- Synthetic Dataset
- Face
- Human
- Video Object Segmentation
- Dataset Search Engine
- Autonomous Driving/ADAS
| Argoverse 2 Sensor Dataset | Argoverse 2 Motion Forecasting Dataset | Argoverse 2 Lidar Dataset | Argoverse 2 Map Change Dataset |
|---|---|---|---|
| 1,000 3D annotated scenarios with lidar, stereo imagery, and ring camera imagery. This dataset improves upon the Argoverse 1 3D Tracking dataset. |
250,000 scenarios with trajectory data for many object types. This dataset improves upon the Argoverse 1 Motion Forecasting Dataset. |
20,000 unannotated lidar sequences. | 1,000 scenarios, 200 of which depict real-world HD map changes |
- 5000 images with high quality annotations
- 20000 images with coarse annotations
- 50 different cities
All-In-One Drive, A Large-Scale Comprehensive Perception Dataset with High-Density Long-Range Point Clouds
- Full sensor suite (3x LiDAR, 1x SPAD-LiDAR, 4x Radar, 5x RGB, 5x depth camera, IMU, GPS)
- 100 sequences with 1000 frames (100s) each
- 500,000 annotated images for 5 camera viewpoints
- 100,000 annotated frames for each LiDAR/Radar sensor
- 26M 2D/3D bounding boxes precisely annotated for 4 object classes (car, cyclist, motorcycle, pedestrian)
-

DAIR-V2X, The world's first vehicle-road collaboration dataset release
-
Totally 71254 LiDAR frames and 71254 Camera images:
DAIR-V2X Cooperative Dataset
(DAIR-V2X-C)DAIR-V2X Infrastructure Dataset
(DAIR-V2X-I)DAIR-V2X Vehicle Dataset
(DAIR-V2X-V)38845 LiDAR frames
38845 Camera images10084 LiDAR frames
10084 Camera images22325 LiDAR frames
22325 Camera images -

- The training and validation scenes are 5 or 10 seconds long and consist of 50 or 100 samples with corresponding Luminar-H2 pointcloud and six image frames including intrinsic and extrinsic calibration.
- The training set contains 150 scenes with a total of 12650 individual samples (75900 RGB images), and the validation set contains 50 scenes with a total of 3950 samples (23700 RGB images).
- train+val 257 GB
-


- The dataset features 2D semantic segmentation, 3D point clouds, 3D bounding boxes, and vehicle bus data
- Sensor setup:
| Five LiDAR sensors | Front centre camera | Surround cameras (5x) |
|---|---|---|
|
|
|
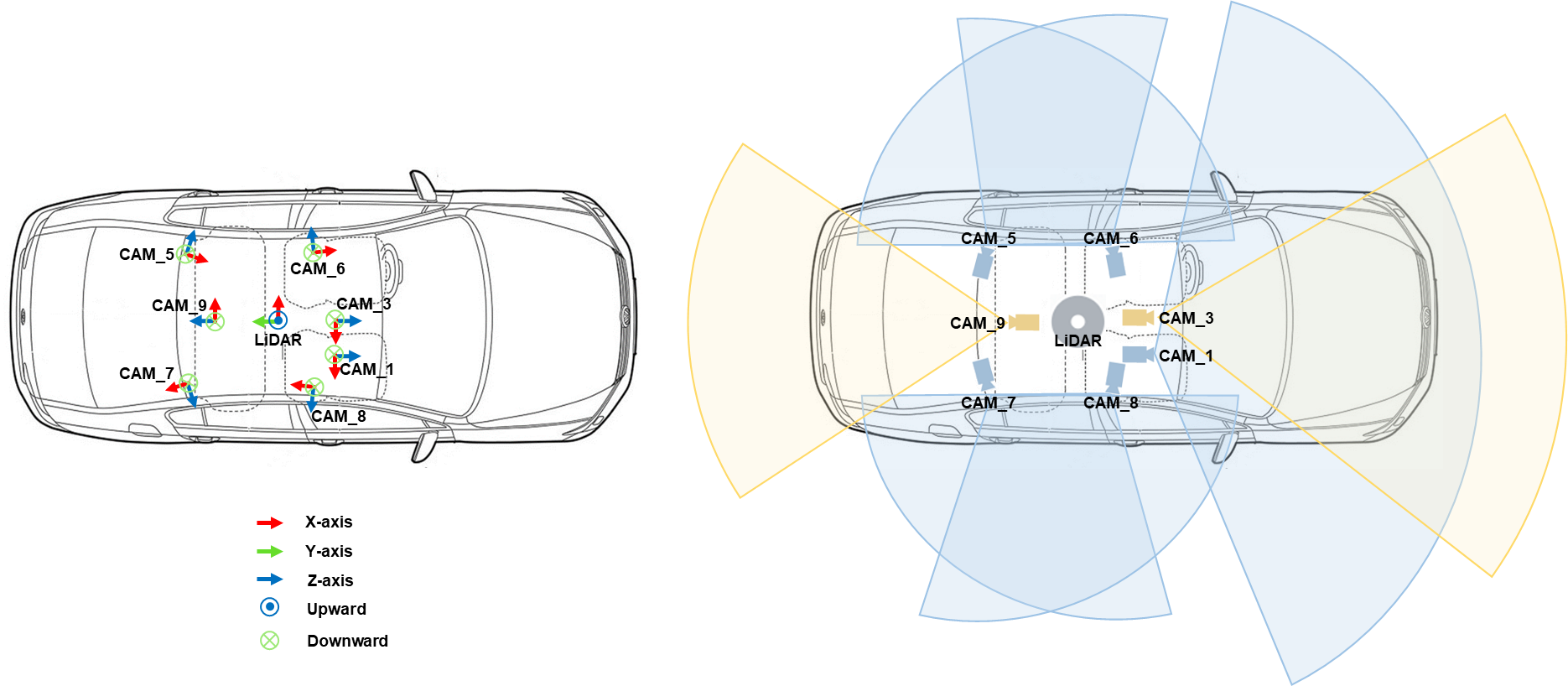
The ONCE dataset is a large-scale autonomous driving dataset with 2D&3D object annotations.
- 1 Million LiDAR frames, 7 Million camera images
- 200 km² driving regions, 144 driving hours
- 15k fully annotated scenes with 5 classes (Car, Bus, Truck, Pedestrian, Cyclist)
- Diverse environments (day/night, sunny/rainy, urban/suburban areas)
- A total of 26,442 fully annotated frames with 520,000 bounding box annotations across 15 different object categories
- 9,711 thermal and 9,233 RGB training/validation images with a suggested training/validation split. Includes 16-bit pre-AGC frames
- 7,498 total video frames recorded at 24Hz. 1:1 match between thermal and visible frames. Includes 16-bit pre-AGC frames
-


- SYNTHIA consists of a collection of photo-realistic frames rendered from a virtual city and comes with precise pixel-level semantic annotations for 13 classes: misc, sky, building, road, sidewalk, fence, vegetation, pole, car, sign, pedestrian, cyclist, lane-marking.
-

- Crowdhuman
- Highlights: occluded video instances
- OVIS consists of 296k high-quality instance masks from 25 semantic categories, where object occlusions usually occur.
- CVPR 2022: Large-scale Video Panoptic Segmentation in the Wild: A Benchmark
-

